

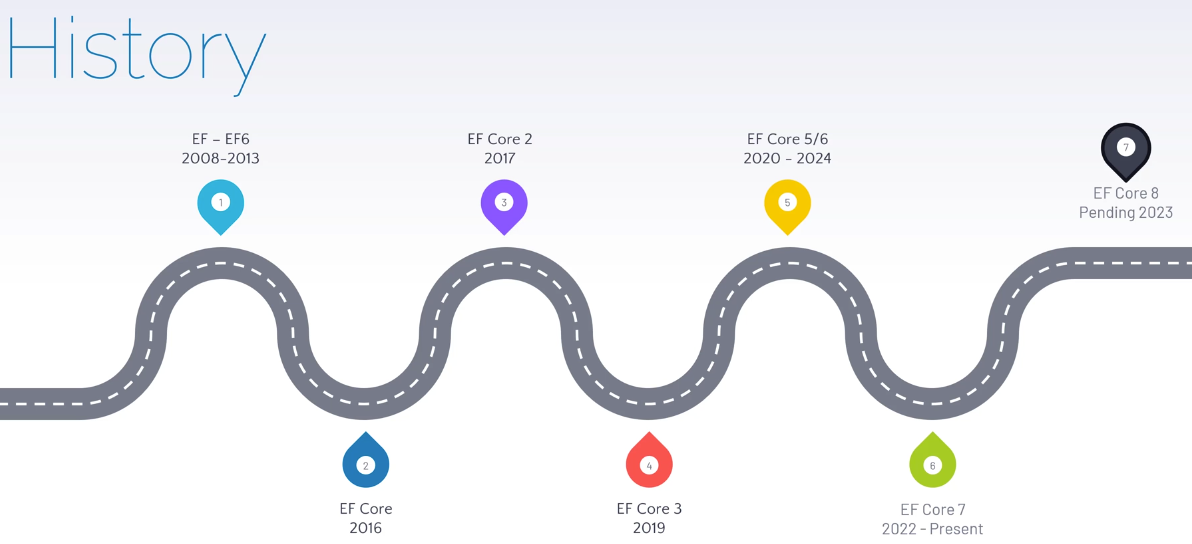
 #linq
#linq



وقتی که Id میزاریم به صورت اتوماتیک میشه PK
وقتی که string میزاریم میشه var char حالا از مدوم نوعش رو در دیتابیس تعیین میکنیم
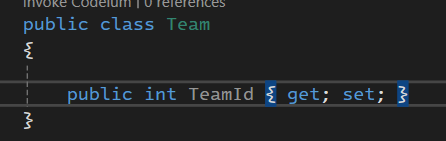 وقتی که اسم جدول رو میزاریم و بعد id میزاریم اون هم یه convention هست برای PK
وقتی که اسم جدول رو میزاریم و بعد id میزاریم اون هم یه convention هست برای PK
وقتی که میخوایم کلاس پایه بسازیم اون رو از نوع abstract میسازیم ، وقتی که abstract باشه دیگه نمیشه ازش instansiate کرد یا یک نمونه ساخت ، ما اون رو میسازیم که ازش ارث بری کنیم برای کلاس های دیگه

onConfiguring #onModelCreating
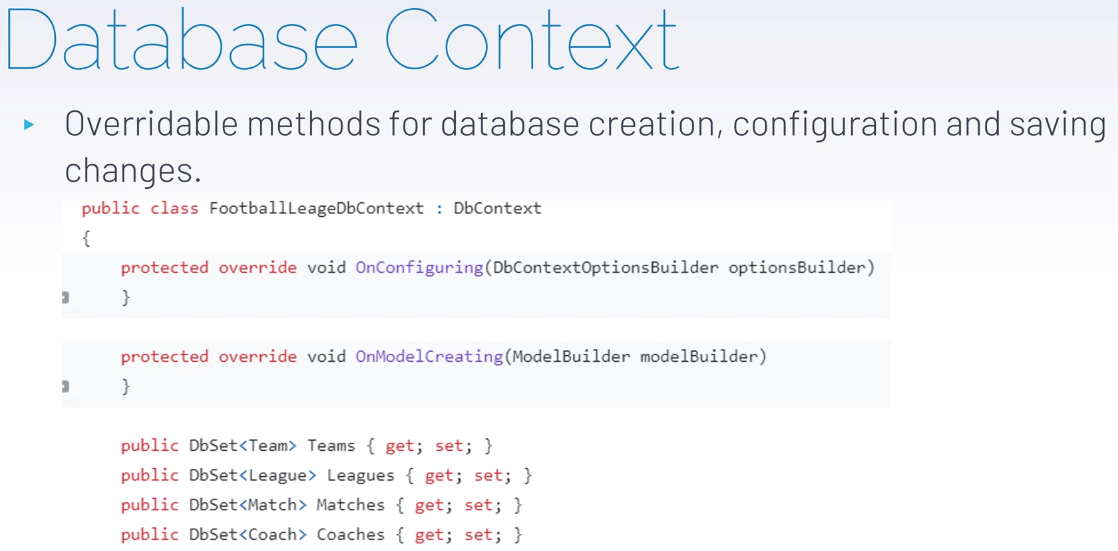
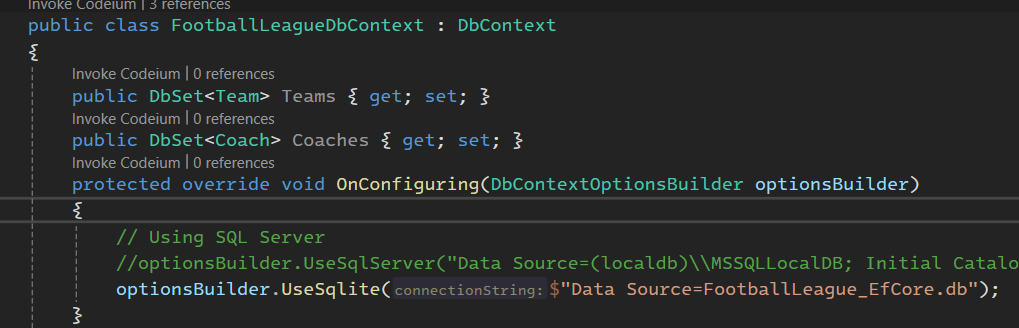
خوب اینجا وقتی که داریم از db context ارث بری میکنیم یعنی یه کلاس معمولی رو تبدیل کردیم به کلاس ارتباطی که با دیتابیس در ارتباط هستش و قراره به جدول ها دسترسی داشته باشه
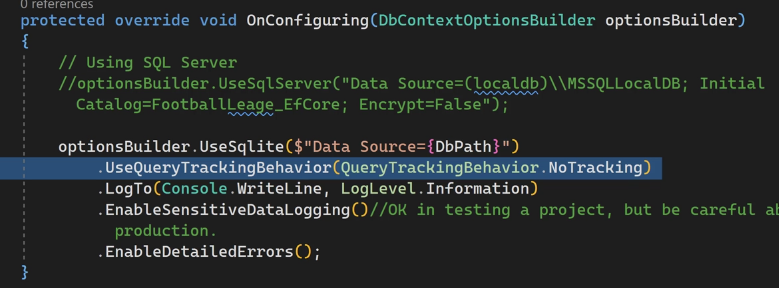
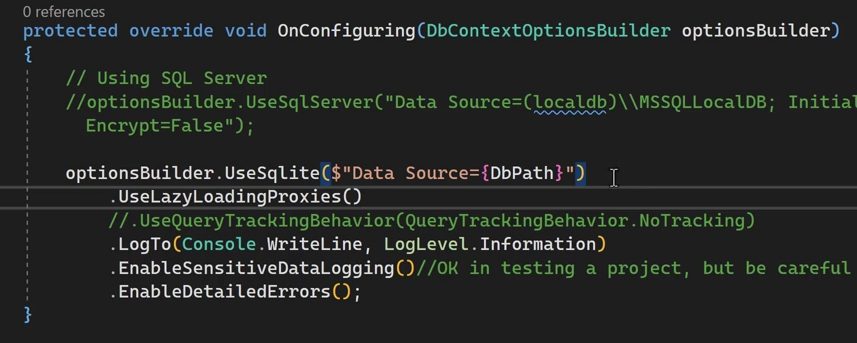
در on configuring یه سری تنظیمات دیفالت هستش که ما میتونیم روش override کنیم
در on model creating خوب اینجا وقتی که دیتابیس ساخته شد میاد نگاه میکنه که روی field ها باید بیاد چی کار کنه یا چه sql رو اجرا کنه
در قسمت آخر هم داریم جدول های دیتابیس رو میسازیم
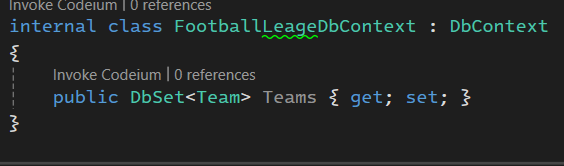
خوب ما از مجموع team ها در جدول ها Teams رو داریم برای همین این مدلی اسم گذاری کردیم
این جا هم اون چیزهایی که میتونیم override کنیم رو میبینیم :
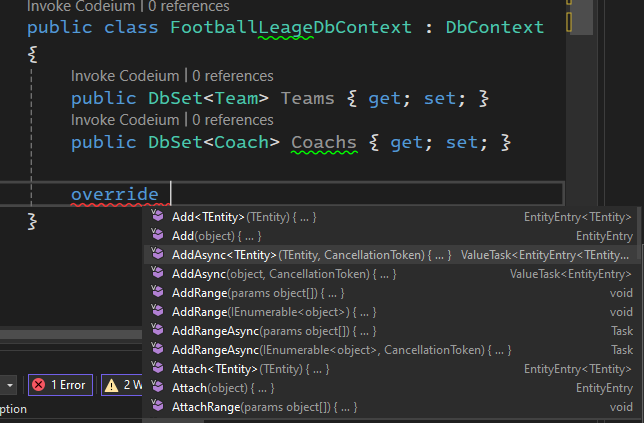

connectionString
 از on configuration برای set کردن connection strings استفاده میکنیم ولی بهترین راهش استفاده از secret هستش
از on configuration برای set کردن connection strings استفاده میکنیم ولی بهترین راهش استفاده از secret هستش
 خوب توی on configuring میایم و base.onConfiguration رو پاک میکنیم چون داره تنظیمات اولیه رو تنظیم میکنه
#base_onConfiguration
#onConfiguring
خوب توی on configuring میایم و base.onConfiguration رو پاک میکنیم چون داره تنظیمات اولیه رو تنظیم میکنه
#base_onConfiguration
#onConfiguring
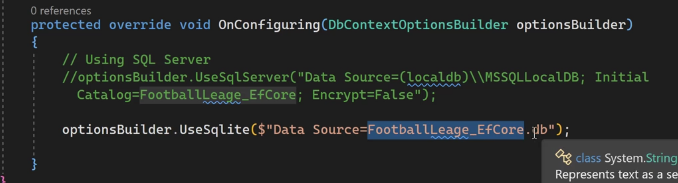
وقتی که داریم از VS استفاده میکنیم به دیتابیس داخلی دسترسی داریم :
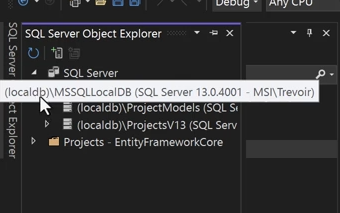

اینجا از \ استفاده کردیم که داریم اونجا آدرس رو تعیین میکنیم خوب initial catalog اسم دیتابیسه #connectionString


توی migration ها میاد چیزی هست رو با تغییراتی که ایجاد شده مقایسه میکنه و فایل تغییرات رو آماده و تولید میکنه مثلا وقتی که دیتابیس نداریم اولین miration اینه که دیتابیس رو درست کنیم مثلا بعدش چیزی رو تغییر میدیم مثل این که یه فیلد رو اضافه میکنه میره و با ورژن قبلی چک میکنه و فایل جدید رو برای این تغییرات درست میکنه
خوب up یعنی تغییراتی که باید به وجود بیاد و down هم یعنی چیزهایی که باید undo بشن
خوب حالا هر تغییراتی هم که انجام میشه ef میاد یه جدول درست میکنه به اسم histoty و این تغییرات رو توش ذخیره میکنه
#EntityFrameworkCore_tool
#EntityFrameworkCore_Design

 وقتی که این کار رو کردیم توی فایل csproj فایل console مون
وقتی که این کار رو کردیم توی فایل csproj فایل console مون
 این اضافه میشه
این اضافه میشه
 دقت : کد بالا در قسمت db path مشکل داره و اون رو در بخش های جلوتر درست شده
دقت:
دقت : کد بالا در قسمت db path مشکل داره و اون رو در بخش های جلوتر درست شده
دقت:
 ارور :
ارور :

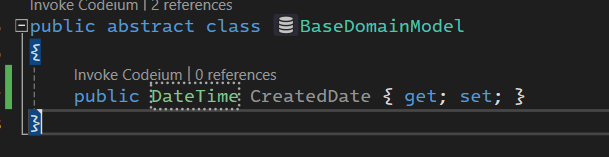
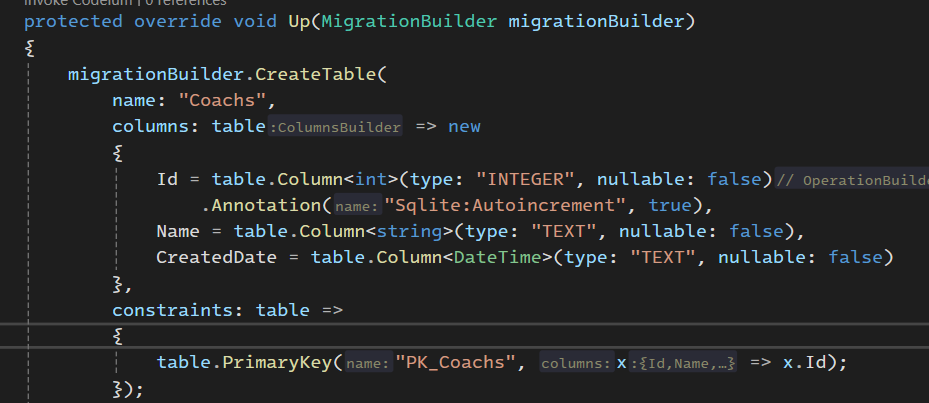 خوب اینجا نوشته که id از نوع auto increment تعریف شده
و قسمت name از نوع text تعیین شده در صورتی که این در sqllite هستش که اینوطریه و در sql server میشه n varchar max
و بعد هم اومده کلید اصلی رو تعیین کرده
خوب اینجا نوشته که id از نوع auto increment تعریف شده
و قسمت name از نوع text تعیین شده در صورتی که این در sqllite هستش که اینوطریه و در sql server میشه n varchar max
و بعد هم اومده کلید اصلی رو تعیین کرده
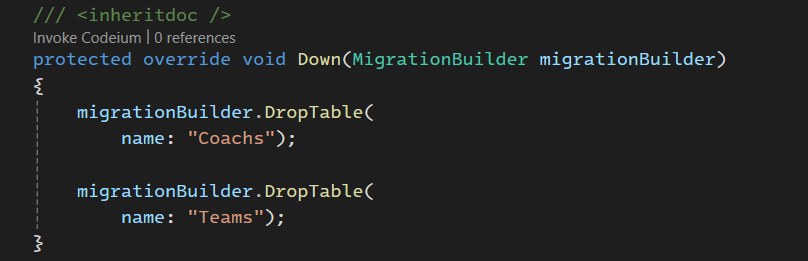 اینجا نوشته شده که در صورتی که بخوایم undo کنیم چه اتفاقی قراره بیوفته و نوشته که این دو تا جدول رو drop میکنه
اینجا نوشته شده که در صورتی که بخوایم undo کنیم چه اتفاقی قراره بیوفته و نوشته که این دو تا جدول رو drop میکنه
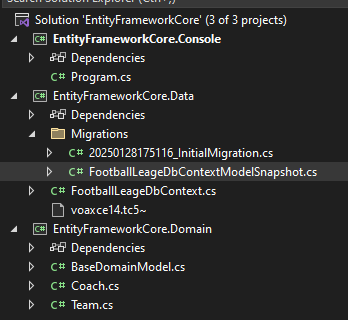
خوب در همین زمان که فایل migration درست میشه یه فایل snapshot هم درست میشه که میگه توی این تایم دیتابیس این شکلیه
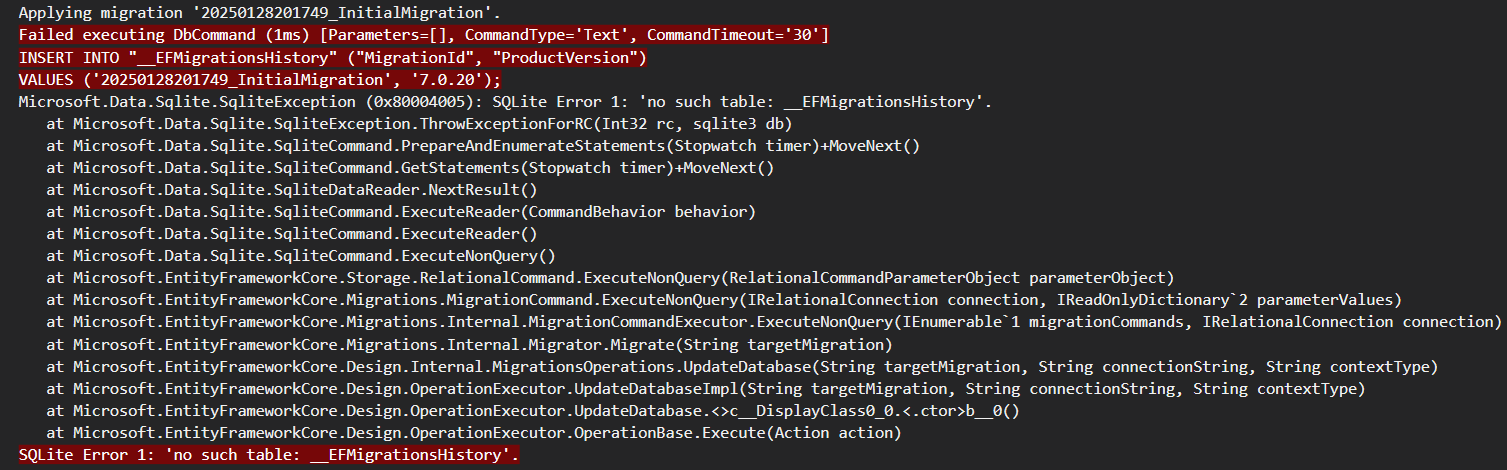


ارور حل میشه

خوب حالا وقتی که دیتابیس از قبل باشه و بخوایم باهاش با ef کار کنیم باید از چیزی به اسم scaffolding استفاده کنیم و مهندسی معکوسی رو انجام بدیم یعنی بیایم از روی ساختار دیتابیس رو بگیریم و بعد بیایم روش کارهایی رو که میخوایم رو انجام بدیم البته این روش داستانی که داره اینه که هر سری بخوایم از دیتا بیس و ef توی این حالت بخوایم استفاده کنیم باید از scaffolding استفاده کنیم #scaffolding
خوب توی این حالت وقتی که بخوایم هر بار scaffolding رو اجرا کنیم میگه که این چیزی که میخوای همین الان هستش که ما این رو میایم با dash force درستش میکنیم
 اینجا توی کنسول باید برای آدرس از یک \ استفاده کنیم
اینجا توی کنسول باید برای آدرس از یک \ استفاده کنیم

 خوب آخر اون کامند که داریم مینویسیم اینه که تعیین کنیم از چه مدل دیتابیسی رو باید مهندسی معکوس روش انجام بدیم و اینجا نوشتیم sql server
خوب آخر اون کامند که داریم مینویسیم اینه که تعیین کنیم از چه مدل دیتابیسی رو باید مهندسی معکوس روش انجام بدیم و اینجا نوشتیم sql server


خوب از اونجا که زدیم -contextDir میخوایم تعریف کنیم که مهندسی معکوسی زدیم این اطلاعاتی که بدست آوردیم رو کجا بریزیم که براش تعریف میکنیم که کجا
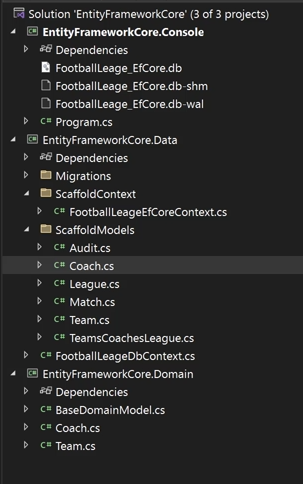
 باید برای این که بخوایم دوباره اجرا کنیم این کامند رو از dash force استفاده کنیم
باید برای این که بخوایم دوباره اجرا کنیم این کامند رو از dash force استفاده کنیم
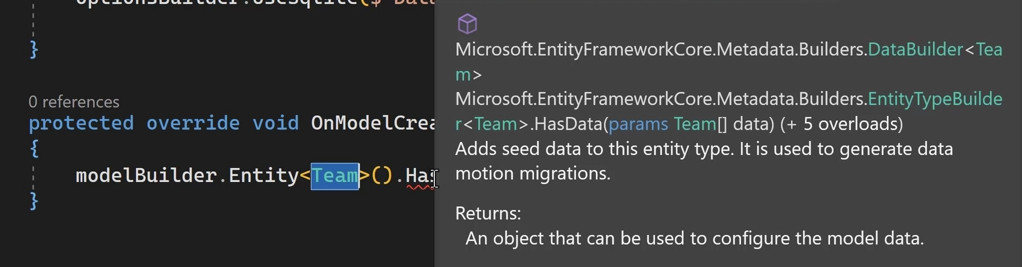
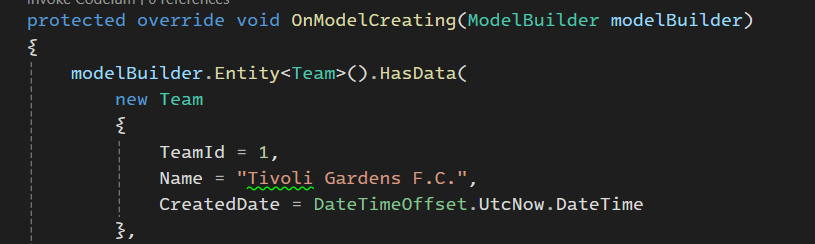
توی این قسمت میبینیم که وقتی که از has data میخوایم استفاده کنیم خودش توی توضیحات نوشته اشاره داره میکنه به Array از Team ها #addMigration
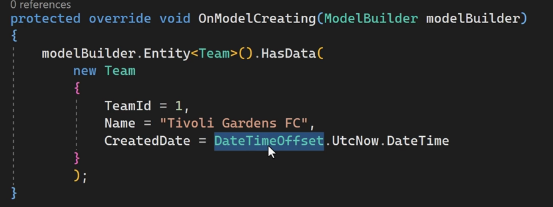 وقتی که داریم Data seed میکنیم باید id اش رو بهش بدیم یعنی pk اش رو خودمون دستی تعیین کنیم
وقتی که داریم Data seed میکنیم باید id اش رو بهش بدیم یعنی pk اش رو خودمون دستی تعیین کنیم
 وقتی که بیش از یکی دیتابیس و Context داریم باید بیایم موقع migration مشخصا اون رو بنویسیم
وقتی که بیش از یکی دیتابیس و Context داریم باید بیایم موقع migration مشخصا اون رو بنویسیم
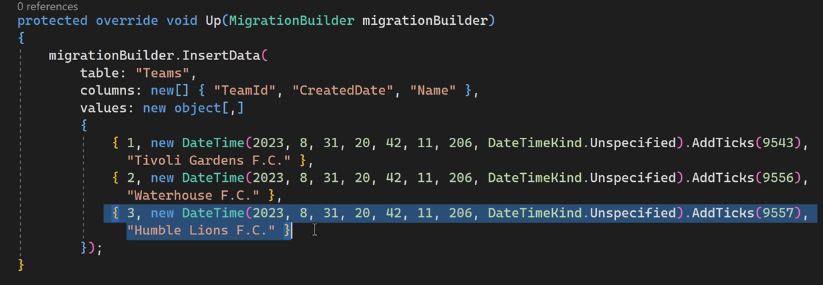
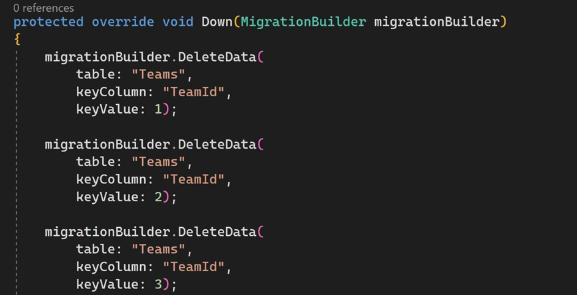
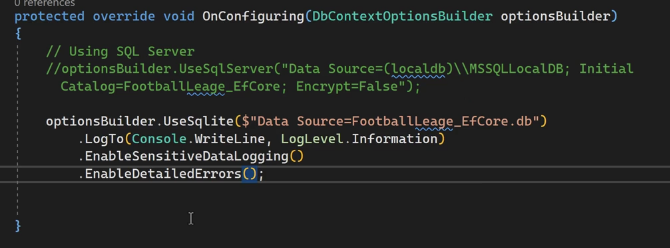 #EnableSensitiveDataLogging
#EnableDetailedError
خوب برای مباحث آموزشی میایم از enable sensitive Data loggin, enable detailed errors استفاده میکنیم چون وقتکه ازشون استفاده میکنیم در مورد sensetive data میاد و دیتاهای حساس مثل password رو نمایش میده که مناسب نیست و فقط برای تست و مباحث آموزش استفاده میشه
#EnableSensitiveDataLogging
#EnableDetailedError
خوب برای مباحث آموزشی میایم از enable sensitive Data loggin, enable detailed errors استفاده میکنیم چون وقتکه ازشون استفاده میکنیم در مورد sensetive data میاد و دیتاهای حساس مثل password رو نمایش میده که مناسب نیست و فقط برای تست و مباحث آموزش استفاده میشه
خوب ما وقتی که مسیر دیتابیس رو دادیم ولی باید بیایم توی جایی که console app هستش دیتابیس رو درست کنیم چون که cosnole app میاد اولین جایی که میگرده همون جاست و اگر نباشه ارور میده
 خوب اینجا داره در مورد local application data داره میگه که میشه همون آدرس جایی که پروژه هستش
خوب اینجا داره در مورد local application data داره میگه که میشه همون آدرس جایی که پروژه هستش
connectionString #specialFolder #localApplication #enviroment #path #combine
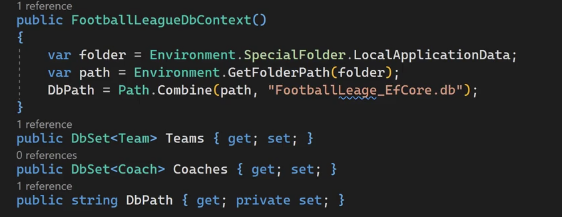 اول میایم آدرس جایی که پروژه هستش رو میگیریم و بعدش میایم اون آدرس رو با FootballLeague_efcore ترکیبش میکنیم برای ساخت و بعدش دسترسی به دیتابیس
اول میایم آدرس جایی که پروژه هستش رو میگیریم و بعدش میایم اون آدرس رو با FootballLeague_efcore ترکیبش میکنیم برای ساخت و بعدش دسترسی به دیتابیس
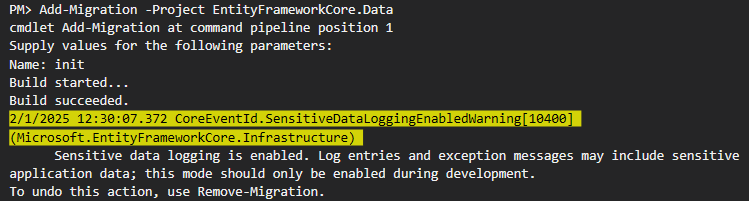 برای ساخت دیتابیس میایم اول پروژه cosole رو به عنوان start up در نظر میگیریم و بعدش با تعیین کردن پروژه ای که داخلش db context مون هستش و این دو تا بهم وصل هستند رو تعیین میکنیم و بعد migration رو انجام میدیم به این command دقت کنیم چون باعث ارور و ساخته نشدن migration میشه اگر اشتباه بزنیم مثل این ارور پایین
برای ساخت دیتابیس میایم اول پروژه cosole رو به عنوان start up در نظر میگیریم و بعدش با تعیین کردن پروژه ای که داخلش db context مون هستش و این دو تا بهم وصل هستند رو تعیین میکنیم و بعد migration رو انجام میدیم به این command دقت کنیم چون باعث ارور و ساخته نشدن migration میشه اگر اشتباه بزنیم مثل این ارور پایین


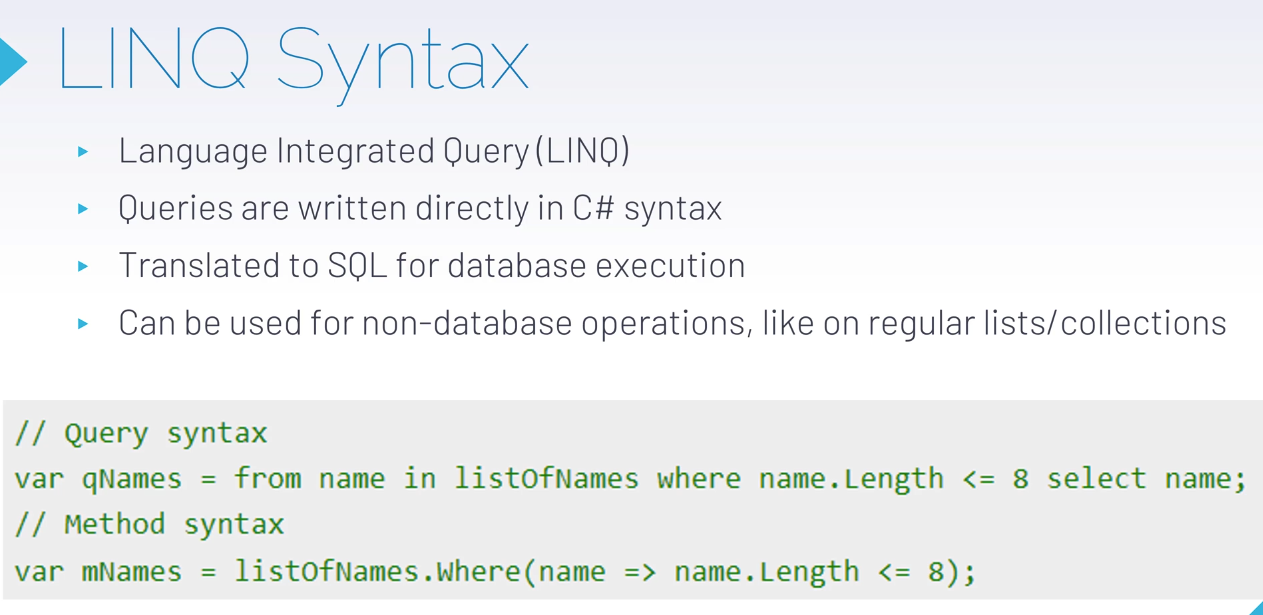 #LINQ
این linq هستش و شبیه به sql برعکس هستش در حالت query syntax
#LINQ
این linq هستش و شبیه به sql برعکس هستش در حالت query syntax
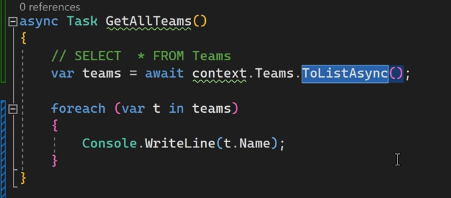
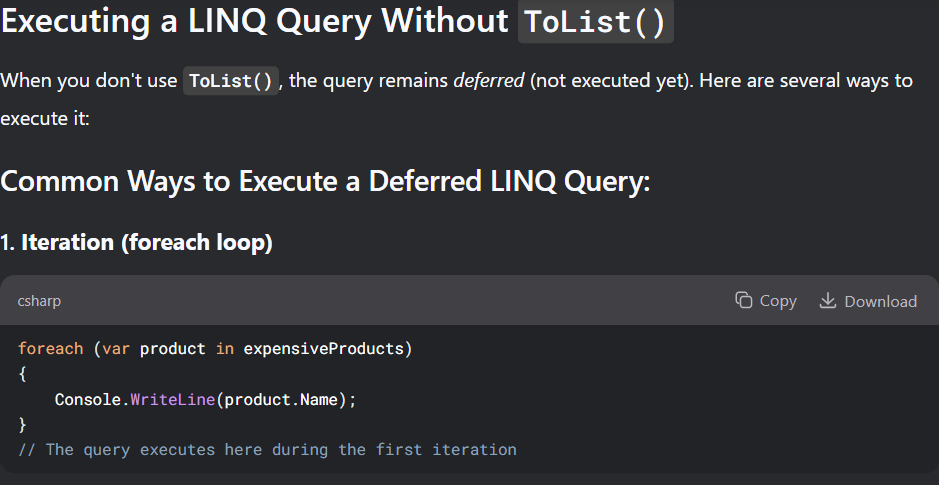
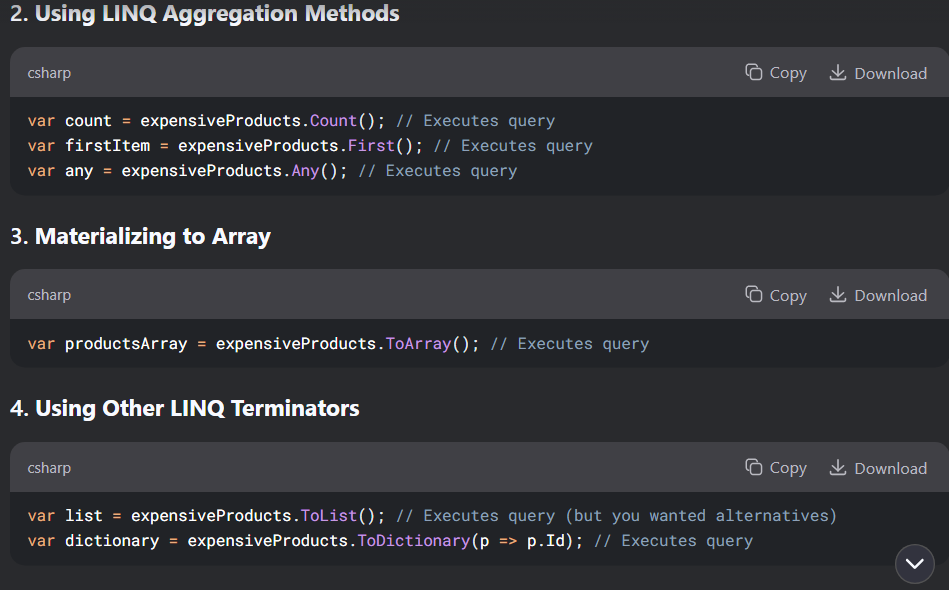
تا زمانی که از to list استفاده نکنیم query اجرا نمیشه وقتی که استفاده میکنیم ازش میره دیتا رو میاره و بعد تبدیلش میکنه به C# object و میریزتش توی memory و اونموقع میتونیم ازش استفاده کنیم
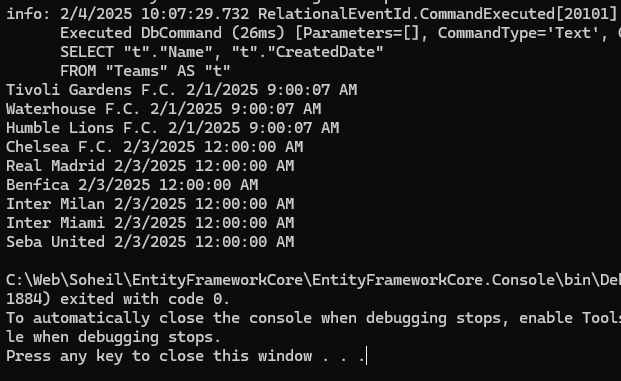
 خوب در بالا میبینید که sql اجرا شده اینطوریه که دیگه از * برای این که همه دیتا رو بگیره استفاده نکرده و اومده فقط اون فیلیدی که میخواستیم رو اورده و بعد اومده از alising هم استفاده کرده
خوب در بالا میبینید که sql اجرا شده اینطوریه که دیگه از * برای این که همه دیتا رو بگیره استفاده نکرده و اومده فقط اون فیلیدی که میخواستیم رو اورده و بعد اومده از alising هم استفاده کرده
عملیات های async جلوی thread block شدن رو میگیره ،
یه نکته ای که هست اینه که مثلا اگر بیایم برای ذخیره سازی از save changes استفاده کنیم که async نیستش تا زمانی که دیتا اعمال نشه در داخل دیتابیس هیچی چیزی نمیتونه دیتابیس دسترسی پیدا کنه و thread block میشه

 خوب Ef از کارکردن به صورت موازی ساپورت نمیکنه
و وایمسته یک عملیات تموم بشه و بعد عملیات بعدی رو شروع میکنه
به همین دلیل میایم با استفاده از async و awite میایم این رو براش طراحی میکنیم
خوب Ef از کارکردن به صورت موازی ساپورت نمیکنه
و وایمسته یک عملیات تموم بشه و بعد عملیات بعدی رو شروع میکنه
به همین دلیل میایم با استفاده از async و awite میایم این رو براش طراحی میکنیم
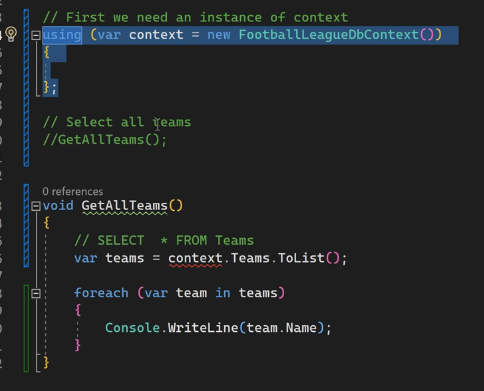
using
#Scope
وقتی که از using استفاده میکنیم فقط داخل همون scope هستش که میتونیم از اون پارامتر استفاده کنیم :
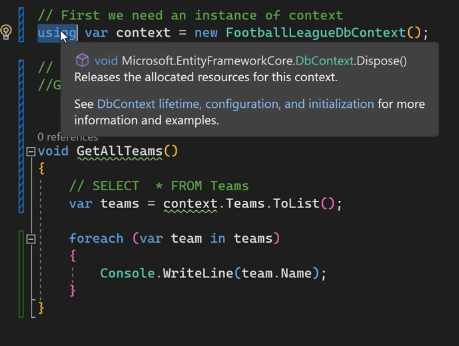
 اینجا context به دلیل این که خارج از اون scope هستش ارور میده
اینجا context به دلیل این که خارج از اون scope هستش ارور میده
 خوب در تصویر پایین
خوب در تصویر پایین
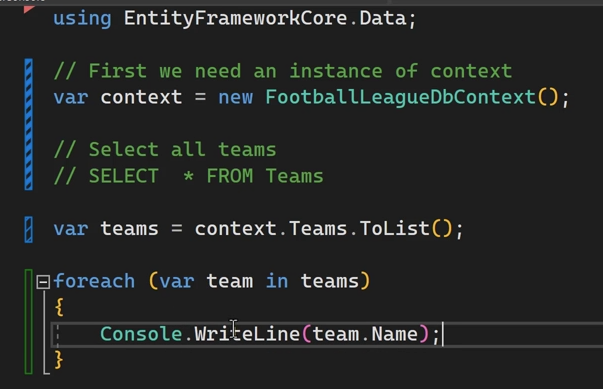
 اینجا اولی فقط میاد اولین مقدار رو از توی list تیم ها میاره و دومی میاد ، اولین تیمی که اون شرایط رو داره رو میاره مثلا اگر چند تا تیم داشتیم که id شون 1 بود فقط اولیه رو میورد
اینجا اولی فقط میاد اولین مقدار رو از توی list تیم ها میاره و دومی میاد ، اولین تیمی که اون شرایط رو داره رو میاره مثلا اگر چند تا تیم داشتیم که id شون 1 بود فقط اولیه رو میورد
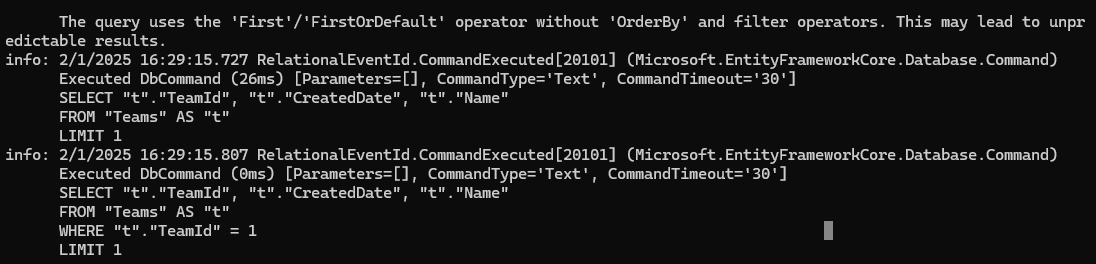
خوب حالا اگر در کد Sql دقت کنیم میبینیم که اونجا در آخر نوشته که limit 1
خوب فرق firstAsync با firstOrDefaultAsync اینه که دومی رو وقتی که استفاده کنیم ، اینطوری میشه که اگر دیتایی رو نتونه پیدا کنه یا این که دیتایی نباشه مقدار null رو میاره ولی اگر از اولی استفاده کنیم و این اتفاق بیوفته ارور وارد سیستم میشه
#firstAsync
#firstOrDefaultAsync
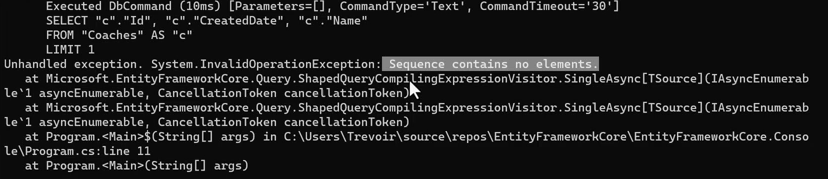 خوب در مورد بعدی :
خوب در مورد بعدی :
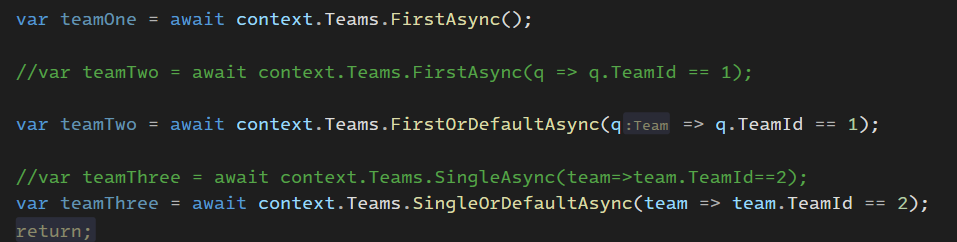
خوب وقتی که single or default استفاده کردیم همونطوری که در Sql اش میبنید limit 2 داره ، چرا ؟ چون که اگر بیشتر از یکی دیتا پیدا کردن یعنی دوتا و اون ها رو اورد بعدش تشخصی میده که بیش از یکیه و ارور میده
 مورد بعدی
مورد بعدی

 وقتی که میخوایم متدمون رو به متد async تبدیل کنیم : متد باید از نوع task بشه و از async و awite استفاده کنیم
وقتی که میخوایم متدمون رو به متد async تبدیل کنیم : متد باید از نوع task بشه و از async و awite استفاده کنیم
 هر جا نوشته بود predicate میشه همون lambda expressions خودمون
#predicate
#lamda_expressions
هر جا نوشته بود predicate میشه همون lambda expressions خودمون
#predicate
#lamda_expressions
 هر جایی که اینطوری نوشته بود و یه سمتش یه تایپ بود و یه سمت دیگه اش bool بود میشه همون lambda expressions
هر جایی که اینطوری نوشته بود و یه سمتش یه تایپ بود و یه سمت دیگه اش bool بود میشه همون lambda expressions
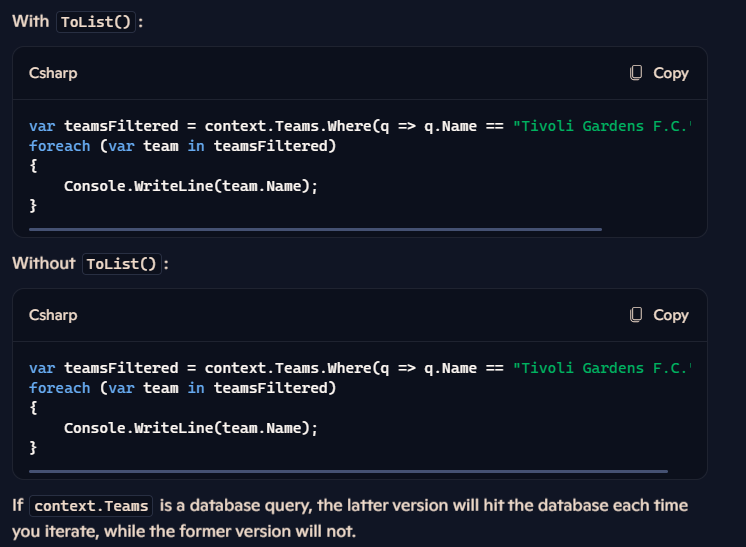
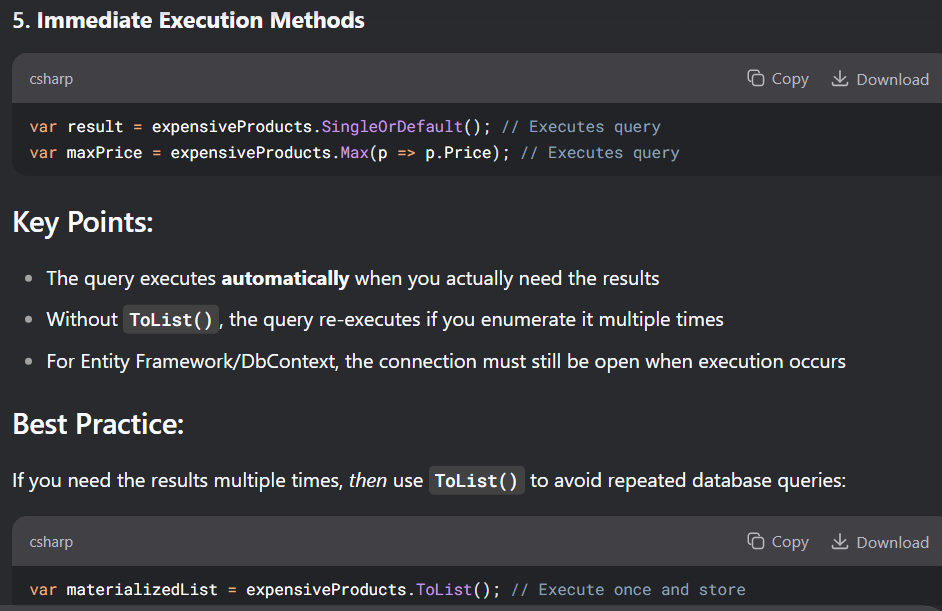
نکته : این کد پایین بدون to list هم کار میکنه ولی یه فرقی دارن ، اونم اینه که وقتی که to list رو ننوشته باشیم هر بار که میخوایم توی team filterd بیایم iterate کنیم اون میره و اطلاعات رو هر بار از دیتابیس میاره در صورتی که وقتی که از to list استفاده کنیم همون اول دیتا رو از دیتابیس میگیره و میریزه توی رم و بعد هر موقع بخوایم میتونیم ازش استفاده کنیم بدون این که دوباره بره دیتا رو بیاره
 #toList
وقتی از toList استفاده میکنیم که بخوایم query همون موقع اجرا بشه و بره دیتا رو بیاره و توی memory ذخیره کنه
#toList
وقتی از toList استفاده میکنیم که بخوایم query همون موقع اجرا بشه و بره دیتا رو بیاره و توی memory ذخیره کنه
بدون toList اتفاقی که میوفته اینه که اجرا شدن query رو به تاخیر میندازه تا زمانی که بخوایم توش itrate کنیم
این مورد efficency کمتری داره ولی به لحاظ استفاده از memory بهتر عمل میکنه
این یعنی این که وقتی که از tolist استفاده نمیکنیم داریم در حقیقت یه کوئری میسازیم و میتونیم مرحله به مرحله و قسمت های مختلف به این کوئری یه سری فیلتر ها و شرایط رو اضافه یا کم کنیم و بعد وقتی که با روش هایی پایین هر جوری بخوایم توش itrate کنیم اون رو اجرا میکنه



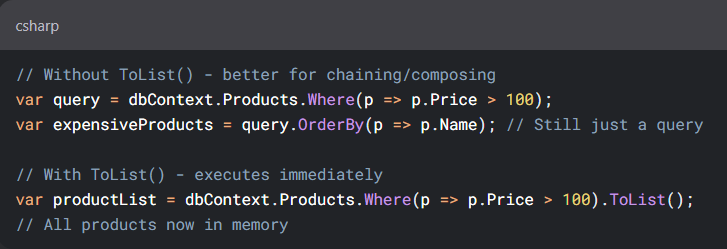
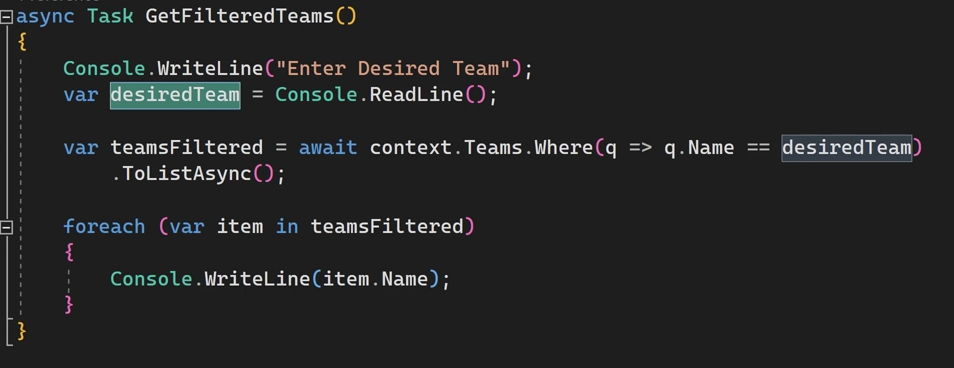
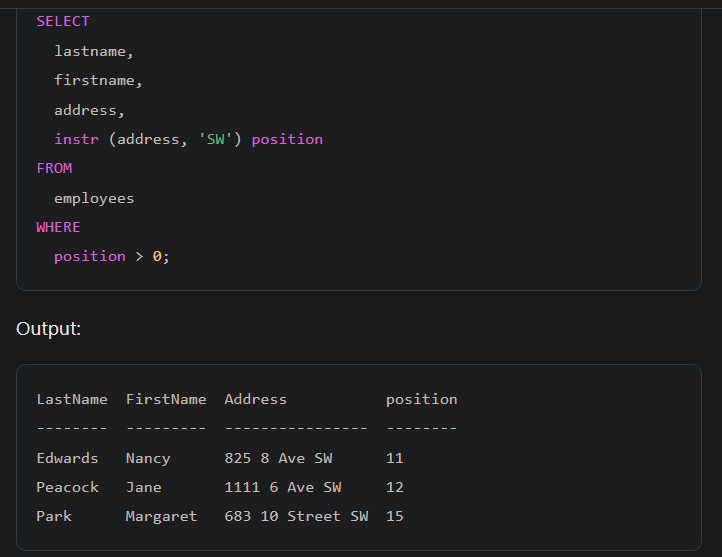
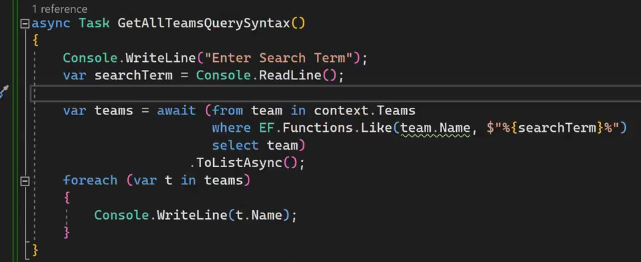
خوب توی تصویر بالا ما میخوایم از یوزر اسم اون تیمی که میخواد رو بگیریم ، حالا اینجا اتفاقی که میوفته توی .net یه level از securityرو داریم که برای محافظت در برابر Sql injection درست شده و اینه که هر چی که وارد بشه paramteirized میشه

نکته :
 این دو تا با هم برابر هستند ولی این رو باید دقت داشته باشیم که بعضی از متد ها تبدیل به sql ممکنه نشن و یا دچار exception بشن
این دو تا با هم برابر هستند ولی این رو باید دقت داشته باشیم که بعضی از متد ها تبدیل به sql ممکنه نشن و یا دچار exception بشن

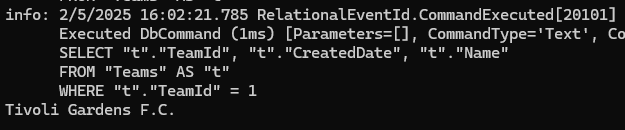
اینطوری از contain استفاده میکنیم


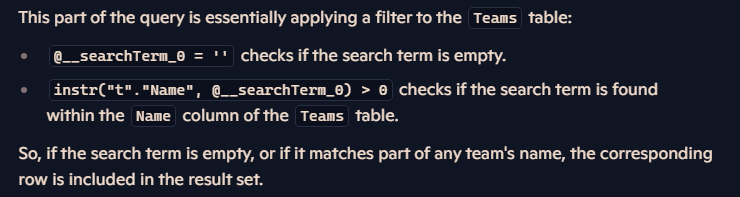
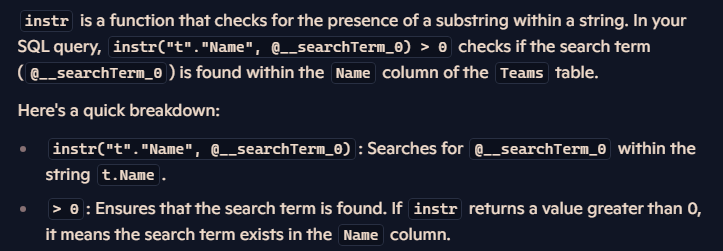
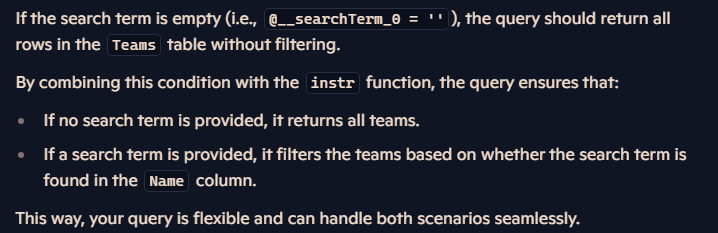
خوب اینجا اینطوریه که اگر چیزی توی شرط ننوشته باشیم یا شرط رو گذاشته باشیم یه string خالی این دستور میاد و همه ی دیتاهای موجود رو میاره، حالا اگر شرطی که گذاشتیم و نتیجه ی اون instr بیشتر از 0 باشه میره و اون دیتا ها رو میاره

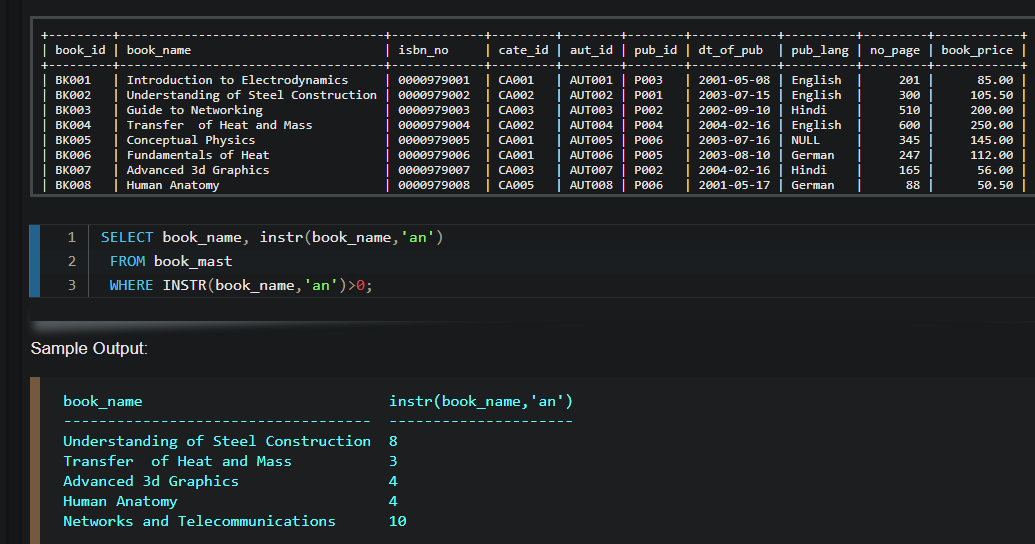 https://www.w3resource.com/sqlite/core-functions-instr.php
https://www.w3resource.com/sqlite/core-functions-instr.php
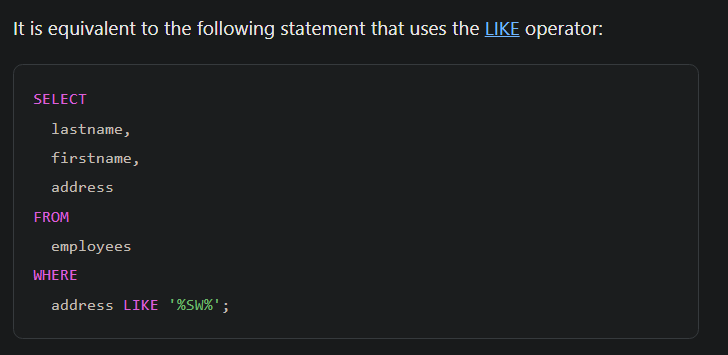
https://www.sqlitetutorial.net/sqlite-functions/sqlite-instr/
خوب حالا ما میتونیم به جای استفاده از این روش بالا بیایم و مستقیم از Ef استفاده کنیم :

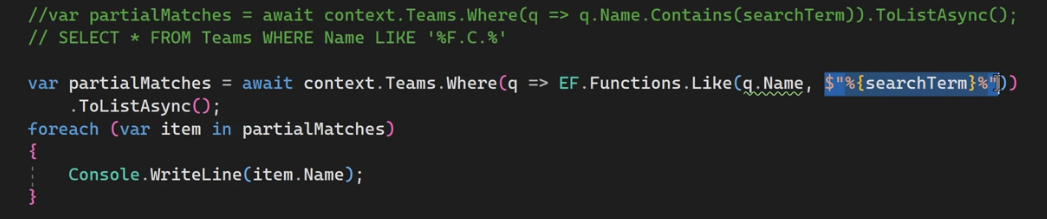

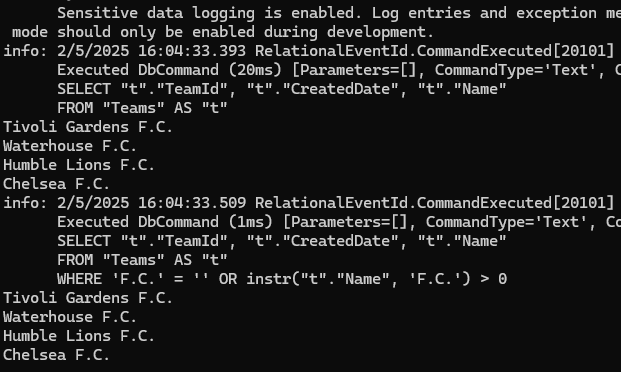
اینجا ما اومدیم و از @format استفاده کردیم و در خط بالاش مقدارش رو %F.C% رو گذاشتیم که % به معنای wild card هستند یعنی قبلش مهم نیست و بعدش هم مهم نیست که چی باشه هر جایی که F.C رو پیدا کرد بره و اون دیتا رو بیاره ، نکته بعد اینه که از like استفاده شده
خوب با استفاده از Ef و like میتونیم بهتر و دقیق تر سرچ کنیم چون توی ef میتونیم پترن براش تعیین کنیم یعنی بگیم که با اون کلمه شروع بشه یا تموم به یا موارد دیگه

اینجا نوشته که توی like اول جایی که قراره توش سرچ انجام بشه رو تعیین میکنیم که در این مورد name هستش و در آرگومان بعدی میاد و پترن رو میتونیم براش تعیین کنیم
 میتونیم به این روش که یجورایی شبیه به sql معکوسه متد ها رو به صورت hybrid استفاده کنیم ، به این شکل که ما اون رو داخل پرانتز نوشتیم و بعد از to list async استفاده کردیم
میتونیم به این روش که یجورایی شبیه به sql معکوسه متد ها رو به صورت hybrid استفاده کنیم ، به این شکل که ما اون رو داخل پرانتز نوشتیم و بعد از to list async استفاده کردیم
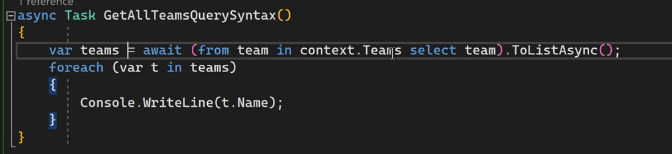

 این با اون بالاییه یکیه نتیجه شون
این با اون بالاییه یکیه نتیجه شون
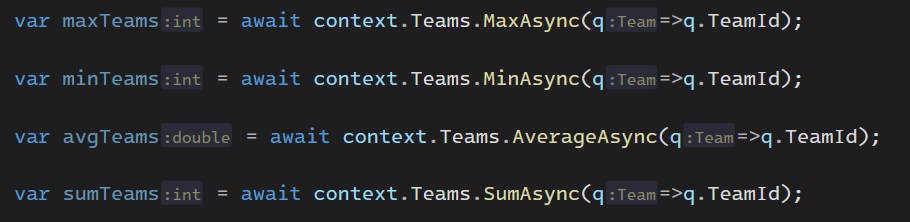
 حالا min , max, avg, sum
حالا min , max, avg, sum

حالا میرسیم به Count :

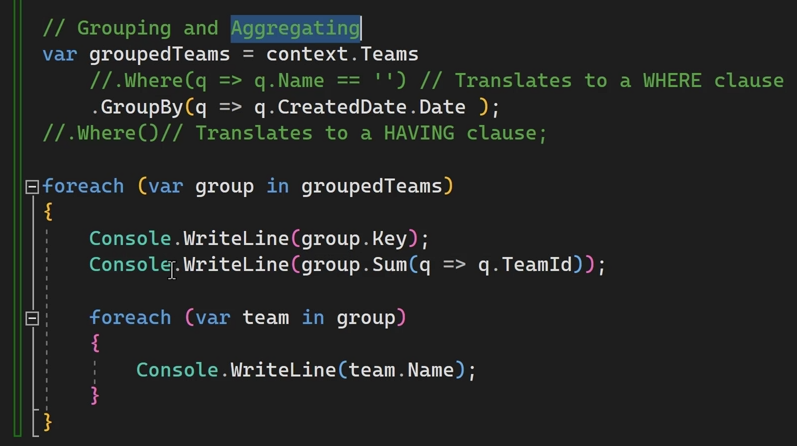
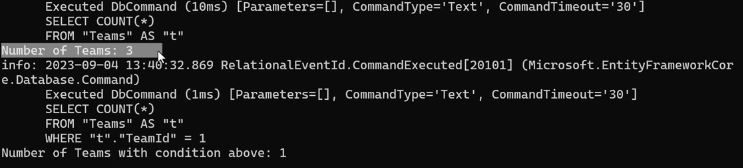 حالا میرسیم به group by :
حالا میرسیم به group by :
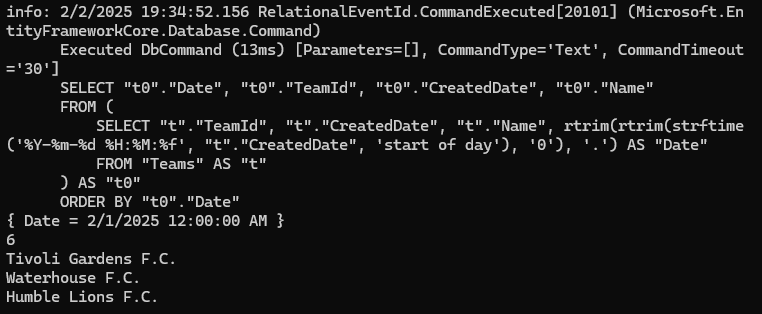
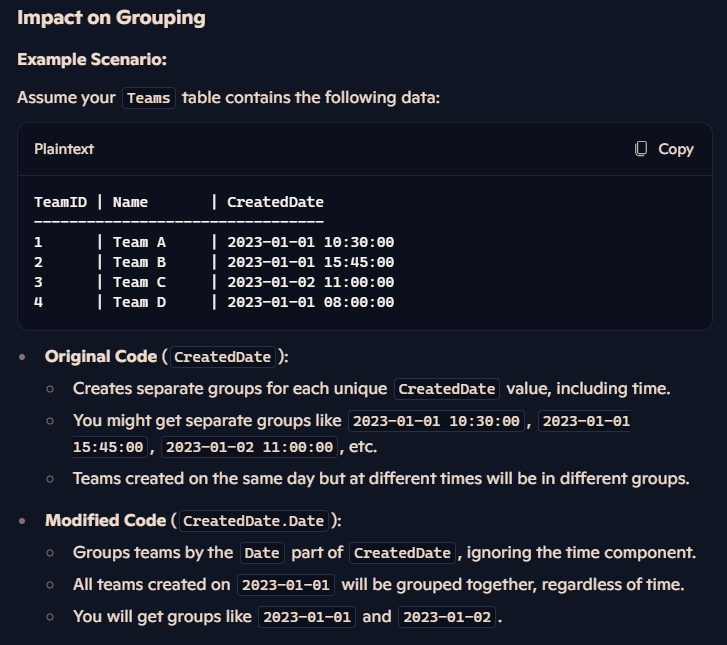
 اینجا اومدیم بر اساس create date گروه بندی رو انجام دادیم.
حالا اگر بخوایم بر اساس چند تا فیلد این دسته بندی رو انجام بدیم این کار رو باید بکنیم :
اینجا اومدیم بر اساس create date گروه بندی رو انجام دادیم.
حالا اگر بخوایم بر اساس چند تا فیلد این دسته بندی رو انجام بدیم این کار رو باید بکنیم :
 اینطوری هم میتونیم ازش استفاده کنیم که اول با where یه چیزی رو جدا کنیم و بعد بیایم و دسته بندی رو روی اونها انجام بدیم
اینطوری هم میتونیم ازش استفاده کنیم که اول با where یه چیزی رو جدا کنیم و بعد بیایم و دسته بندی رو روی اونها انجام بدیم
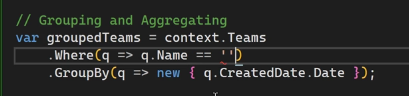

نکته ی خیلی مهمی که هست اینه که وقتی که میخوایم از توابع aggrigate یا همون سر جمعی استفاده کنیم باید اول group by رو روش انجام بدیم و بعد بیایم از اون توابع استفاده کنیم :
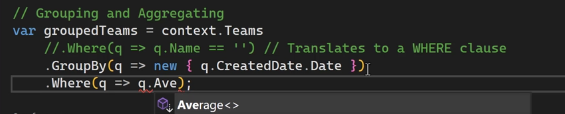 نکته ی بعدی :
نکته ی بعدی :

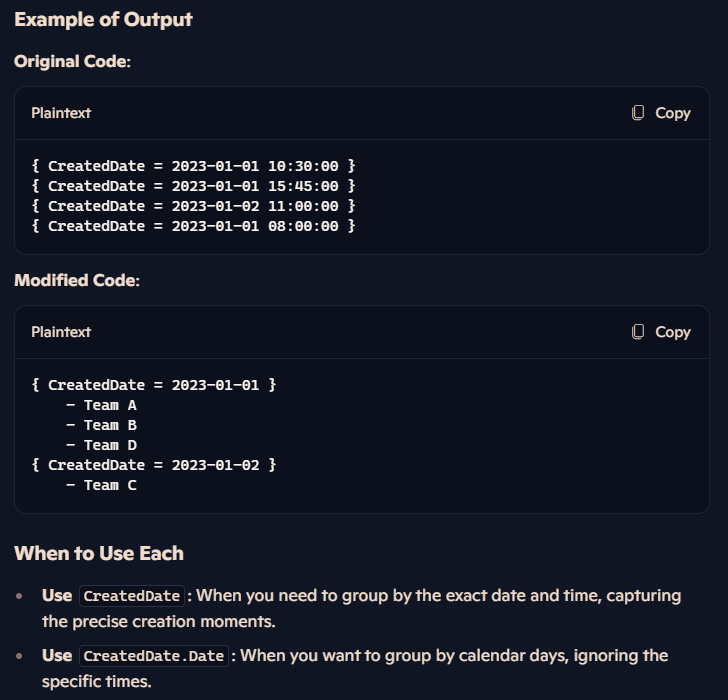
خوب در قسمت پایین دو حالت رو نوشتیم یکی این وقتی که داریم به دیتابیس کوئری میزنیم همونجا وقتی که میخوایم اطلاعات رو بگیریم به صورت sort شده بگیریم و حالت دوم اینه که دیتا رو همونطوری که در دیتابیس هست بگیریم و بعد بیاریم توی برنامه و بعد sort اش کنیم ، برای این که برنامه بهینه باشه به لحاظ استفاده از ram از حالت اول استفاده میکنیم
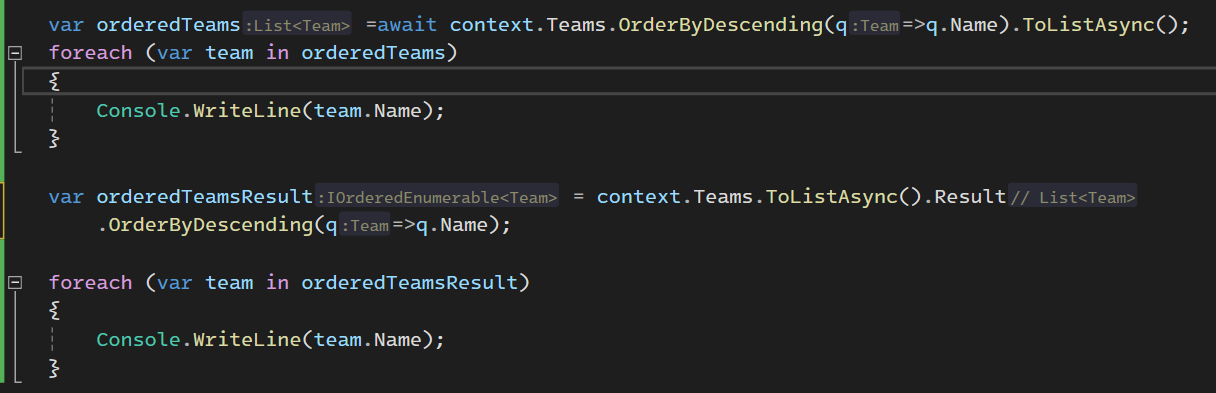
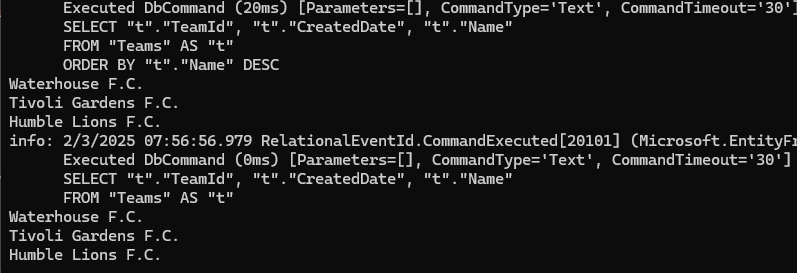
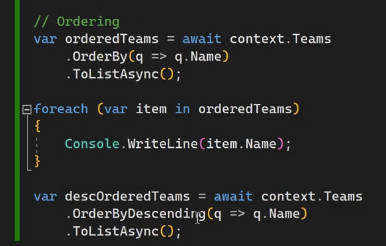
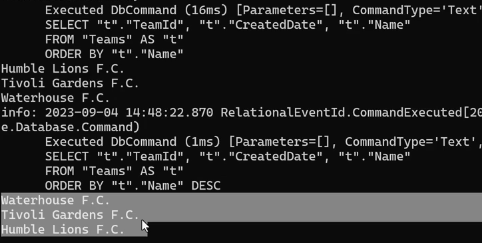 خوب حالا اگر ما یک مقدار max رو در یک ستون بخوایم باید بیایم order by decending روش انجام بدیم و بعد اولین دیتاش رو که میشه بیشترین مقدار رو بیاریم
خوب حالا اگر ما یک مقدار max رو در یک ستون بخوایم باید بیایم order by decending روش انجام بدیم و بعد اولین دیتاش رو که میشه بیشترین مقدار رو بیاریم
ولی میتونیم به جاش میتونیم از max by استفاده کنیم
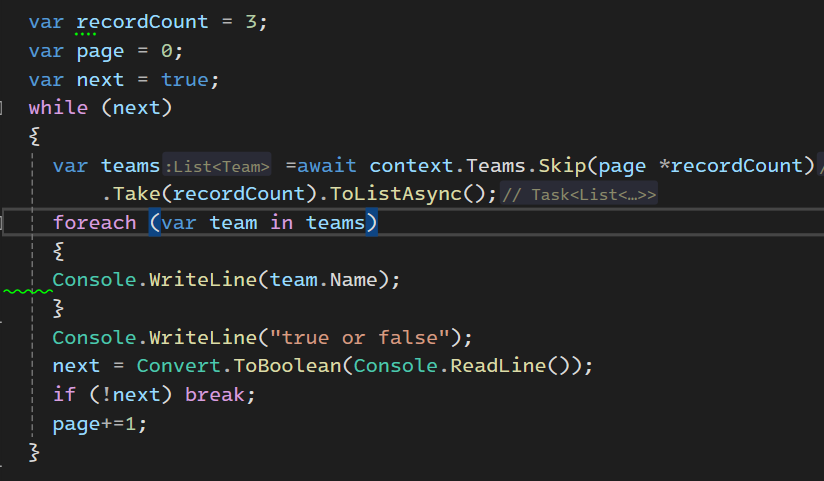
در تصویر پایین داره میگه که اگر بدون این که از to list یا to list async بخوایم استفاده کنیم بیایم کد رو بنویسیم ، برنامه میپوکه چون که در هر مرحله ای که داره foreach میزنه میره و دوباره دیتا رو میاره
خوب میخوایم از skip and take استفاده کنیم چون نمیخوایم همه دیتا رو به صورت یکجا بیاریم و اینطوری میتونیم تکه تکه بیاریم و به کاربر نشون بدیم

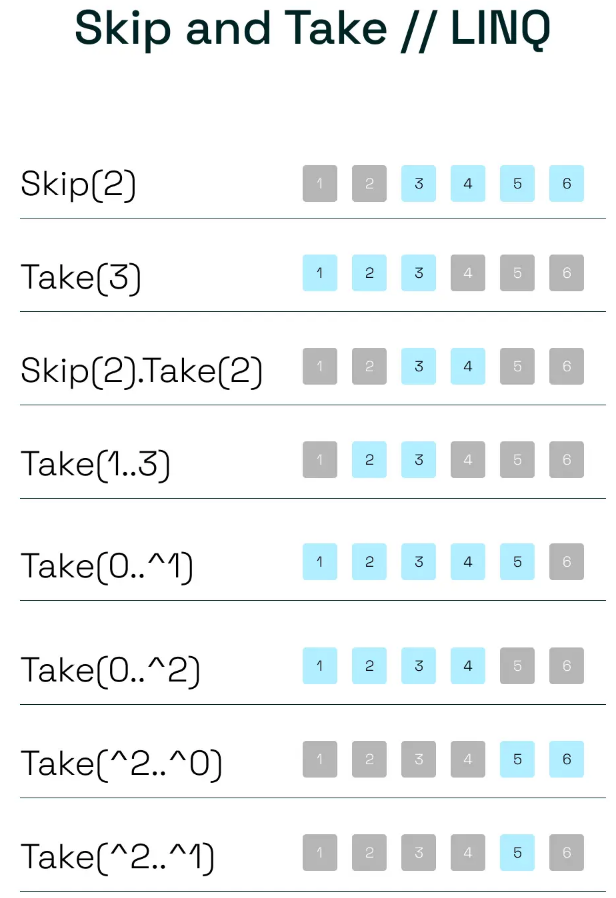 https://steven-giesel.com/blogPost/ce9ba892-bafe-4a62-8806-7ebf91f28a94
https://steven-giesel.com/blogPost/ce9ba892-bafe-4a62-8806-7ebf91f28a94
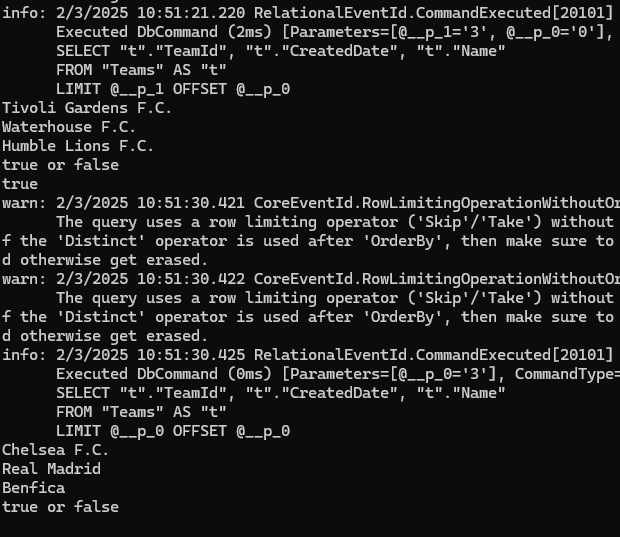
خوب توی کوئری دوم parameters p0 برابر شده با 3
میخوایم به طور مثال یه ستون از یک جدول رو میخوایم
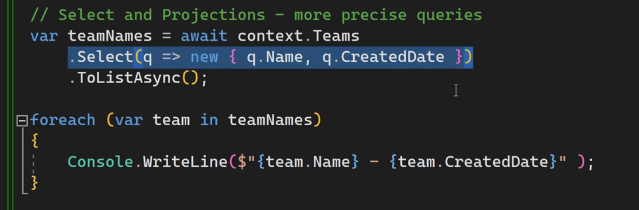
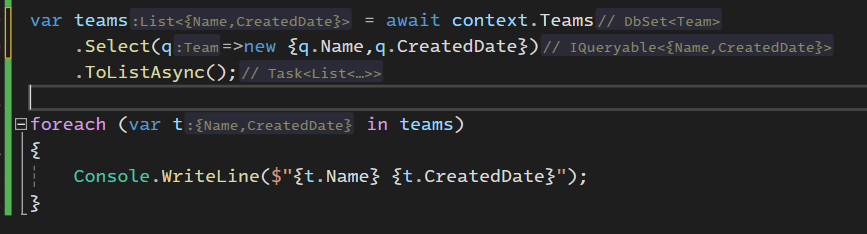
خوب select , projection
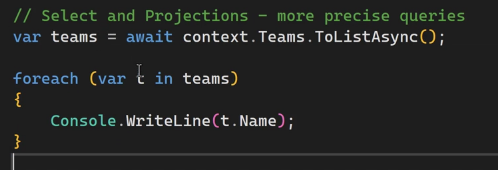
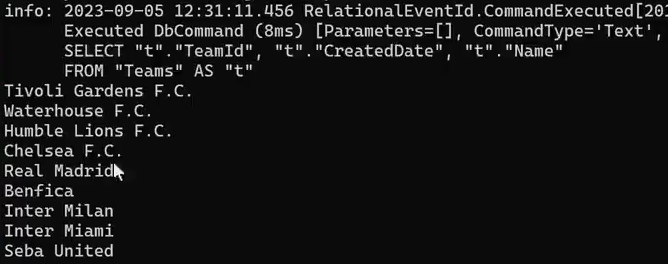
توی query میبینیم که توی قسمت select اومدیم و team id , created date , name رو select کردیم ولی موقع چاپ فقط از name استفاده کردیم حالا کاری که میخوایم انجام بدیم اینه که فقط اطلاعات یک ستون که میخوایم رو select کنیم و ازش استفاده کنیم
اینطوری team names تبدیل یه یه رشته string میشه ولی در حالت قبلی چون چند تا مورد دیگه هم داخلش بود یک object بودش
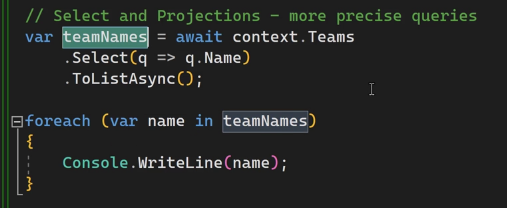
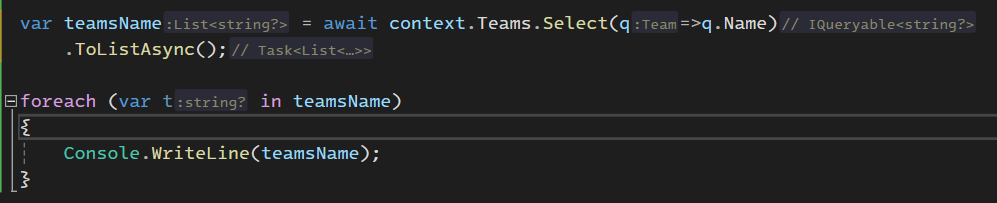
خوب حالا میخوایم از projection استفاده کنیم برای این که به طور مثال ببیشتر از یک فیلد رو بخونیم
با استفاده از اصول oop میتونیم یه annonymous data type رو درست کنیم اینطوری :
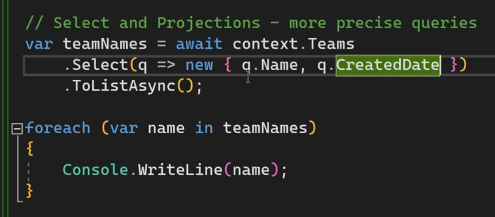
اینطوری هم ازش استفاده میکنیم :
o,خوب حالا میخوایم یه چیزی شبیه به dto یا data model یا view model رو ایجاد کنیم
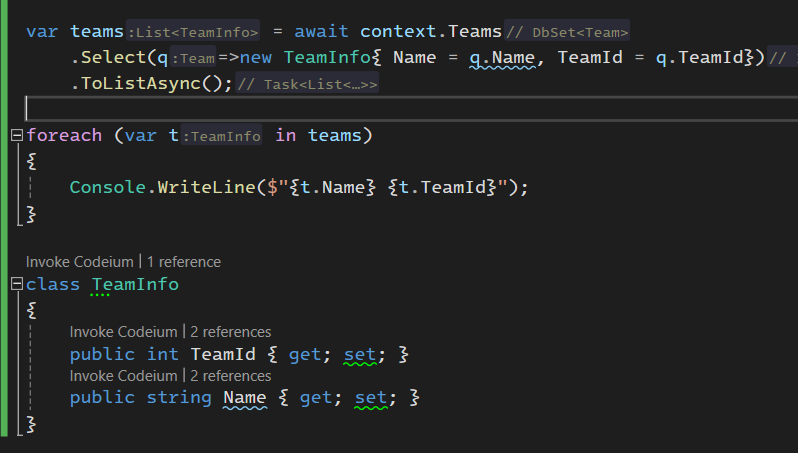
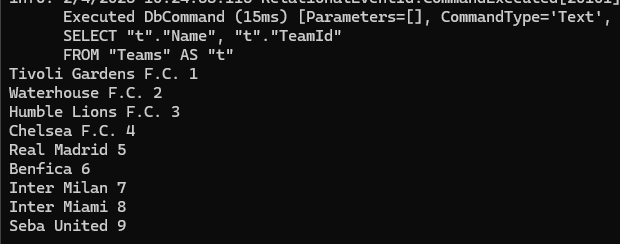
میرسیم به tracks ، خوب ef میاد object هایی که از query بدست میاد و داخل رم قرار میگیره رو میتونه track کنه و چک کنه ببینه چیزی تغییر کرده از زمانی که این دیتا وارد رم شده یا خیر تغییری نکرده
خوب حالا این track کردن زمانی که بخوایم روی api ها کار کنیم به کار نمیاد چون که ما توی api ها میایم و یه کوئری رو اجرا میکنیم و بعد دیتاش رو میگیریم و بعد هم برمیگرونیمش حالا در api ها نیازی به track کردن نیستش چون که اون end point که داریم باهاش دیتا رو تغغیر میدیوم با اون end point که داریم ازش دیتا رو میگیریم متفاوته


جاهایی که قراره فقط دیتا رو بخونیم نیازی به track کردن نداریم
نکته ای که هست اینه که tracking به صورت اتوماتیک انجام میشه و اگر بخوایم غیر فعالش کنیم باید بهش بگیم
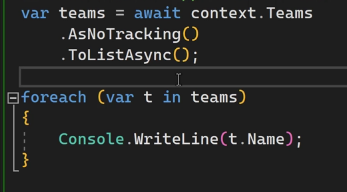
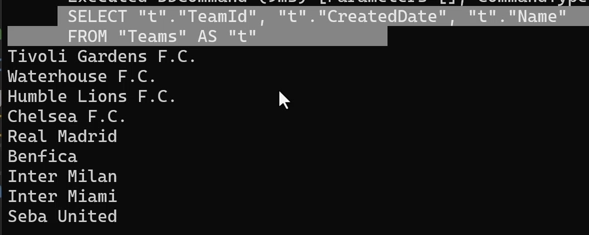
نکته ای که هست اینه که اینجا کوئری همون کوئری هستش ولی اینجا دیگه Ef نمیاد از resourse هایی که داره برای track کردن این دیتا استفاده کنه

حالا اینجا یه مورد خیلی جالب داریم اونم استفاده از Iqueryable
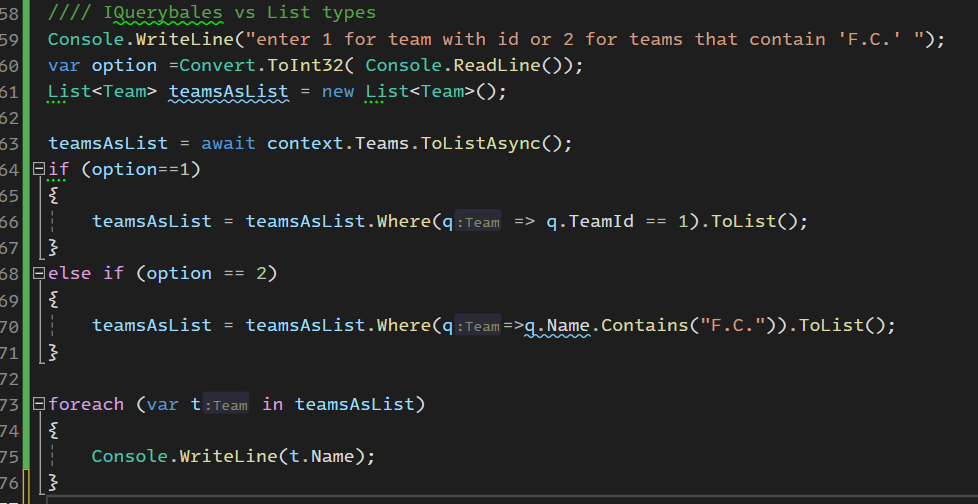
خوب توی مورد اول که مثل سری های قبلی نوشته ایم و از list استفاده کردیم توی این حالت تمام دیتا های teams رو میاریم
دقت داشته باشید که در مورد بالا ما یک بار دیتا رو به صورت کلی اوردیم و از to list asyc استفاده کردیم یعنی یک بار دیتا به صورت کامل با کوئری از دیتابیس آورده شده و بعد اومدیم با استفاده از where دیتای مورد نظرمون رو جدا کردیم و بعد دوباره از to list استفاده کردیم
ولی در مورد پایین میایم کوئری که میخوایم از دیتابیس بیایم دیتامون رو بیاریم به همون شکل کوئری رو مینویسیم و دیگه نیازی به این که کل دیتابیس رو بیاریم نیست
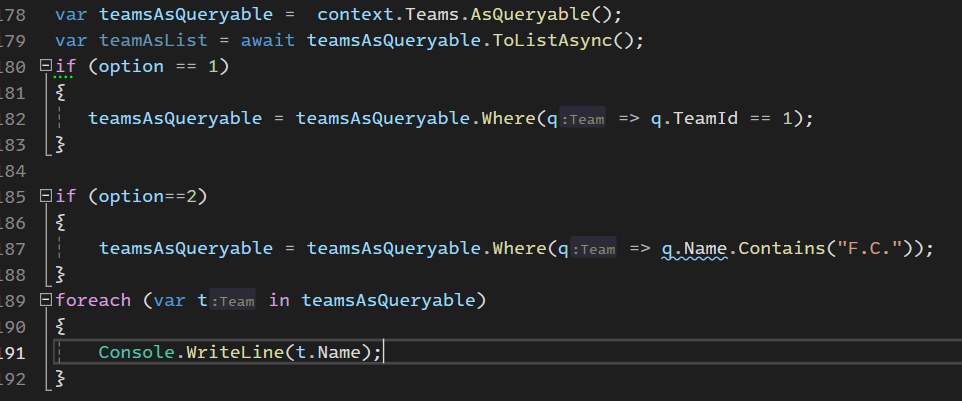
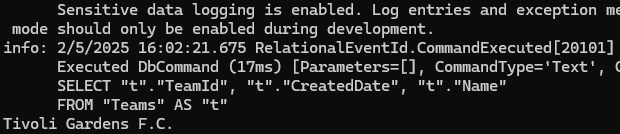
نکته ی اول اینه که توی indexing دقت کنیم اگر index گذاری در دیتابیس باعث بهتر شدن سرعت query هامون میشه ولی زیاد که باشه و در جای مناسب استفاده نشه دیتابیس رو کند میکنه در عملیات write کردن ولی در read کردن سرعت رو زیاد میکنه
تا میتونیم از projection استفاده کنیم تا اون چیزی که فقط میخوایم رو از دیتابیس بگیریم
از skip and take به خوبی استفاده کنیم برای این که اطلاعات زیاد از دیتابیس رو نیاریم
از async استفاده کنیم
یه جاهایی ما مجبور هستیم که از sql query استفاده کنیم چون که ef نمیونه یه جاهایی Query های خیلی خوب درست کنه
از no tracking استفاده کنیم
از batch operation استفاده کنیم ،

میرسیم به tracking
 خوب tracking زمانی خیلی خوب کار میکنه که برای کوئری خوندن دیتا و کوئری نوشتن یا همون تغییر دیتا دیتا از یه dbcontext استفاده کنیم
خوب tracking زمانی خیلی خوب کار میکنه که برای کوئری خوندن دیتا و کوئری نوشتن یا همون تغییر دیتا دیتا از یه dbcontext استفاده کنیم
 خوب ef میاد به صورت اتوماتیک تغییرات که روی entity ها انجام میشه زمانی که از Save changes یا save changes async دنبال میکنه
خوب ef میاد به صورت اتوماتیک تغییرات که روی entity ها انجام میشه زمانی که از Save changes یا save changes async دنبال میکنه
 خوب چیزی که هست اینه که ما میتونیم از detect changes استفاده کنیم که در زمانی که save changes میخواد انجام و اینطوری میفهمیم که چه چیزهایی تغییر میکنه - بین کوئری و عملیات saving
خوب چیزی که هست اینه که ما میتونیم از detect changes استفاده کنیم که در زمانی که save changes میخواد انجام و اینطوری میفهمیم که چه چیزهایی تغییر میکنه - بین کوئری و عملیات saving

خوب tracking یه state داره و اونم هم مثال هاشو رو میگیم و این state بسته به این که عملیات یا همون operation که روی entity انجام میشه تغییر میکنه.
 خوب حالا اینجا state ها رو توضیح داده و آخریش برای این استفاده میشه که وقتی ما فقط یه پراپرتی رو تغییر دادیم و همون رو هم state اش رو تغییر میدیم و بقیه پراپرتی ها تحت تاثیر قرار نمیگیرن
خوب حالا اینجا state ها رو توضیح داده و آخریش برای این استفاده میشه که وقتی ما فقط یه پراپرتی رو تغییر دادیم و همون رو هم state اش رو تغییر میدیم و بقیه پراپرتی ها تحت تاثیر قرار نمیگیرن
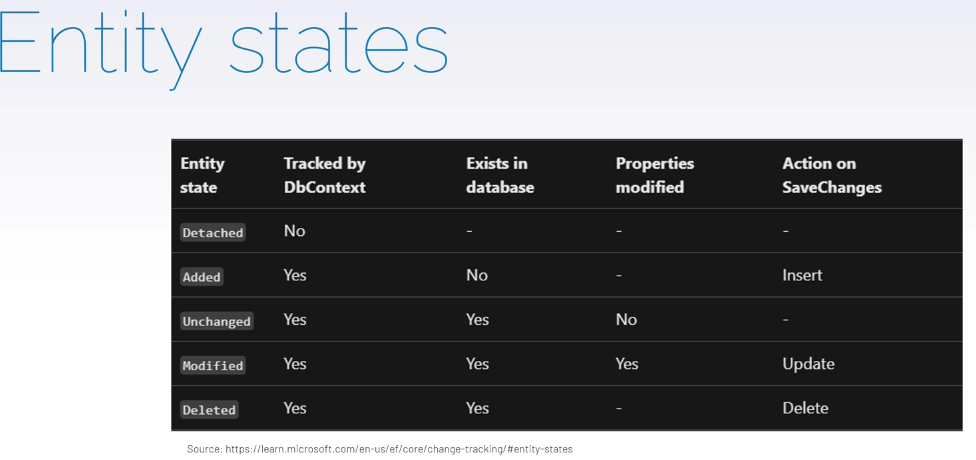

نکته ی خیلی مهم اینه که وقتی که از save changes داریم استفاده میکنیم تغییرات به صورت قسمتی اعمال نمیشن و transactional هستند به این معنی که اگر ما 3 تا entity رو تغییرات دادیم و 2 تا از اون ها تغییرات روشون اعمال شد ولی روی یکیشون fail شد کل اون پروسه fail میشه و تمامی تغییرات از بین میره
خوب میخوایم دیتا رو بفرستیم بر اساس یه ترتیب خاص بچینیم و داخل دیتابیس و دیتا رو بر اساس یه ترتیب خاص واردش کنیم دیتا رو
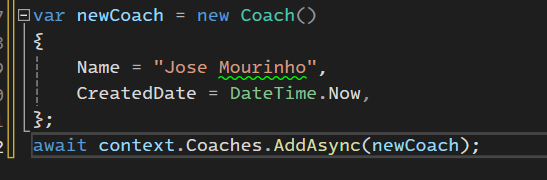


اینجا اتفاقی که داره میوفته اینه که داره میگه که اینجا ما newCoach رو که اصلا دیتابیس اصلا چیزی نمیدونه راجع بهش رو میخوایم state اش رو تغییر بدیم به entity state added و از این به بعد هم track روش انجام میشه و وقتی که save changes رو call کنیم دیتاش وارد دیتابیس میشه
اینجا توی متن دقت کنید اینطوریه که entity state از جنس enum هستش و added یه مقداره
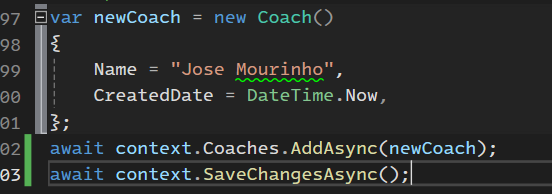
 خوب اینجا مقداری که میخوایم توی دیتابیس وارد کنیم از فیلتر ef میگذره و اون میاد برای امنیت بیشتر اطلاعاتی که قراره وارد بشه رو paramiterized اش میکنه که اینجا p0 رو تاریخ و p1 رو اسم مربی که نوشتیم در نظر گرفته
خوب اینجا مقداری که میخوایم توی دیتابیس وارد کنیم از فیلتر ef میگذره و اون میاد برای امنیت بیشتر اطلاعاتی که قراره وارد بشه رو paramiterized اش میکنه که اینجا p0 رو تاریخ و p1 رو اسم مربی که نوشتیم در نظر گرفته
خوب اینجا در SQLITE میاد میگه که میتونیم ID که اون دیتا در دیتابیس قرار گرفته رو return کنیم
ولی در sql server یه چیزی شبیه به scope identity که نمایشگر id هستش رو داریم
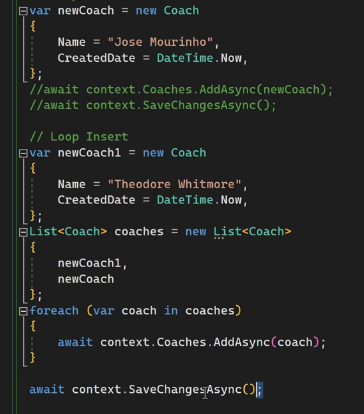
خوب در کد بالا میخوایم دوتا مربی رو با اسم و تاریخ وارد دیتابیس کنیم برای این کار میایم این دو تا رو میریزیم توی لیست و بعد میایم با foreach وضعیت و state شون رو به حالت added تغییر میدیم و بعد میایم با save changes async همه ی اون ها رو وارد دیتابیس میکنیم ، حالا نکته ای که هست اینه که اگر بخوایم این رو در نظر داشته باشیم که یکی از این ها مشکل داشته و ارور داشته باشه هیچ کدوم از این دیتا ها وارد دیتا بیس نمیشن حالا یه رویکرد دیگه هم که داریم اینه که save changes async رو ببریم داخل foreach اینطوری اون هایی که دیتاشون سالمه در دیتابیس ذخیره میشن و اونی که اورو داره ذخیره نمیشه ولی اینطوری با اون foreach هر بار داریم دونه دونه اطلاعات رو وارد میکنیم که خوب نیست ولی باز هم شاید نیاز بیزینس اینطوری باشه
 خوب حالا میتونیم با change tracker بیایم و تغییرات رو از زمانی که کوئری اجرا شده رو ببینیم یا قبل از این که بخوایم Save changes رو اجرا کنیم ببینیم چیا تغییر کردن
خوب حالا میتونیم با change tracker بیایم و تغییرات رو از زمانی که کوئری اجرا شده رو ببینیم یا قبل از این که بخوایم Save changes رو اجرا کنیم ببینیم چیا تغییر کردن

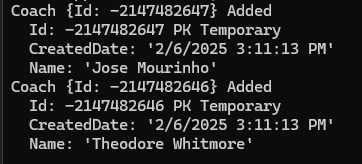 خوب id که در نظر گرفته شده min int هستش و بعدش entity state هستش که شده added و بعدش id رو به صورت temp در نظر گرفته
خوب id که در نظر گرفته شده min int هستش و بعدش entity state هستش که شده added و بعدش id رو به صورت temp در نظر گرفته
خوب اینجا tracker میبینه که دو تا record جدید بهش اضافه شدن و منتظر هستن برای save شدن
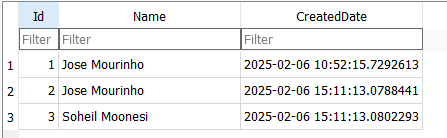
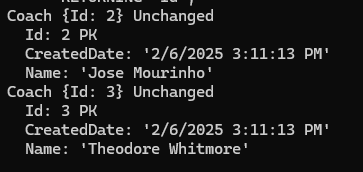 خوب اینجا داره میگه که دیتا از زمانی که توی دیتابیس ذخیره شده تغییری روش انجام نشده و id اش هم توی دیتا بیس رو نوشته با تمامی مشخصاتش ، فقط نکته ای که هست اینه که زمانی که در دیتابیس ذخیره میشه از اونجا به بعد میتونیم به id اش دسترسی پیدا کنیم
خوب اینجا داره میگه که دیتا از زمانی که توی دیتابیس ذخیره شده تغییری روش انجام نشده و id اش هم توی دیتا بیس رو نوشته با تمامی مشخصاتش ، فقط نکته ای که هست اینه که زمانی که در دیتابیس ذخیره میشه از اونجا به بعد میتونیم به id اش دسترسی پیدا کنیم
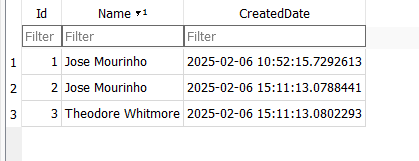 خوب نکته ی دیگه که هست اینه که ef میره و مقادیر رو آپدیت میکنه منظورمون به طور مثال عوض شدن id از min int به 2 و 3 که اینجا اینجام شده
خوب نکته ی دیگه که هست اینه که ef میره و مقادیر رو آپدیت میکنه منظورمون به طور مثال عوض شدن id از min int به 2 و 3 که اینجا اینجام شده
خوب حالا یه داستان دیگه ای هم که داریم اینه که ما درسته که میتونیم از foreach برای ذخیره سازی استفاده کنیم ولی بهتره که از add range async استفاده کنیم

میرسیم به update :

خوب این رو باید دقت کنیم که وقتی که داریم از find استفاده میکنیم اون میره اول ram رو نگاه میکنه ، در صورتی که این آبجکتی که ما میخوایم track شده باشه ، حالا اگر track نشده باشه مستقیم میره و از دیتابیس میخونه
به صورت دیفالت اگر ما توی کوئری یا توی db context هم تعیین نکرده باشیم به صورت دیفالت آبجکت ها track میشن

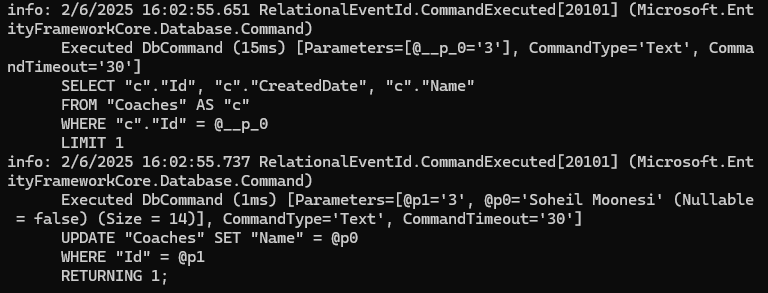
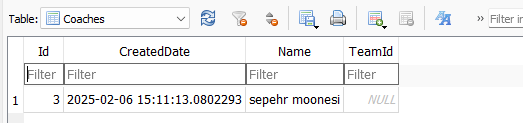
 نکته اینجا فقط اومده name رو که تغییر کرده رو آپدیت کرده
نکته اینجا فقط اومده name رو که تغییر کرده رو آپدیت کرده
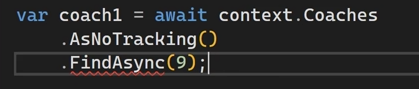 خوب اگر بخوایم از Find استفاده کنیم find نیاز داره تا دیتا track شده باشه و داخل رم باشه تا بتونیم ازش استفاده کنیم در این شرایط که داریم از no tracking استفاده میکنیم باید بیایم و از first or default async استفاده کنیم
خوب اگر بخوایم از Find استفاده کنیم find نیاز داره تا دیتا track شده باشه و داخل رم باشه تا بتونیم ازش استفاده کنیم در این شرایط که داریم از no tracking استفاده میکنیم باید بیایم و از first or default async استفاده کنیم



خوب اینجا فقط اومده و id رو پیدا کرده و آورده و دیگه save changes اعمال نشده و دلیلش هم اینه که ef اصلا چیزی راجع به coach1 نمیدونه و برای این که Ef رو از اعمال تغییرات مطلع کنیم باید از update استفاده کنیم و state اون دیتامون رو در دیتابیس به حالت update بیاریم

نکته ای که هست اینه که update range رو هم میتونیم استفاده کنیم اگر چند تا دیتا داشتیم
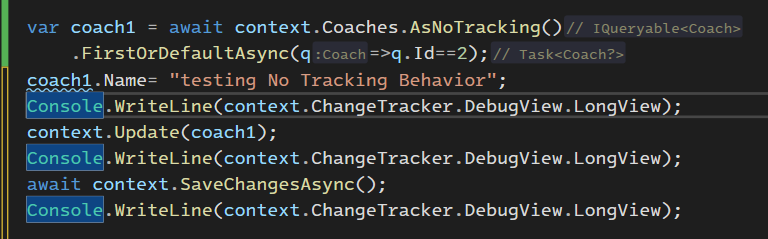
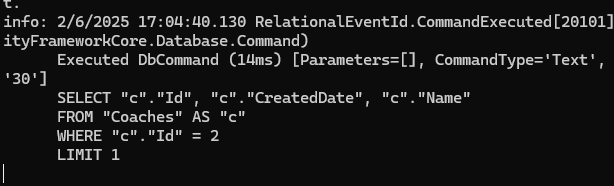 خوب در مرحله ی اول چون دیتا داخل ram نیستش میره مستقیم از دیتابیس میارتش با این کوئری بالا
خوب در مرحله ی اول چون دیتا داخل ram نیستش میره مستقیم از دیتابیس میارتش با این کوئری بالا
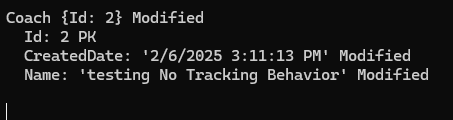 در مرحله ی بعدی وقتی که update انجام میشه وضعیت id 2 به modified تغییر پیدا میکنه
نکته ای که وجود داره اینه که با این که ما فقط name رو تغییر دادیم ولی چون توی حالت no tracking هستیم روی همشون modified اعمال میشه چون track نکرده از قبل که ببینه چی تغییر کرده
در مرحله ی بعدی وقتی که update انجام میشه وضعیت id 2 به modified تغییر پیدا میکنه
نکته ای که وجود داره اینه که با این که ما فقط name رو تغییر دادیم ولی چون توی حالت no tracking هستیم روی همشون modified اعمال میشه چون track نکرده از قبل که ببینه چی تغییر کرده
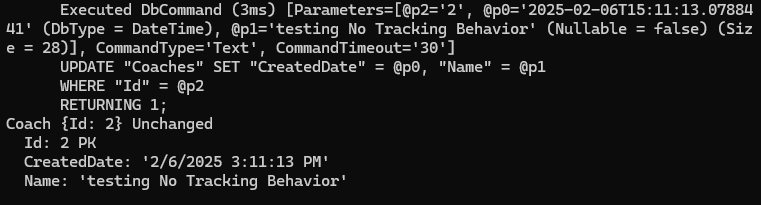
در این مرحله آپدیت انجام میشه و state هم به صورت unchanged هستش
خوب حالا یه روش دیگه هم برای آپدیت داریم که اون اینطوریه که بیام دستی state اون entity مون رو خودمون به modified تغییرش بدیم

اینطوری ما به صورت دستی داریم به ef میگیم که برو این entity رو چک کن و track کن چون state اش رو تغییر دادیم
میرسیم به delete:

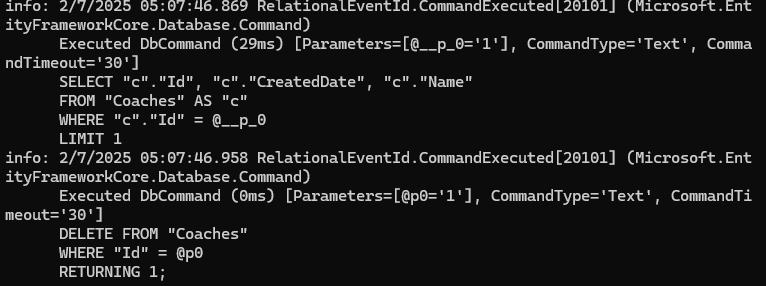
حالت دوم :

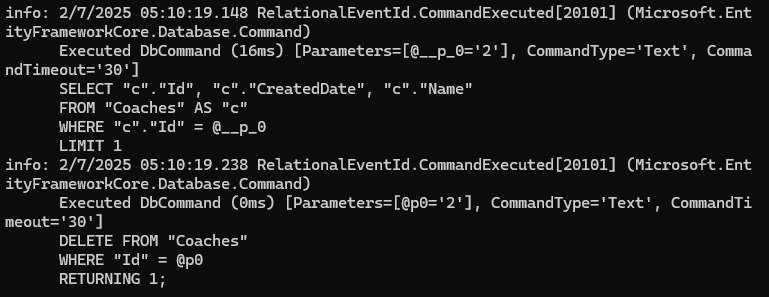
نکته ما اگر بخوایم obejct رو delete کنیم حتما باید track شده باشه و آورده باشیمش توی رم و بعد پاکش کنیم یعنی در این حالت نمیتونیم از As no tracking برای آوردن دیتا استفاده کنیم
این از ef 7 به اضافه شده که بتونیم بدون این که بخوایم دیتا رو بیاریم مستقیما دیتا رو حذف یا تغییرش بدیم :

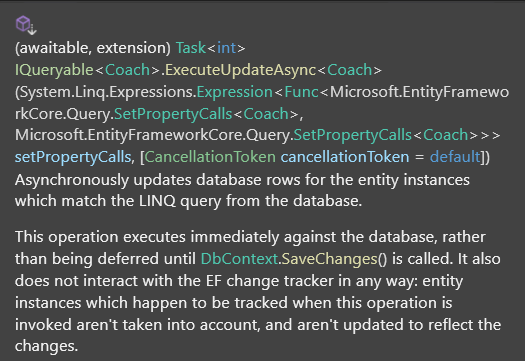
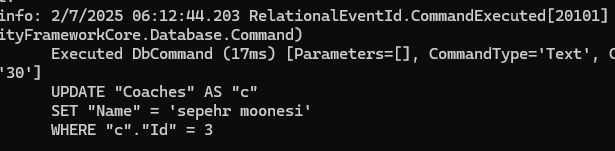
حالا اگر چندین تا مورد داشتیم :


برای پاک کردن :


خوب این رو در نظر بگیرید که وقتی که از این دو متد استفاده میکنیم دیگه لازم نیست به صورت دستی بیایم add migration و بعد update data base رو به صورت کامند بزنیم چون این دو تا متد به صورت اتوماتیک انجامش میدن ولی این رو دقت داشته باشید که برای تست از اینها استفاده میشه نه برای production
نکته ی خیلی خیلی مهم اینه که ما نمیتونیم وقتی که میخوایم در کلاس دیتایی که توی دیتابیس هستش بیایم و یه فیلد که not nullable باشه رو اضافه کنیم
برای توضیح ساده تر
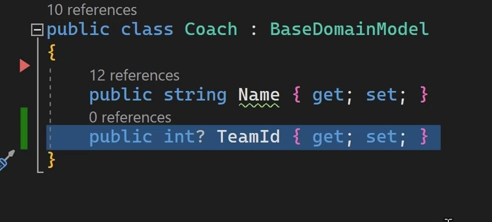 اینجا ما از قبل name رو داشتیم حالا میخوایم team id رو اضافه کنیم خوب اینجا ما نمیتونیم فیلدی که nullable نباشه رو اضافه کنیم چون که دیتا هایی قبلی اونطوری به مشکل میخورن و اینجا ما باید nullable در نظر بگیریم که دیتاهای قبلی هم به مشکل نخورند
اینجا ما از قبل name رو داشتیم حالا میخوایم team id رو اضافه کنیم خوب اینجا ما نمیتونیم فیلدی که nullable نباشه رو اضافه کنیم چون که دیتا هایی قبلی اونطوری به مشکل میخورن و اینجا ما باید nullable در نظر بگیریم که دیتاهای قبلی هم به مشکل نخورند
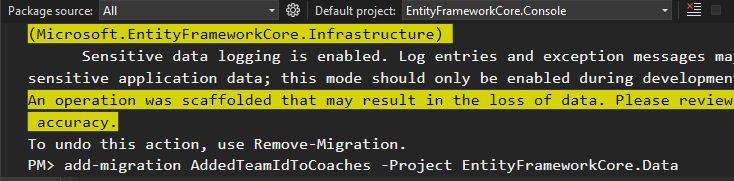 اینطوری migration رو انجام میدیم
اینطوری migration رو انجام میدیم

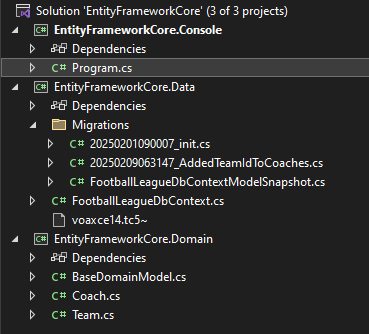


خوب توی فولدر migration میبینیم که migration به اسم AddedTeamIdtoCoaches اومده که حالا میخوایم اون update-database رو با کد روش انجام بدیم
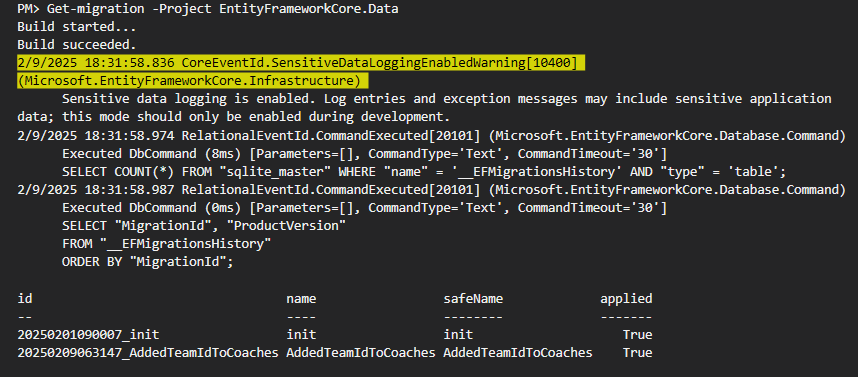
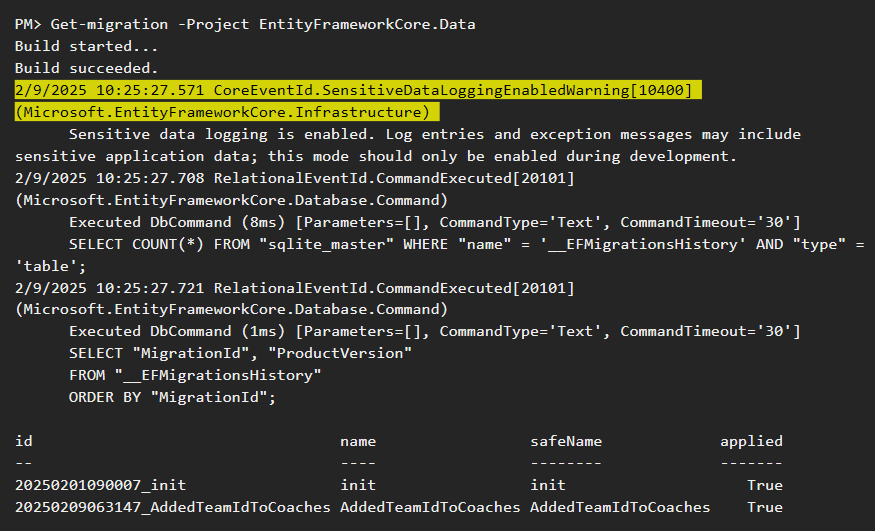 با این کامند میایم و میبنیم که اون migration روی دیتابیس اعمال شده یا خیر که میبینیم که توی applied زده true چون که یه بار من قبل از این که بخوام اسکرین بگیرم run اش کرده بودم
با این کامند میایم و میبنیم که اون migration روی دیتابیس اعمال شده یا خیر که میبینیم که توی applied زده true چون که یه بار من قبل از این که بخوام اسکرین بگیرم run اش کرده بودم




خوب با استفاده از Ef bundles دیگه نیازی نداریم که پکیج هایی که مرتبط با cli هستش رو نصب کنیم یه قابلیت دیگه ای که بهمون میده اینه که توی pipeline ci/cd عملیاتش رو انجام میده و این که error handling بهتری داریم
خوب در حالت عادی وقی که migration ها دارن اجرا میشن با اون دستور بالا هر کدوم از migraion ها یا انجام یا نمیشن یعنی اگر 3 تا migration داشتیم و دومی کار نکرد میره و سومی رو اجرا میکنه و ما بعدش باید بریم به صورت دستی ببینیم که کدومشون اجرا نشده و چرا
ولی در این حالت کل migraion ها باید انجام بشن و اگر نشن پروسه fail میشه یعنی میشه everything or nothing اینطوری ما مطمئن هستیم که دیتابیسمون در استیت درستی قرار داره
وقتی که داریم از ef bundle استفاده میکنیم معادل دستور update database داره عمل میکنه
 اگر داشتیم از linx استفاده میکردیم باید از اون قسمت داخل پرانتز هم استفاده کنیم
اگر داشتیم از linx استفاده میکردیم باید از اون قسمت داخل پرانتز هم استفاده کنیم
اگر توی دستور powershell که efbundle.exe — connection هستش آدرس رو بهش ندیم میره از آدرس که توی application setting تعیین کردیم برای دیتابیس استفاده میکنه
خوب اگر ما یه migration جدید انجام دادیم بعد از این که file رو با efbundle اومدیم و generate کردیم ، در این حالت باید از force استفاده کنیم
با این که این قابلیت ها رو داره ولی بهتره که از طریق کد بیایم این کار هارو انجام بدیم و دونه دونه مراحل رو برسی کنیم
نکته ی جالب اینه که ما میتونیم توی package manager console بیایم از suggestion استفاده کنیم با زدن دکمه ی tab :

خوب یه نکته ای که هست اینه که اگر ما migration رو انجام داده باشیم و روی دیتابیس اعمال شده باشه نمیتونیم remove اش کنیم و برای این کار باید roll back کنیم
وقتی که میخوایم remove کنیم میاد و فایل و دیتابیس رو نگاه میکنه و اگر فقط فایل باشه و روی دیتابیس اعمال نشده باشه میشه پاکش کرد ولی اگر روی دیتابیس اعمال شده باشه نمیشه پاکش کرد و در این حالت باید بیایم و roll back کنیم
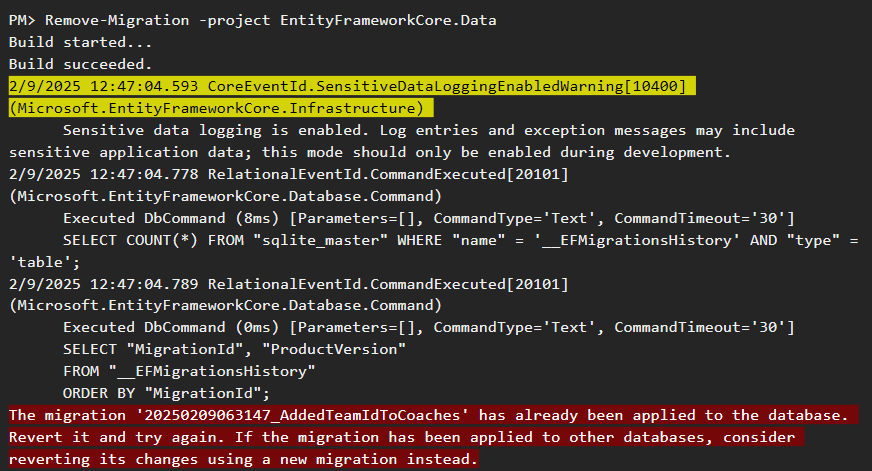
خوب حالا میخوایم roll back کنیم :
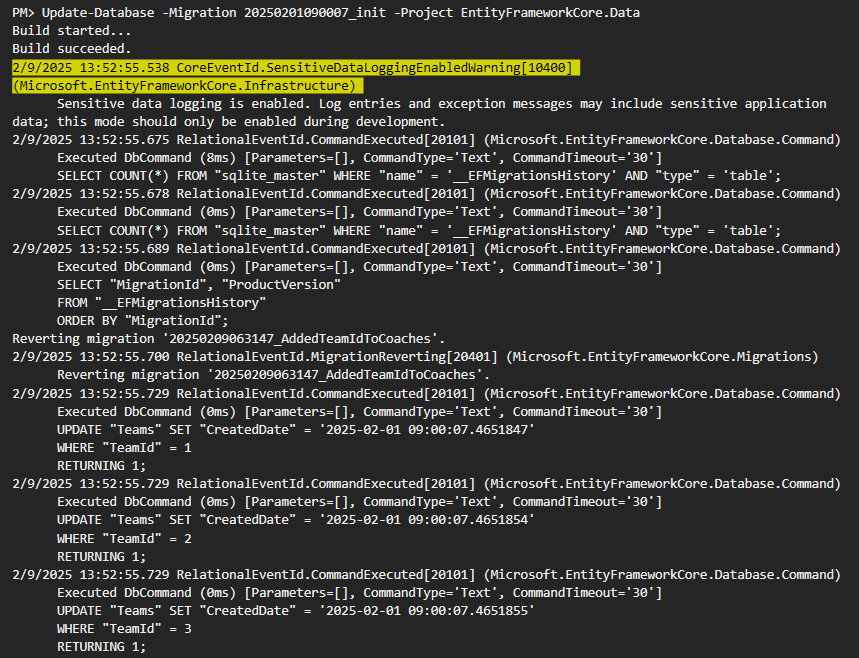 بعدش که get میگیریم میبینیم که Added team id to coach دیگه applied نیست :
بعدش که get میگیریم میبینیم که Added team id to coach دیگه applied نیست :
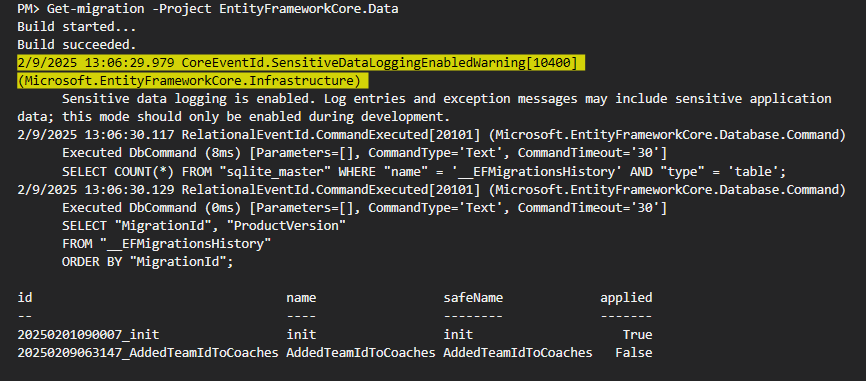
خوب حالا وقتی که دوباره کامند update رو اجرا میکنیم برمیگرده به آخرین migration
 دوباره وقتی که get رو میزنیم
دوباره وقتی که get رو میزنیم


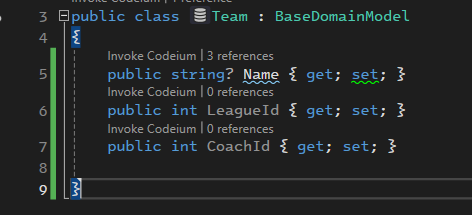
خوب توی این حالت League id و Coach id رو FK در نظر بگیریم
میتونیم از ICollection , Hashset , list استفاده کنیم که همه ی اینا T هستند
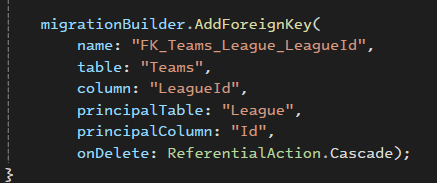
وقتی که داریم از cascade استفاده میکنیم اینطوری میشه که وقتی که مثلا یه league رو پاک میکنیم تمام تیم هایی که داخلش بود هم پاک میشن

خوب برای کنترل تغییرات در دیتا بیس باید این رو بدونیم که هر تغییری که ما توی entity مون یا توی db context مثلا اضافه کردن یه configuration یا کار های دیگه تمامی این تغییرات میاد با اون فایل snap shot مقایسه میشه و تغییرات به وجود اومده اگر مورد تایید ef بود میاد فایل migration رو درست میکنه که حاوی action هایی هست که بیاد این تغییرات رو به وجود بیاره
این تغییرات هم با دستور update انجام میشه و یه قابلیت دیگه که داره اینه که میتونیم roll back هم کنیم این قابیلیت رو بهمون میده که تغییرات رو track کنیم در با استفاده از source control ها و این که در دیتابیس ها هم track میشه این تغییرات در ef migration history
هر موقع که بخوایم یه دیتابیس جدید درست کنیم اون connection string رو عوض میکنیم و همه چی حل میشه

معنی این ارور اینه که توی کلاس team یه فیلدی هست که not nullable هستش و ما داریم وقتی که seed میکنیم توی دیتابیس این فیلد رو هیچ مقداری براش نداشتیم و این که وقتی که not nullabe نیست حتما باید بهش مقدار بدیم ولی فعلا بهش ? رو میدیم تا ارور حل بشه
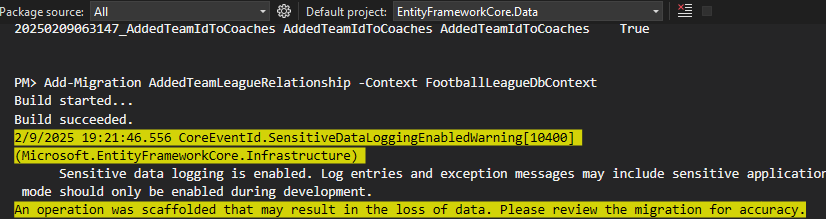
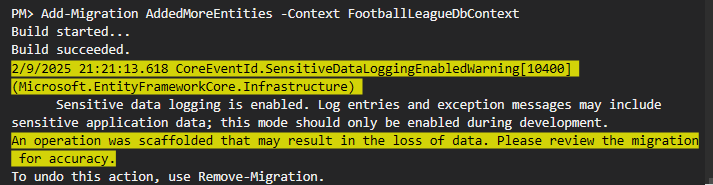 خوب اینجا گفته که ممکنه یه سری از دیتا ها از بین برن و دلیلش اینه که ما اومدیم Team id رو به id تغییر دادیم
خوب اینجا گفته که ممکنه یه سری از دیتا ها از بین برن و دلیلش اینه که ما اومدیم Team id رو به id تغییر دادیم


خوب اون ارور قرمز قبلش این ارور زرد رنگ رو داره مینویسه ، برای حل این مشکل باید بیایم این کار رو کنیم باید بیایم توی چند مرحله این کار رو انجام بدیم و با یک migration نمیشه باید با چند تا migration انجامش بدیم


خوب به خاطر این که دیتا توی دیتابی داریم که براساس همون پارامترهای قبلی ست شده این ارور رو میگیریم
خوب تمامی اطلاعات توی دیتابیس رو پاک کردم ومشکل حل شد
خوب حالا اینطوری میشه که بعد از تمامی این داستان ها تازه باید بریم و فیلد Team id رو پاک کنیم و دوباره migration رو انجام بدیم و بعد آپدیت کنیم
 خوب حالا میخوایم از config استفاده کنیم :
خوب حالا میخوایم از config استفاده کنیم :
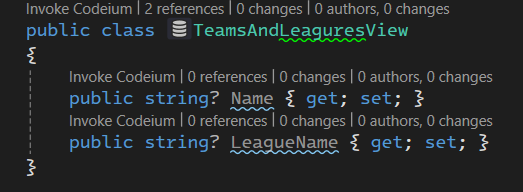
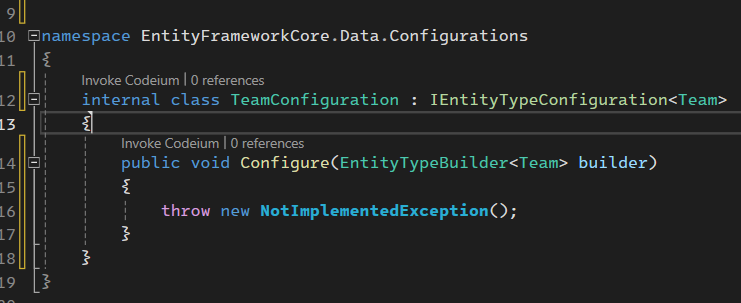 خوب اینجا internal در نظر گرفتیم چون فقط داخل همین پروژه استفاده میشه و این که بعدش میایم IEntity type Configuration رو ارث بری میکنیم و بعد تعیین میکنیم که این تنظیمات رو برای کدوم کلاس میخوایم تنظیم کنیم که اینجا team هستش
خوب اینجا internal در نظر گرفتیم چون فقط داخل همین پروژه استفاده میشه و این که بعدش میایم IEntity type Configuration رو ارث بری میکنیم و بعد تعیین میکنیم که این تنظیمات رو برای کدوم کلاس میخوایم تنظیم کنیم که اینجا team هستش
اون builder که در بالا داریم دقیقا مشابه با همین builder هستش
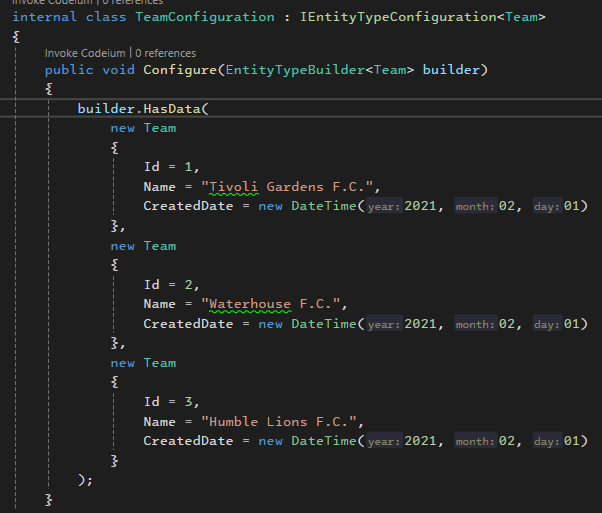 با اون builder کارهای زیادی میتونیم انجام بدیم :
با اون builder کارهای زیادی میتونیم انجام بدیم :


خوب حالا اینجا داریم میگیم که همون اول که داری ساخته میشی این تنظیمات رو از team configuration بردارد و apply کن
 خوب حالا ممکنه که ما 50 تا دیگه کلاس داشته باشیم که بخوایم تنظیمات رو روش انجام بدیم و به جای این که هر 50 تا رو بیایم اینجا بنویسیم از apply configuration from assembly استفاده میکنیم که این متد میاد و کل assembly رو میگرده و هرجایی که اینترفیس IEntity type configuration رو داشته باشه میره اون رو پیاده سازی میکنه
خوب حالا ممکنه که ما 50 تا دیگه کلاس داشته باشیم که بخوایم تنظیمات رو روش انجام بدیم و به جای این که هر 50 تا رو بیایم اینجا بنویسیم از apply configuration from assembly استفاده میکنیم که این متد میاد و کل assembly رو میگرده و هرجایی که اینترفیس IEntity type configuration رو داشته باشه میره اون رو پیاده سازی میکنه

خوب حالا میخوایم بیینیم که Sql که برای این migration استفاده میکنیم چجوریه ؟
برای فهمیدنش

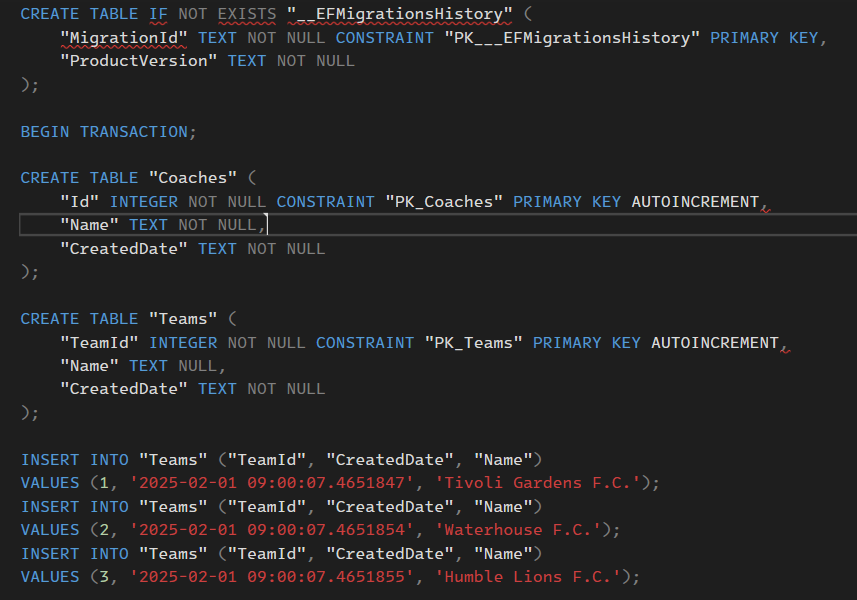 خوب در سطر اول داره میگه که اگر EFmigrationHistory وجود نداشت بسازش
نکته ی بعدی اینه که از نوع transaction هستش
خوب در سطر اول داره میگه که اگر EFmigrationHistory وجود نداشت بسازش
نکته ی بعدی اینه که از نوع transaction هستش
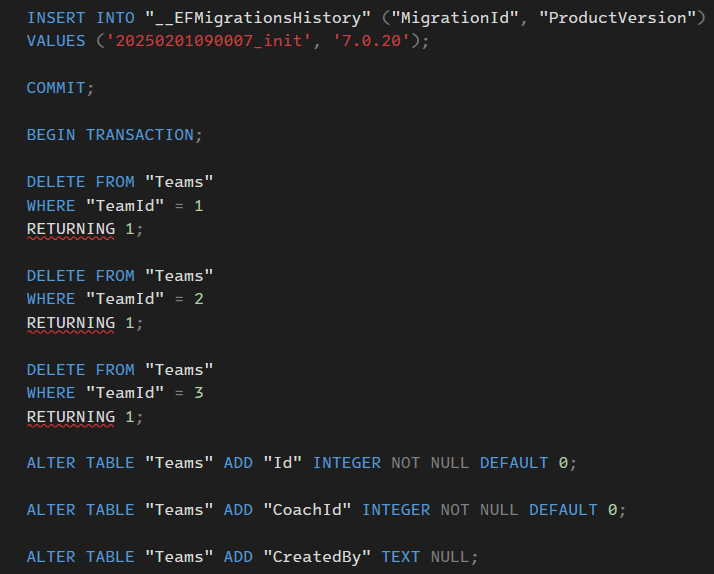 در این تصویر بالا هم میگه که ef migration history رو آپدیت کن و بعد commit کن حالا migration بعدی با یک transaction جدید شروع میشه و همینطوری ادامه پیدا میکنه
در این تصویر بالا هم میگه که ef migration history رو آپدیت کن و بعد commit کن حالا migration بعدی با یک transaction جدید شروع میشه و همینطوری ادامه پیدا میکنه
خوب موردی که هست اینه که اگر توی هرکدوم از این transaction ها دیتا وجود داشته باشه fail میشه و میره بعدی یعنی هر کدوم از transaction ها fail بشه میره بعدی رو اجرا میکنه
خوب به همین دلیل ما میتونیم یه چیزی رو اضافه کنیم بهش به اسم idempotent که میاد اول چک میکنه و میبینه اگر دیتاش وجود نداشته باشه یا اون تغییر ایجاد نشده باشه میاد اون رو اجرا میکنه

خوب البته این رو دقت داشته باشید که این قابلیت برای sqlite وجود نداره و به ارور میخوریم
اینجا فرقش اینه که با اون if میاد چک میکنه - البته این رو از یه پروژه دیگه هستش
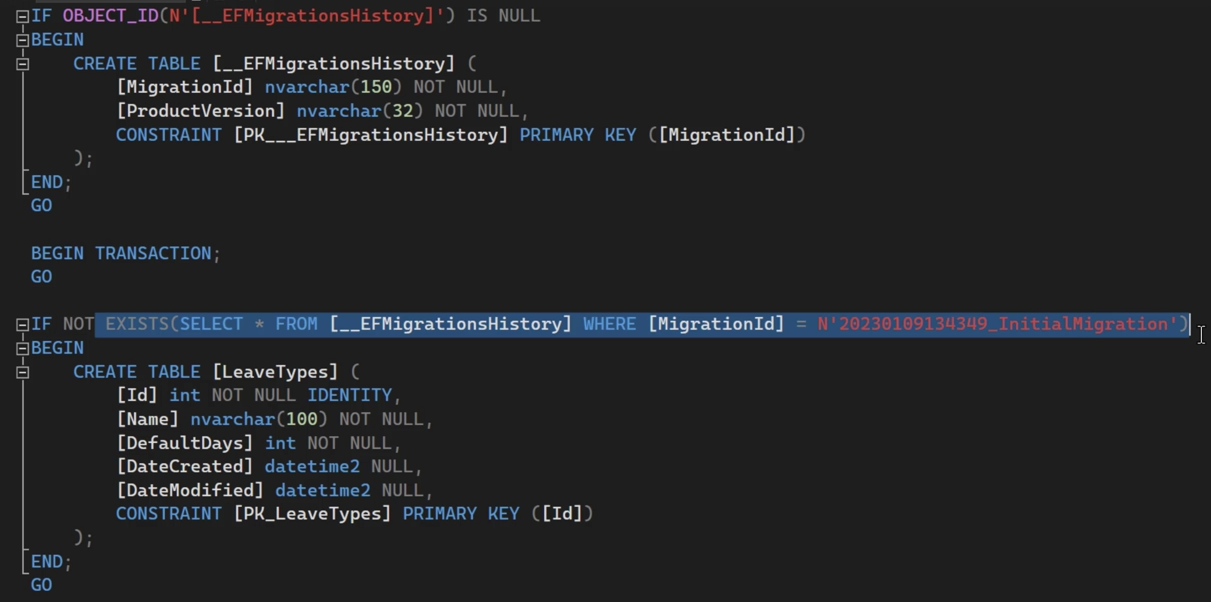
حتی میتونیم برای استفاده از idempotent بیایم range بدیم بهش اینطوری :



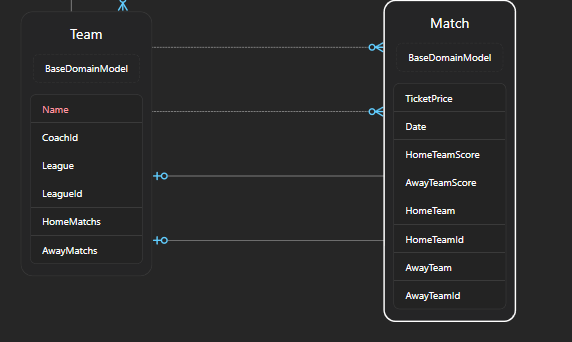
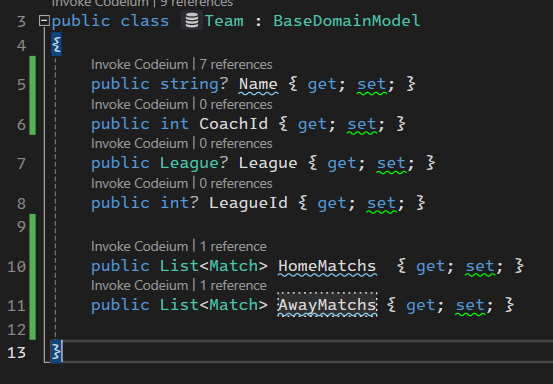
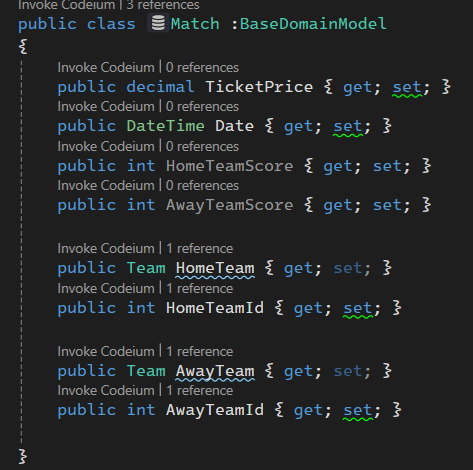
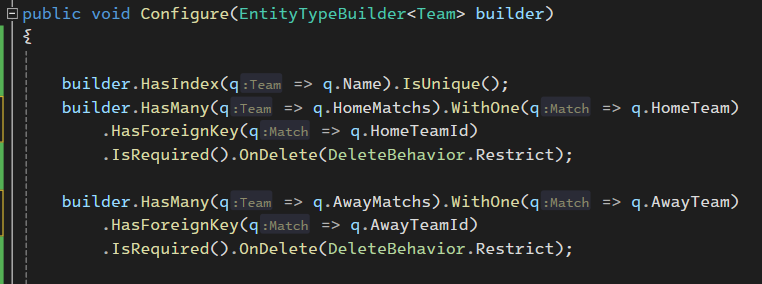
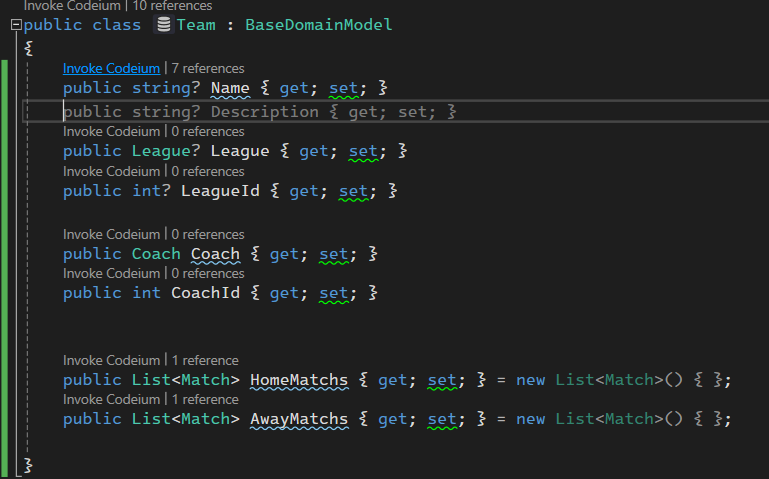
خوب اینجا برای ارتباط many to many باید چند تا ارتباط یک به چند داشته باشیم، که در اینجا میشه ارتباط HomeTeam در Match با یک team و ارتباط AwayTeam در Match با یک تیم دیگه و از اون سمت ارتباط یک تیم با چندین match که Home یا Away هستن
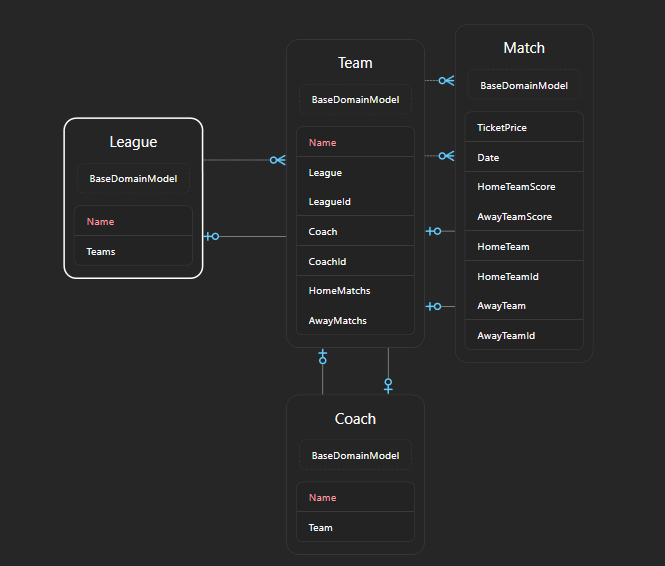

وقتی که داریم روابط رو تعیین میکنیم شبیه به parent child هستش حالا اینجا به طور مثال میایم و coach رو به عنوان parent قرار میدیم
قابلیتی که داریم اینه که در هر دو طرف navigation رو داریم ولی در یک طرف میتونیم FK رو قرار بدیم که دسترسی مستقیم به اون یکی داره
یه حالت دیگه اینه که یک سمت navigation رو داریم و در یک سمت FK رو داریم که اینجا ef میاد از shadow propery ها استفاده میکنه
یه حالت دیگه هم اینه که هر دوطرف هم navigation رو دارن و هم FK رو ولی در این حالت باید بریم و توی config خودمون این رو تنظیم کنیم
حالا برای پیاده سازی بهتره که بیایم یه لیست خالی رو قرار بدیم توی proprty مون که به ارور نخوریم:
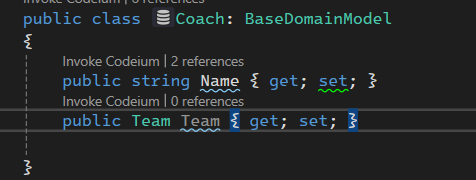 در اینجا درسته که TeamId نداریم ولی خوده Ef با استفاده از shadow proprty یه FK رو برای دسترسی به اون تیمی که داخل کلاس Coach هستش رو بهمون داره میده و داره trace میکنه
در اینجا درسته که TeamId نداریم ولی خوده Ef با استفاده از shadow proprty یه FK رو برای دسترسی به اون تیمی که داخل کلاس Coach هستش رو بهمون داره میده و داره trace میکنه
نکته ی مهمی هست اینه که اگر به طور مثال ما دو تا MIGRATION داشتیم باشیم و بخوایم با هم این دو تا رو APPLIED کنیم اگر بین این دو تا تغییری باشه به ارور میخوریم به طور مثال توی اولی یه پراپرتی رو توی migration اولی اومدیم nullabe کردیم و توی migration دومی اومدیم not nullable کردیم و همین باعث ارور میشه برای همین بهتره که هر بار migration رو add میکنیم بعدش update رو انجام بدیم و بعد بریم سراغ migration بعدی
حالا یه ارور دیگه که ممکنه بهش بربخوریم اینه که ما ساختار رو تغییر دادیم و بر اساس ساختار جدید دیتایی که همین الان توی دیتابیس هستش دچار مشکل میشه و با این ساختار نمیخونه و برای همین هم به ارور میخوریم و برای رفع ارور میایم همشون رو پاک میکنیم
خوب حالا میخوایم دیتاهایی که بهم وصل هستند رو seed کنیم قبلش باید یه نکته ای رو مد نظر داشته باشیم اونم اینه که اگر ما یه بار اومدیم با استفاده از برنامه دیتایی رو روی دیتابیس نوشتیم این دیتا در migration ثبت شده و وقتی که به هر علتی میایم کل دیتابیس یا قسمتی از اون دیتا رو پاک میکنیم دیگه در migration های بعدی اون دیتا ساخته نمیشه و باید اگر میخوایم که دیتایی دوباره از همون رو seed کنیم باید بیایم تغییرش بدیم این طوری این تغییرات شناسایی میشن و بعد هم اعمال میشن
نکته ی مهمتر اینه که نه آپدیت نمیشن چون وقتی که داریم seed میکنیم همچنان میره و توی migration ها رو میبینه و بعد میبینه که این دیتاها با این آیدی ها وارد شدن و بعد این که این دیتاها به صورت دستی و از داخل خوده دیتابیس پاک شدن رو نمیبینه و بعد دستور بعدی که میخواد بزنه رو میگه که این مقادیر باید آپدیت بشن در صورتی که اصلا دیتا وجود نداره که بخواد آپدیت بشع و باید از اول seed بشه ولی این رو نمیتونه تشخیص بده. دقت داشته باشیم که اینجا snap shot وضعیت فعلی دیتابیس رو تعیین میکنه و مقایسه ها و تغییرات با اون انجام میشه
خوب برای این که یه تغییر ساختار رو انجام بدیم و دوباره دیتاها رو seed کنیم باید بیایم جدول ها با دیتاهای داخلوشن را پاک کنیم
خوب نکته ی تکمیلی اینه که میاد در حقیقت با snapshot چک میکنه و وقتی که میخوایم این کارو انجام بدیم میایم و snapshot و table هایی که درست شده رو پاک میکنیم به همین دلیل میگن برای این که به این مشکلات کمتر بخوریم از ensure delete , ensute create استفاده کنیم که یه بار کل دیتا ها و جدول های ساخته شده پاک بشن و دوباره ساخته بشن که کمتر به مشکل بخوریم
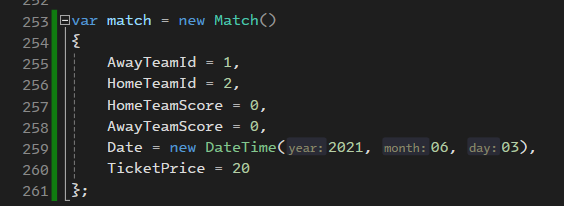
خوب حالا میخوایم که بیایم اطلاعاتی که بهم مرتبط هستند رو هم وارد جدول کنیم : خوب اینجا اتفاقی که میوفته اینه که اولی وارد دیتابیس میشه ولی دومی به دلیل این که ما team id که 10 باشه رو نداریم پس به ارور میخوره :
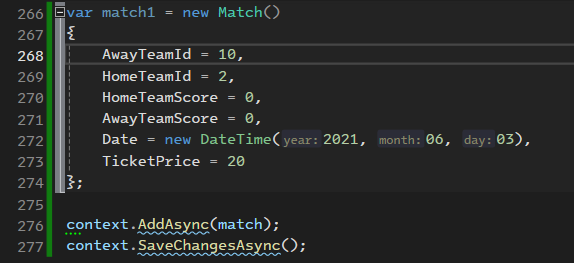
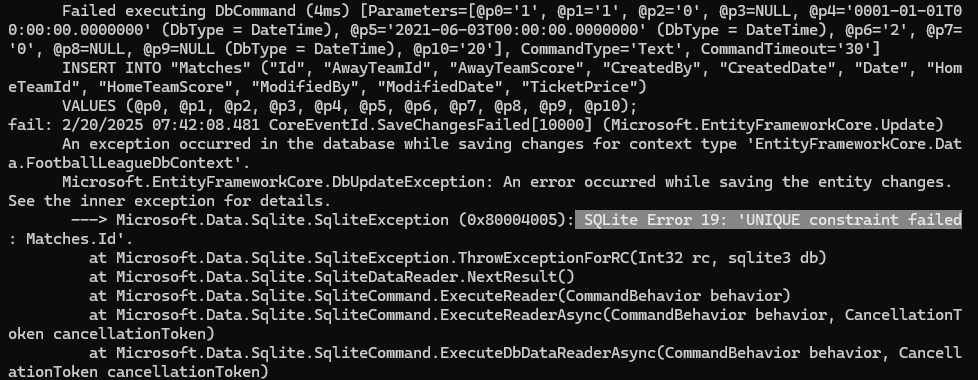
خوب حالا میخوام parent , child رو در یک زمان مقدار بدیم مثلا میخوایم یه تیمی رو اضافه کنیم و همون موقع میخوایم یه coach رو هم بهش بدیم که تا حالا توی دیتابیس نبوده
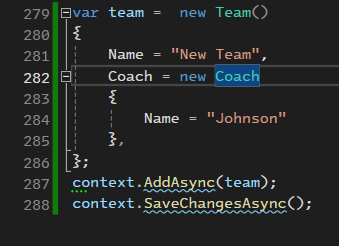
 خوب اینجا دقت کنیم که اول میاد و coach رو insert data اش رو انجام میده و بعد میاد تیم رو وارد میکنه
خوب اینجا دقت کنیم که اول میاد و coach رو insert data اش رو انجام میده و بعد میاد تیم رو وارد میکنه
این جا هم به صورت سلسله مراتبی میایم و دیتا رو واردش میکنیم : نکته ای که اینجا داره اینه که اگر یک دیتایی داخل اینها اشتباه باشه هیچکدوم از این اطلاعات داخل دیتابیس ثبت نمیشه
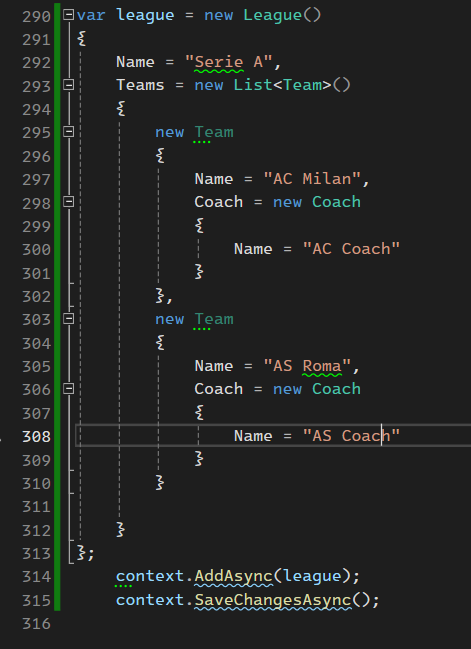
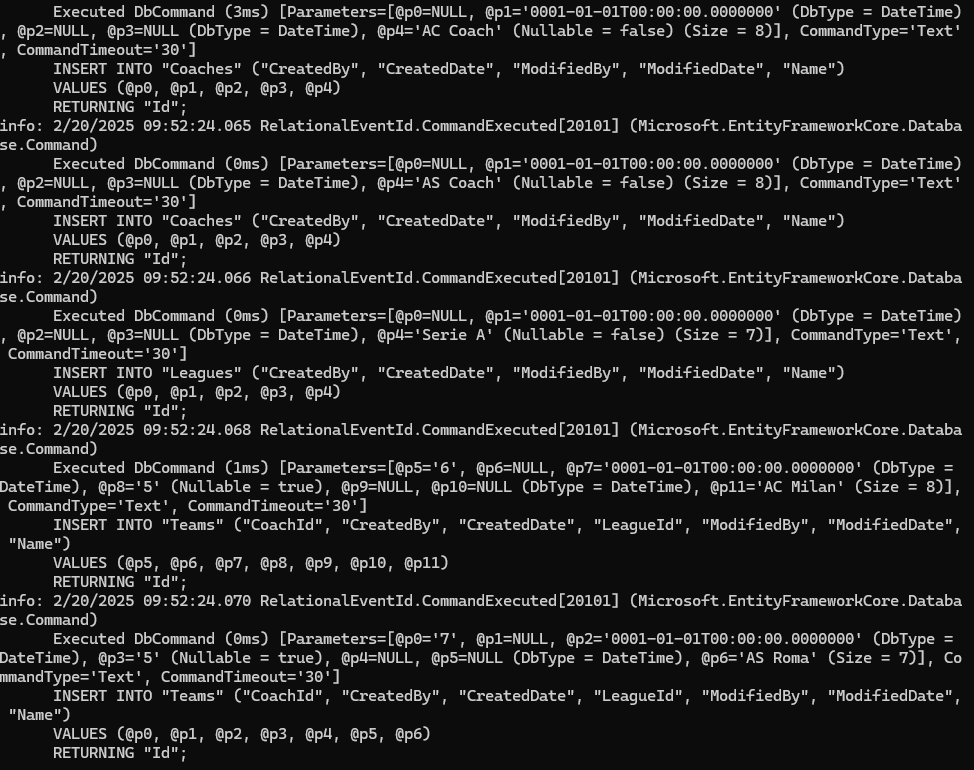 خوب اینجا طبق کوئری ها هم میبینیم که اول میاد coach رو درست میکنه بعد Leauge رو درست میکنه و بعد در آخر Team رو درست میکنه
خوب اینجا طبق کوئری ها هم میبینیم که اول میاد coach رو درست میکنه بعد Leauge رو درست میکنه و بعد در آخر Team رو درست میکنه
حالا چرا به این ترتیب این کار رو میکنه خوب وقتی که میخواد یک تیم رو وارد کنه قبلش باید مربی باشه که بتونه اون رو وارد کنه، حالا این رو باید داشته باشیم که اینجا ما به لیگ هر کدوم از تیم ها هم مقدار دادیم پس اتفاقی که میوفته اینه که باید اول لیگ رو بسازه و در آخر بیاد تیم های لیگ رو با مربیشون بسازی و ef خودش سلسه مراتب رو تشخصی میده

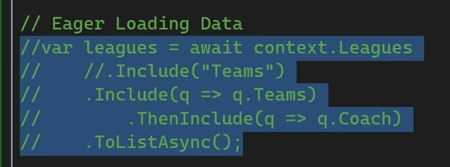
برای eager loading خوانده شود : https://virgool.io/@ehsan.tabakhian/eager-loading-%D8%AF%D8%B1-entityframework-core-af7yqg0pty32
 خوب اگر بخوایم حالت query synthax استفاده کنیم میتونیم از join استفاده کنیم اگر بخوایم از method syntax استفاده کنیم میایم از include استفاده میکنیم :
خوب اگر بخوایم حالت query synthax استفاده کنیم میتونیم از join استفاده کنیم اگر بخوایم از method syntax استفاده کنیم میایم از include استفاده میکنیم :
خوب وقتی که بخوایم برای لود کردن دیتا که به صورت collection هستش یا navigation property که پایه و اصلش collection هستش برای ما مشکلات performance ای به وجود میاره برای همین هم یه متد دیگه براش در نظر گرفتن به اسم AsSplitQuery رو داریم که این معنی رو میده که نمیخواد کل دیتارو توی یه کوئری بگیره و بیاره و بره تیکه تیکه دیتاها رو بیاره و بعد بهم بچسبونتش و بعد تحویلشون بده و این قضیه بهمون در افزایش کارایی کمک میکنه مخصوصا زمانی که دیتای حجیم داریم خوب ما میتونیم روی include از Where استفاده کنیم و دیتاهایی که میخوایم رو فیلتر کنیم
اگر tracking فعال باشه و ما یه دیتایی رو با include بخوایم و اون دیتا توی مموری track شده باشه با eager loading اون میاد اون دیتا رو برمیگردونه به ما و این ممکنه برای ما مشکل به وجود بیاره چرا که شاید ما دستی توی خوده دیتابیس اون رو تغییر دادیم و اون ورژنی از دیتا رو بهمون میده که غلط هستش
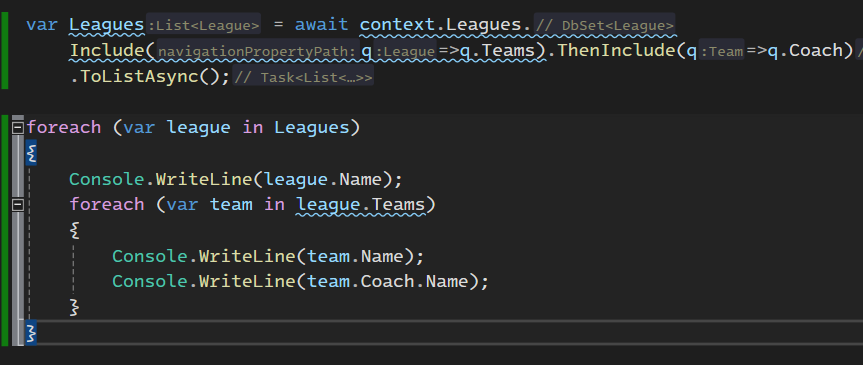
برای که ما level ها و روابط مختلف داریم میتونیم از then include هم استفاده کنیم میتونیم اول league رو بیاریم و بعدش Team رو بیاریم و بعد coach رو بیاریم.
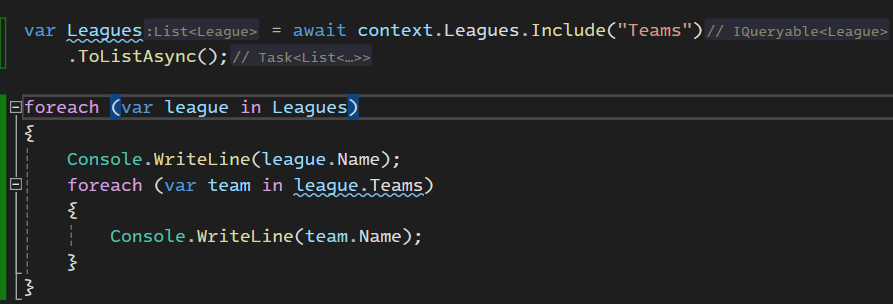
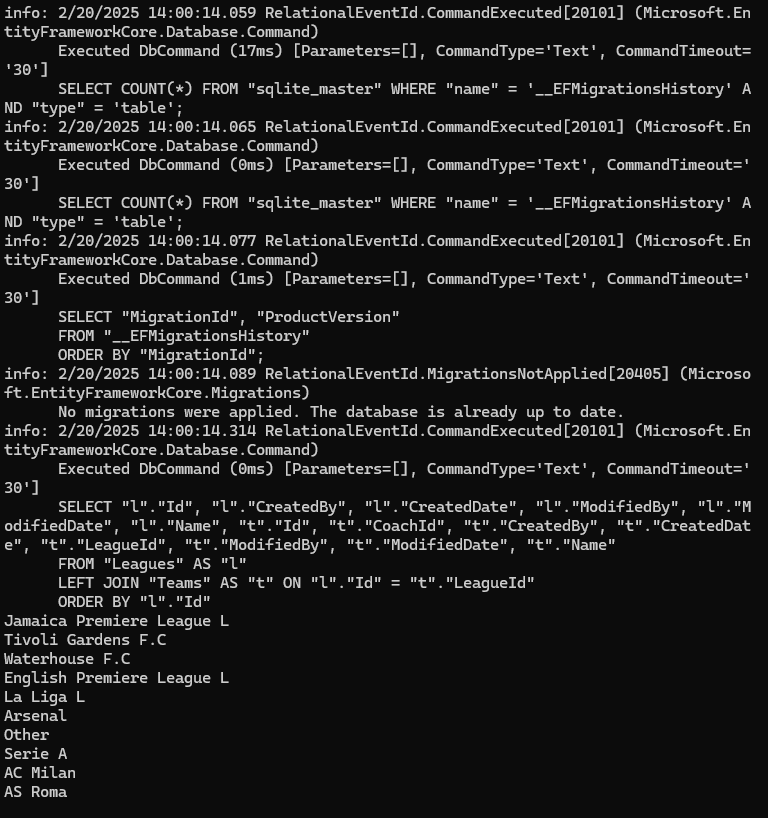
خوب اینجا چون اومدیم و از include استفاده کردیم اومده و join رو انجام داده دو تا راه داریم برای استفاده از include یکیش استفاده از string هستش و یکی هم استفاده از lambda expression

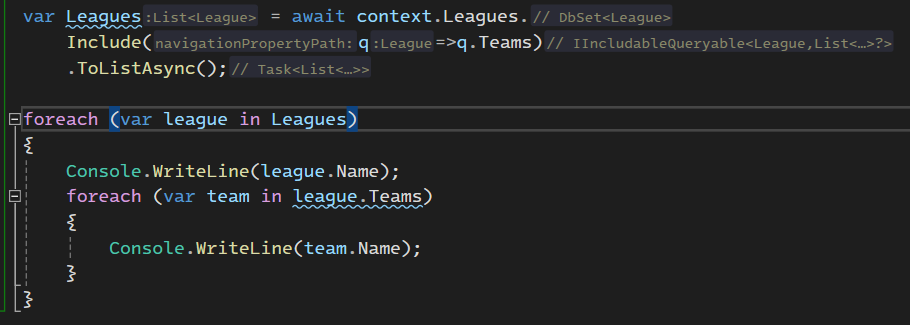
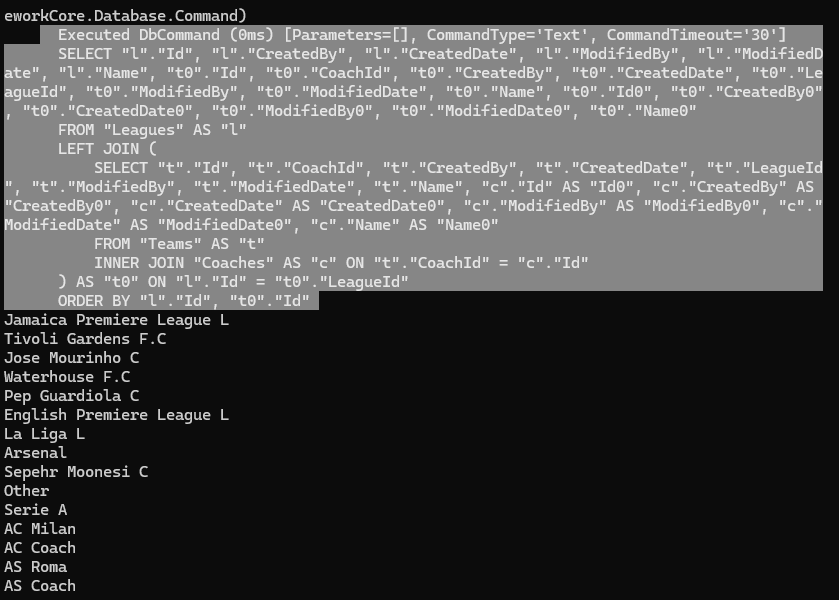
 اینجا 3 تا جدول رو با هم join داره میزنه
اینجا 3 تا جدول رو با هم join داره میزنه
اگر بخوایم به یه پارامتری دسترسی پیدا کنیم ولی از include استفاده نکنیم به ارور null exception برمیخوریم
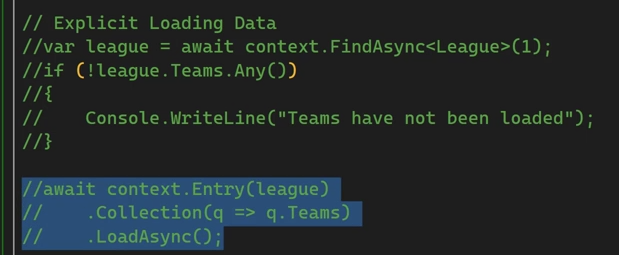
خوب وقتی که داریم از DbContext.Entry استفاده میکنیم دیتا ها با استفاده از query میاریم و لود میکنیم و اگر change tracking فعال باشه اگر ما navigation property اون entity جدیدی که لود شده رو refer میده به همون entity که در حال حاضر لود شده

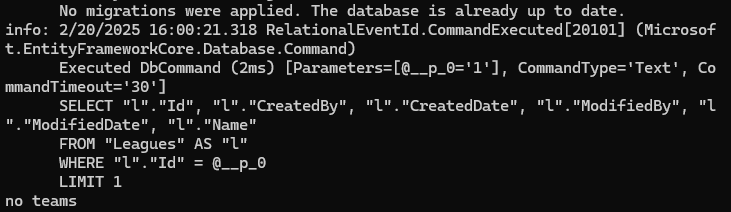
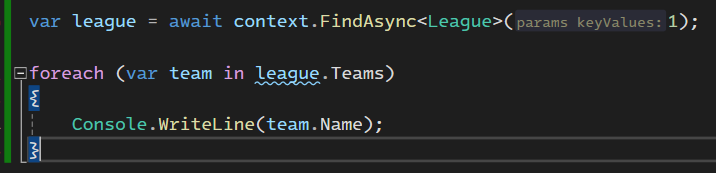
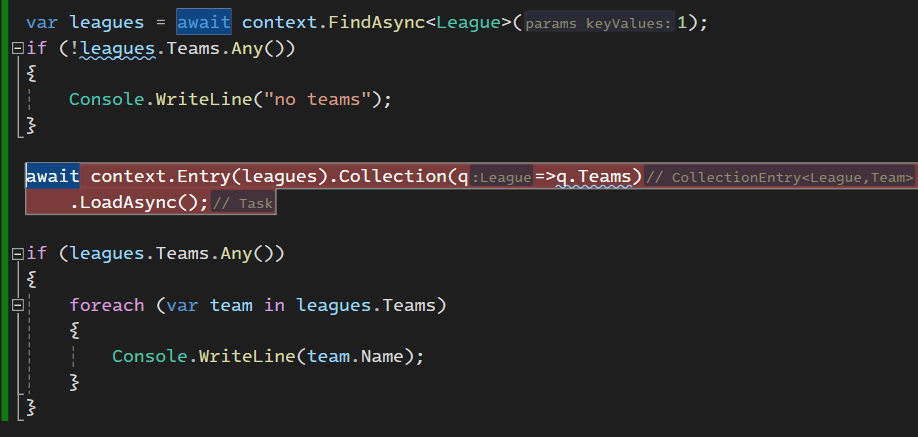 خوب اینجا در مرحله اول میریم و فقط league اولی رو میاریم ولی وقتی که میاریمش دیگه تیمی داخلش نیست.
خوب اینجا در مرحله اول میریم و فقط league اولی رو میاریم ولی وقتی که میاریمش دیگه تیمی داخلش نیست.
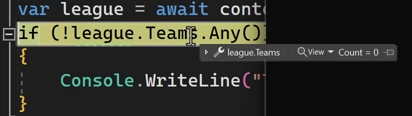
 در مرحله ی بعدی که break point هم گذاشتیم میایم و دیتای تیم ها رو لود میکنیم و میاریم توی league
در مرحله ی بعدی که break point هم گذاشتیم میایم و دیتای تیم ها رو لود میکنیم و میاریم توی league
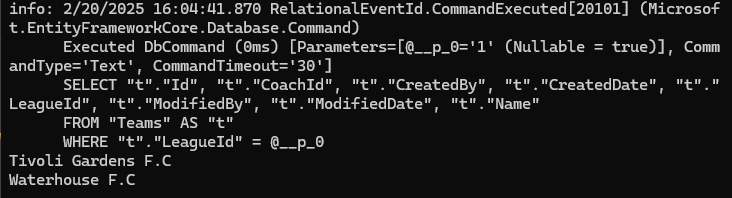
توی کوئری نوشته شده که تیم هایی که با اون league id منطبق هستند رو دیتاشون رو بیاره
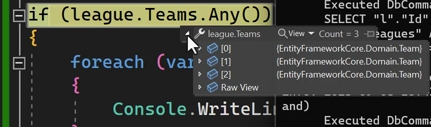
خوب اینجا دقت کنید که ما اول league رو اوردیم و بعد اومدیم به همین لیگی که آوردیم ، اومدیم تیم ها رو هم از دیتابیس اوردیم و لیگ رو اطلاعاتش رو تکمیل کردیم و دلیلی که میتونیم این کارو بکنیم اینه که داریم از tracking استفاده میکنیم
این قابلیت خیلی خوبه چون ما هر جا که بخوایم و با هر شرطی میتونیم دیتا هایی که لازم داریم رو قسمت قسمت بریم و بیاریم ولی در حالت eager میره همون اول کل دیتا رو برمیداره و میاره
خوب حالا میرسیم به lazy loading

خوب برای توضیح مورد چهارم ، اینطوریه که میایم یه navigation property رو لود میکنیم که اون میاد یه چیزه دیگه رو لود میکنه و بعد دوباره اون میاد یه چیزه دیگه رو لود میکنه و… و ما کنترل کمی داریم روی اون کاری که داره انجام میده به صورت کلی هم پیشنهاد نمیشه

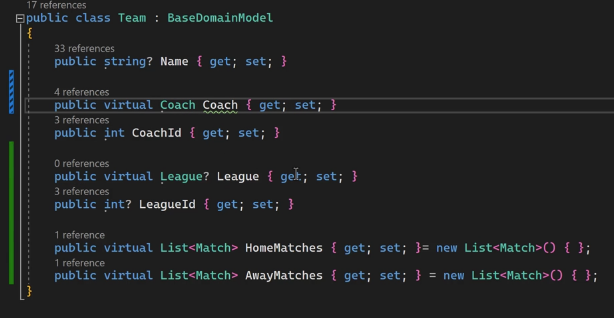
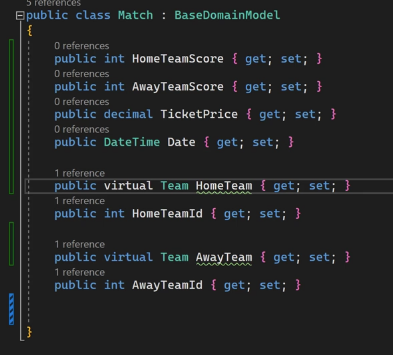
هر چیزی که virtual و داشته باشه یا access modifer شو داشته باشه میتونیم توی کلاس مشتق شده ازش بیایم و اون رو overriden کنیم
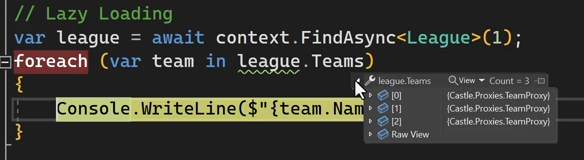
نکته:
 اگر اینطوری از context.Leagues استفاده کنیم توی هر itrate خوده dbcontext میره و دیتا رو میاره
اگر اینطوری از context.Leagues استفاده کنیم توی هر itrate خوده dbcontext میره و دیتا رو میاره
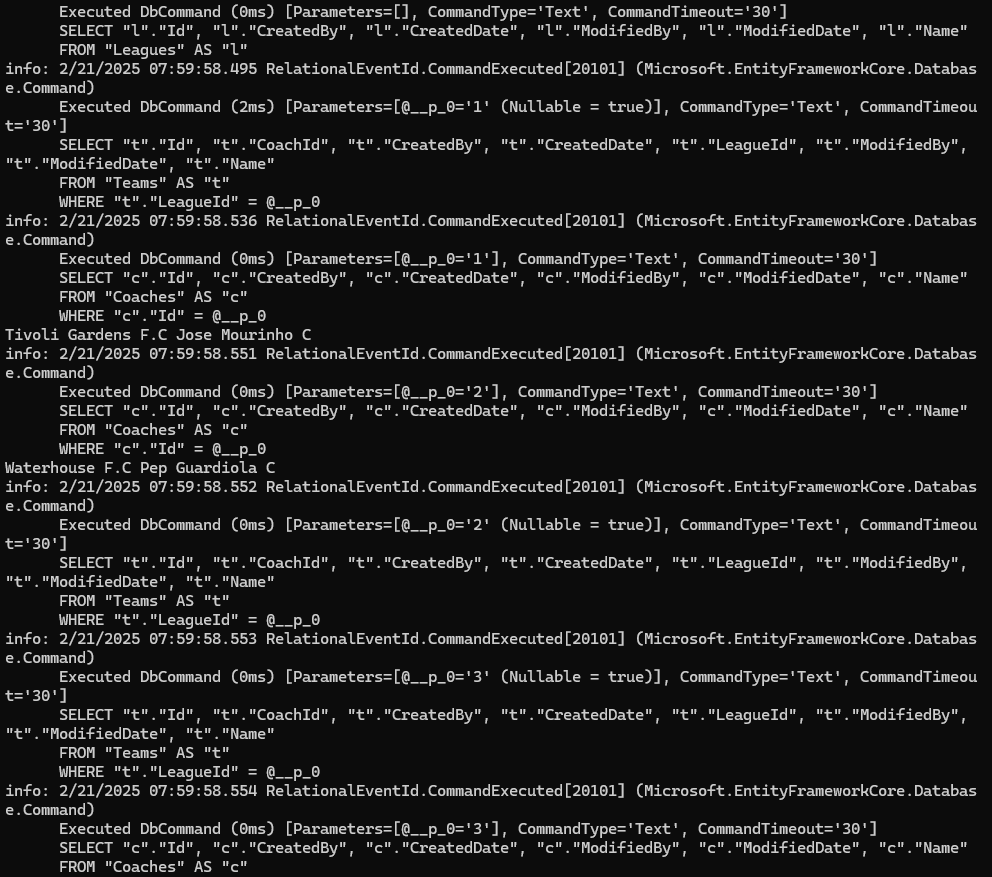
خوب در این حالت کوئری هایی که زده شده تعدادشون خیلی بیشتره
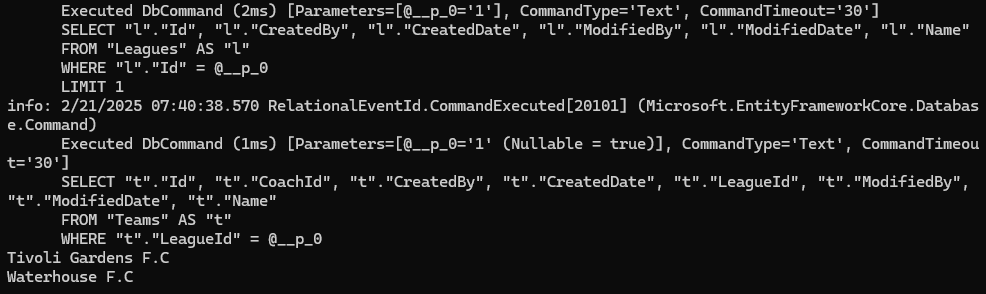
اولین کوئری داره میگه که کل league ها رو بهم بده :

وقتی که بخوایم بریم توی هر لیگ و بخوایم هر تیم رو lazy load کنیم هم باید یه کوئری بزنیم
 و در مرحله ی بعد چون میخوایم به coach با استفاده از lazy loading برسیم ، دوباره یه کوئری میزنیم :
و در مرحله ی بعد چون میخوایم به coach با استفاده از lazy loading برسیم ، دوباره یه کوئری میزنیم :
 و برای همه تیم ها این قضیه تکارا میشه و در این حالت اتفاقی که میوفته اینه که تعداد کوئری ها و رفت و آمد کردن به دیتابیس زیاد میشه که این به صورت کلی مناسب نیست ، چرا که با تعداد کوئری کمتر و دقیق تر میتونیم این دیتاها رو بدست بیاریم و ازشون استفاده کنیم
و برای همه تیم ها این قضیه تکارا میشه و در این حالت اتفاقی که میوفته اینه که تعداد کوئری ها و رفت و آمد کردن به دیتابیس زیاد میشه که این به صورت کلی مناسب نیست ، چرا که با تعداد کوئری کمتر و دقیق تر میتونیم این دیتاها رو بدست بیاریم و ازشون استفاده کنیم
 خوب در کد بالا یه نکته ای وجود داره اینه که اگر یه تمی باشه که هیچ match ای نداشته باشه اونجا به ارور null میخوریم ، حالا اگر از first or defualt هم استفاده کنیم توی اون قسمت اول اورور نمیده ولی در قسمت بعدش که میخود homeTeamScore رو مقایسه کنه اونجا ارور میخوریم چون میخواد null رو با صفر مقایسه کنه و نکته ی دیگه اش اینه که where اینجا میاد تیم هارو filter میکنه و نمیتونه بیاد تمام تیم هایی که Home match شون امتیاز گرفته رو بیاره
خوب در کد بالا یه نکته ای وجود داره اینه که اگر یه تمی باشه که هیچ match ای نداشته باشه اونجا به ارور null میخوریم ، حالا اگر از first or defualt هم استفاده کنیم توی اون قسمت اول اورور نمیده ولی در قسمت بعدش که میخود homeTeamScore رو مقایسه کنه اونجا ارور میخوریم چون میخواد null رو با صفر مقایسه کنه و نکته ی دیگه اش اینه که where اینجا میاد تیم هارو filter میکنه و نمیتونه بیاد تمام تیم هایی که Home match شون امتیاز گرفته رو بیاره

راه درستش اینه که بیایم اول تمامی تیم هارو بیاریم با مربی هاشون و بعد بریم توی Home match شون و بعد بیایم مقایسه رو انجام بدیم
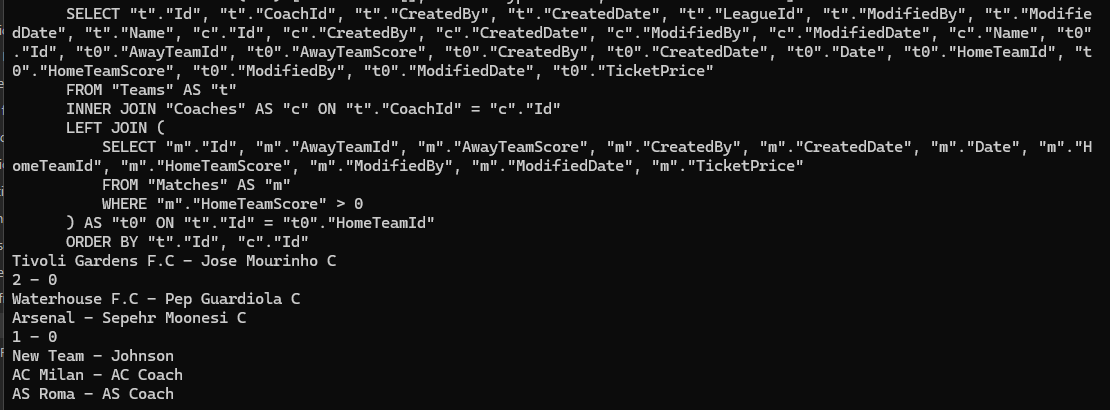
خوب حالا بین coach در این کوئری inner join زده این یعنی این که اگر یک تیمی coach نداشه باشه اصلا اون دیتاش رو نمیاره
حالا میرسیم به بحث projection , anonymous type
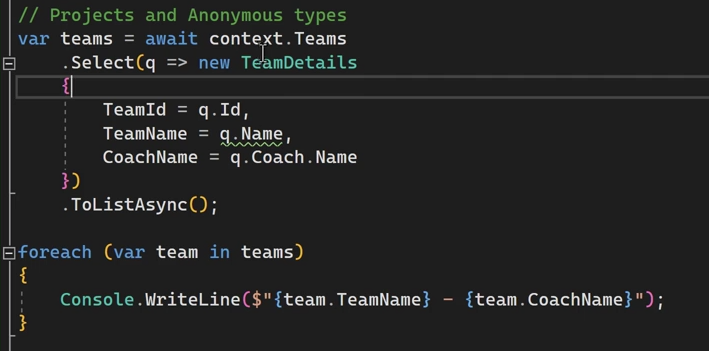
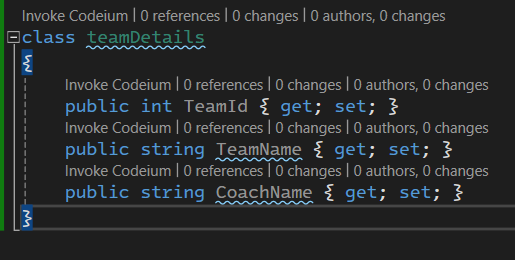 خوب حالا ما میخوایم به جای این که کل جزییات team رو از دیتابیس بگیریم و بیاریم فقط میایم اطلاعات لازم داریم رو تعیین میکنیم و براش یه کلاس جدید میسازیم و بعد میایم از projection استفاده میکنیم
خوب حالا ما میخوایم به جای این که کل جزییات team رو از دیتابیس بگیریم و بیاریم فقط میایم اطلاعات لازم داریم رو تعیین میکنیم و براش یه کلاس جدید میسازیم و بعد میایم از projection استفاده میکنیم
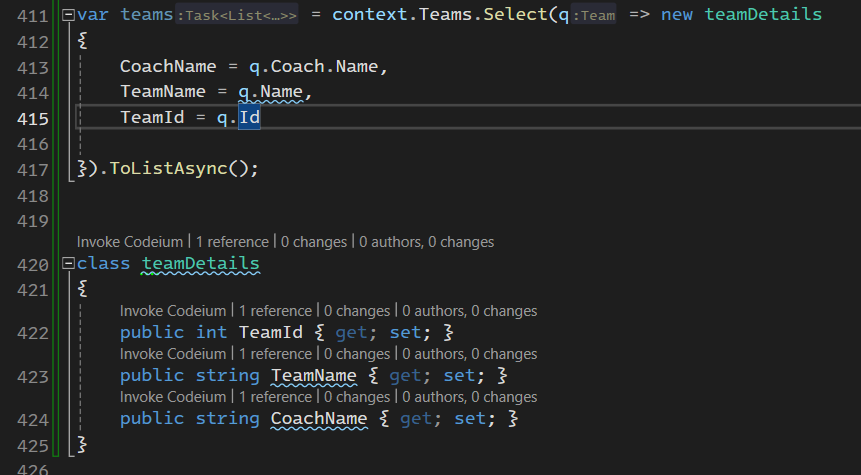 خوب اینجا یه نکته ی خیلی مهم داره اونم اینه که دیگه اینجا نیازی نداریم که از include استفاده کنیم ، اینجا به طور مثال درسته که ما include رو نزدیم برای رسیدن و لود کردن اسم coach و خوده ef این کارو در این پروسه برای ما انجام میده
خوب توی کوئری خودش بدون این که ما بیایم و از include استفاده کنیم اومده و inner join زده و دیتای coach رو اورده
خوب اینجا یه نکته ی خیلی مهم داره اونم اینه که دیگه اینجا نیازی نداریم که از include استفاده کنیم ، اینجا به طور مثال درسته که ما include رو نزدیم برای رسیدن و لود کردن اسم coach و خوده ef این کارو در این پروسه برای ما انجام میده
خوب توی کوئری خودش بدون این که ما بیایم و از include استفاده کنیم اومده و inner join زده و دیتای coach رو اورده
نکته ی مهمی که هست اینه که فقط به اون اطلاعاتی که نیاز داشتیم رو در کوئری select زده و آورده و کلشون رو نیورده
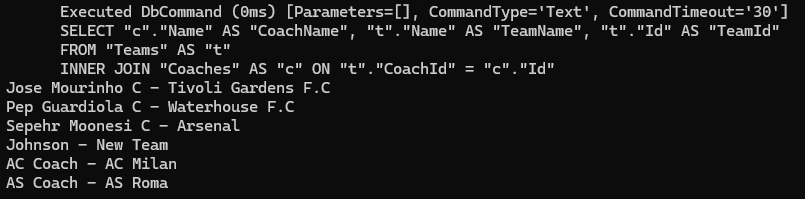
حالا یه تغییری رو انجام میدیم :
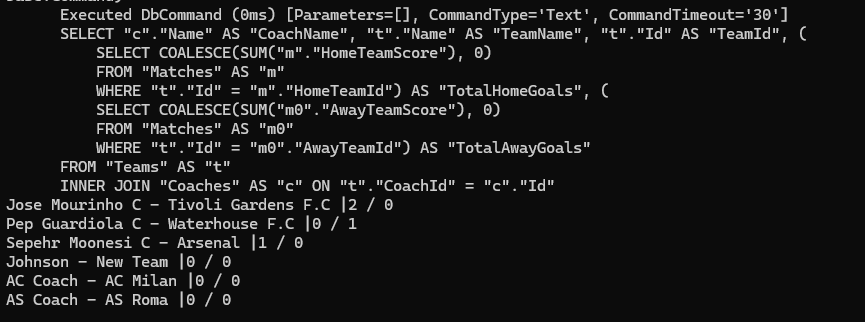 اینجا اون قسمتی که داره از Coalesce داره استفاده میکنه یعنی این که مقدار sum اون چیزی که توی پرانتز هستش رو حساب کن و بده بهم و حالا اگر null شد نتیجه اش اون null رو تبدیلش کن به 0 که ازش استفاده کنیم
اینجا اون قسمتی که داره از Coalesce داره استفاده میکنه یعنی این که مقدار sum اون چیزی که توی پرانتز هستش رو حساب کن و بده بهم و حالا اگر null شد نتیجه اش اون null رو تبدیلش کن به 0 که ازش استفاده کنیم

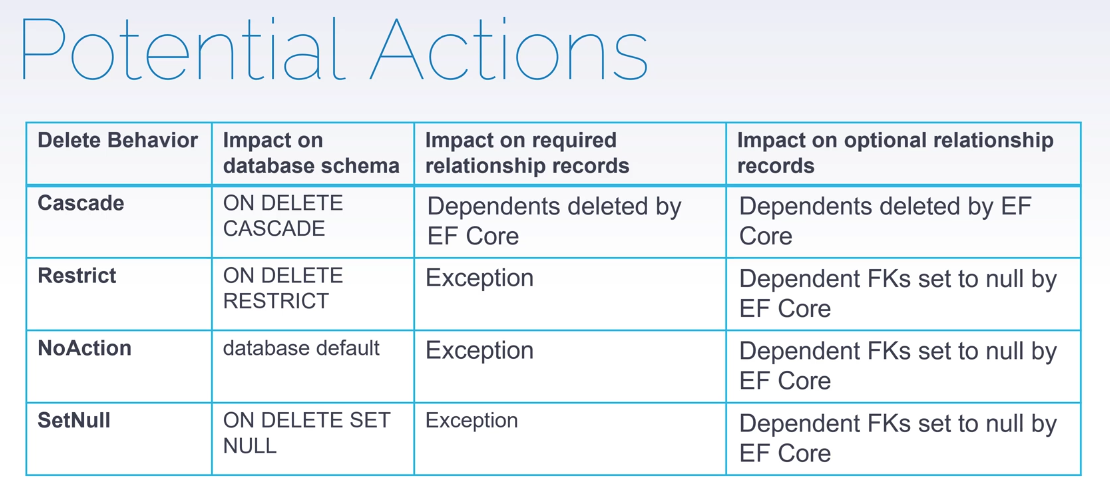
میرسیم به بحث delete خوب وقتی که میخوایم پاک کنیم اطلاعاتی رو مثلا زمانی که بخوایم chil/parent رو با هم توی یه دستور پاک کنیم از cascade استفاده میکنیم
یعنی وقتی که یه دیتایی رو پاک میکنیم که مرجع هستش برای اطلاعات دیگه اون ها هم پاک میشن
 به طور مثال توی کد ما وقتی که مربی رو پاک کنیم اینطوری تیم هم پاک میشه و بعد از این که تیم پاک بشه بقیه ی تیم ها بازیشون با این تیم دچار تغییر میشه و همه چی بهم میریزه برای همین باید بتونیم این قضیه رو کنترل کنیم
به طور مثال توی کد ما وقتی که مربی رو پاک کنیم اینطوری تیم هم پاک میشه و بعد از این که تیم پاک بشه بقیه ی تیم ها بازیشون با این تیم دچار تغییر میشه و همه چی بهم میریزه برای همین باید بتونیم این قضیه رو کنترل کنیم
به همین دلیل میام و از restrict جای cascade استفاده میکنیم
 میتونیم در جاهایی که ممکنه exceptio پیش باید بیایم از try catch استفاده کنیم .
میتونیم در جاهایی که ممکنه exceptio پیش باید بیایم از try catch استفاده کنیم .
حالا به این میرسیم که non table data base object رو با migration به دیتابیس اضافه کنیم و این قضیه خیلی مهمه چون که میخوایم track کنیم چه اتفاقی توی دیتابیس افتاده و این رو میتونیم با migration اوکیش کنیم ولی خوب چون این data base object ها چون از نوع table نیستند نمیتونیم به صورت مستقیم بهشون وصل بشیم و برای همین هم ما باید raw sql رو با migration مون ترکیب کنیم
 خوب اینجا ما یه migration رو زدیم ولی چون چیزی رو تغییر ندادیم خالیه ، حالا خودمون میایم توش sql مینویسیم
خوب اینجا ما یه migration رو زدیم ولی چون چیزی رو تغییر ندادیم خالیه ، حالا خودمون میایم توش sql مینویسیم
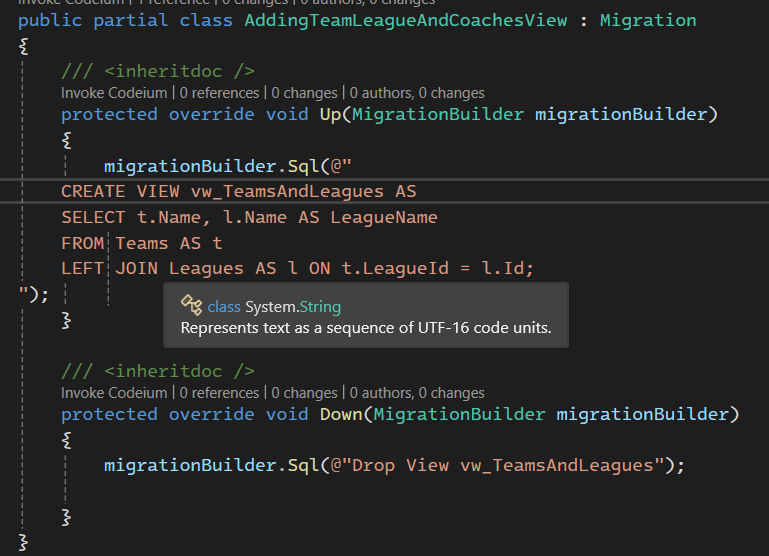
خوب اینجا در خط اول sql اومدیم گفتیم که یه View بساز و اولش رو با vw گذاشتیم و بعد گفتیم که name و league name رو بگیر برامون بیار و بعد هم join زدیم
خوب نکته ای که هست اینه که هر جایی که از up method استفاده کردیم باید از down هم استفاده کنیم و برای همین هم توی down دستور drop کردن اون View که بالا ساختیم رو نوشتیم
بعد add migration رو زدیم و بعد update کردیم و بعد دیتابیسمون این شکلی شد
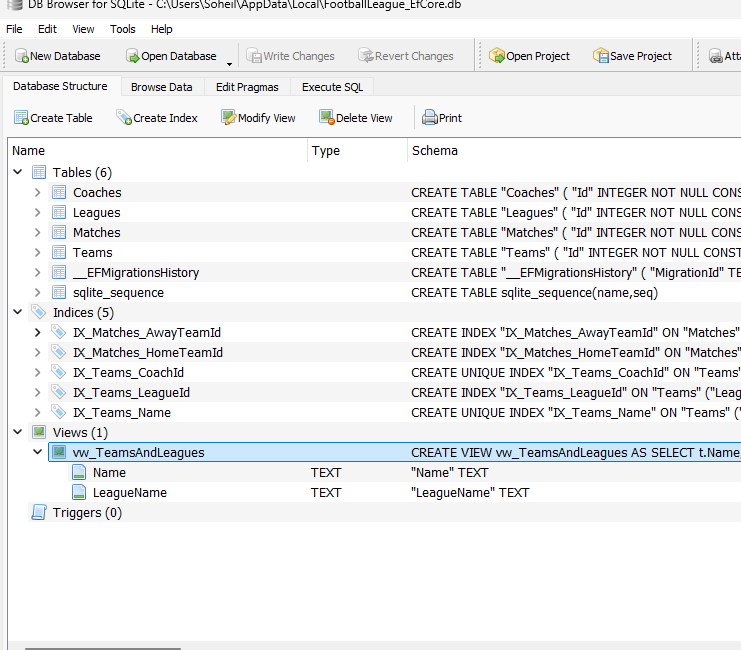
دقت داشته باشید که sqlite یه سری از قابلیت ها مثل function و stored prodedures رو نداره
خوب حالا ما یه چالشی که داریم اینه که بخوایم به view هامون دسترسی پیدا کنیم چون که vieww ها keyless هسند و فقط یه presntation و دیتاهارو به صورت read only میشه توشون دید و به همین دلیل نمیشه با key بیایم track اشون کنیم حالا چه با PK چه با FK ولی قضیه اینه که ef همه کار هارو با key انجام میده حالا چالش اینه که اگر بخوایم با کوئری یه view رو بگیریم باید چی کار کنیم ؟
خوب چون این view توی دیتابیس هستش ما باید یه data model داشته باشیم برای نمایش این database object
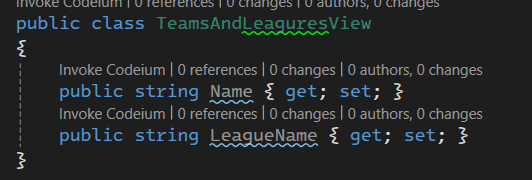
بعد میایم توی کلاس مرتبط با dbcontext مون اضافه اش میکنیم :
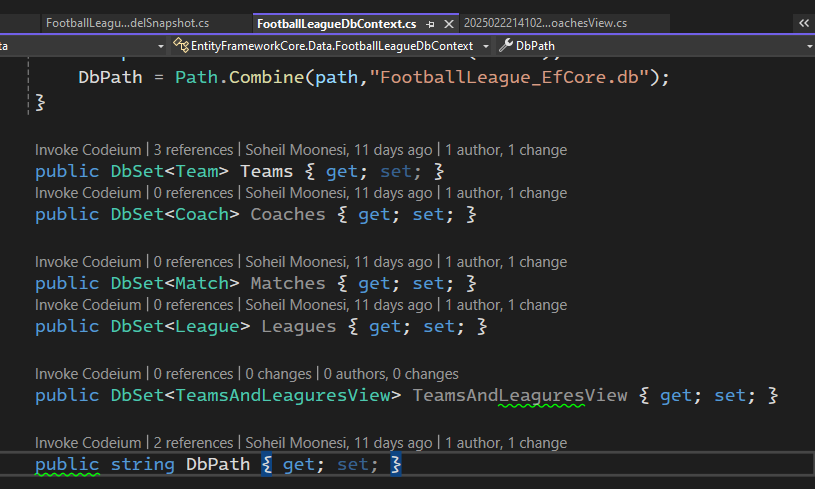
حالا میریم توی program
 برای دسترسی به view این رو مینویسیم که به این ارور میخوریم :
برای دسترسی به view این رو مینویسیم که به این ارور میخوریم :
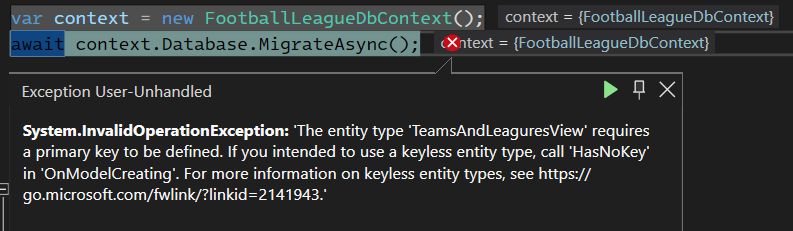 که توی متن ارور هم توضیح داده که این entity باید pk داشته باشه و اگر نداره باید از has no key استفاده بکنی
که توی متن ارور هم توضیح داده که این entity باید pk داشته باشه و اگر نداره باید از has no key استفاده بکنی
 ما هم با این کد بالا اومدیم اون view رو map کردیم به team and leagues view
ما هم با این کد بالا اومدیم اون view رو map کردیم به team and leagues view
خوب حالا اجرا میکنیم برنامه رو و حالا به این ارور میخوریم :
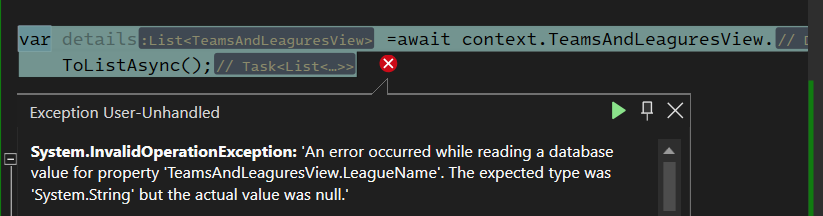 دلیل این ارور این هستش:
دلیل این ارور این هستش:
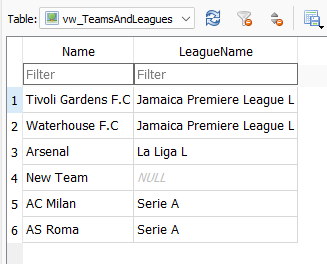 خوب new team فیلد League name اش خالیه
خوب new team فیلد League name اش خالیه
وقتی که اجرا کنیم این میشه :

خوب یه نکته ای که هست اینه که ما میتونیم یه کلاس رو هم به یه TABLE بیایم map کنیم :
 با استفاده از to table که البته به صورت فرضی اینجا نوشتیم
با استفاده از to table که البته به صورت فرضی اینجا نوشتیم
خوب ما میتونیم بیایم و Sql رو به صورت مستقیم بنویسیم ، دلیلش هم اینه که در خیلی از موارد پیش میاد که اون Sql که خودمون نوشتیم خیلی بهتر از اونی که ef برامون generate میکنه نکته که هست اینه که ef میاد همه فیلد ها رو paramitirized میکنه و این جلوی sql injection رو میگیره ولی وقتی که خودمون به صورت مستقیم مینویسیم دیگه نمیتونم از این قابلیت ef استفاده کنیم و زمانی که ما داریم از یه جایی داریم input میگیریم و از این raw sql ها هم استفاده کنیم ممکنه منجر بشه به sql injection
درسته که میتونیم ورودی هارو کنترل کنیم ولی باز هم احتمال خطا هستش
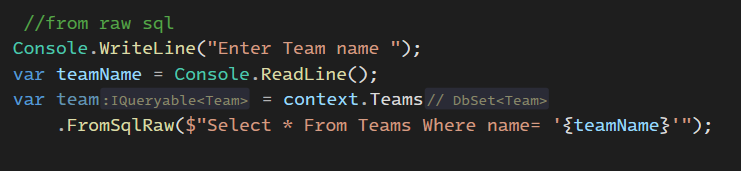 نکته : اینجا ما team name رو میزاریم توی ’ ’ تک کوتیشن
نکته : اینجا ما team name رو میزاریم توی ’ ’ تک کوتیشن
 خوب توی توضیحات متدش نوشته که هیچوقت از concatinate یا interpolated string ها بدون اینکه این ها چک بشن استفاده نکنیم چون که باعث میشه برنامه تحت خطر sql injection قرار بگیره
خوب توی توضیحات متدش نوشته که هیچوقت از concatinate یا interpolated string ها بدون اینکه این ها چک بشن استفاده نکنیم چون که باعث میشه برنامه تحت خطر sql injection قرار بگیره
خوب حالا داستانش چیه؟ داستانش اینه که یه نفر میاد به جای ورودی teamName که توی from sql raw نوشتیم میاد و یه sql خودش مینویسه و این رو همراه با همون sql که هستش میفرسته داخل برنامه
حالا برای این که جلوی این قضیه رو بگیریم میایم و پارامتر sql برای اون تعریف میکنیم به این شکل :


اون team name که توی استرینگ هستش place holder هستش و فیلد بعدی اون مقداری هستش که داخلش قرار میگیره یعنی اون مقداری که
این کار باعث میشه که هر چیزی که داستان داشته باشه رو از توی اون فیلد پاک میکنه و یه جورایی دستی داریم paramitrized اش میکنیم که مانع sql injection بشه
 خوب اینجا میایم و teamName که در بالاتر به صورت استرینگ نوشتیم رو بهش میدیم
خوب اینجا میایم و teamName که در بالاتر به صورت استرینگ نوشتیم رو بهش میدیم
 و یه @ هم بهش میدیم و بعد team name param رو بعدش میزاریم
و یه @ هم بهش میدیم و بعد team name param رو بعدش میزاریم
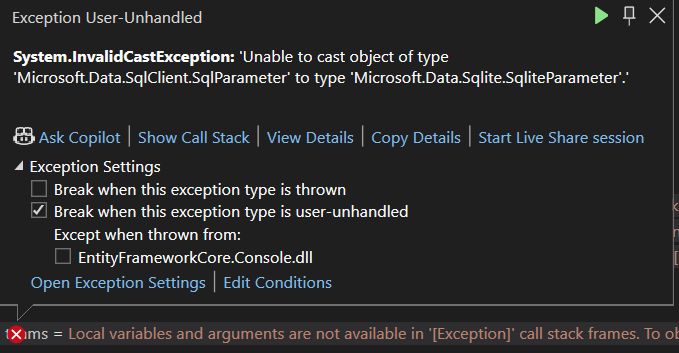
به ارور میخوریم چون که از sql parameter استفاده کردیم در صورتی که دیتابیسمون sqlite هستش
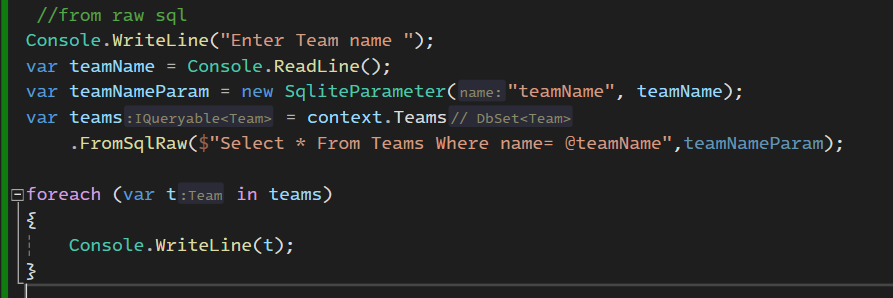

خوب همنطوری که معلومه اینجا اومده paramitirized اش کرده
حالا دقت کنید که ما چند تا آپشن دیگه هم برای پیاده سازی داریم : from sql , from sql interpolated
که این دو تا هم به صورت اتوماتیک میان و paramitirized میکنن و دیگه نمیخواد خودمون به صورت دستی بیایم paramitrized کنیم

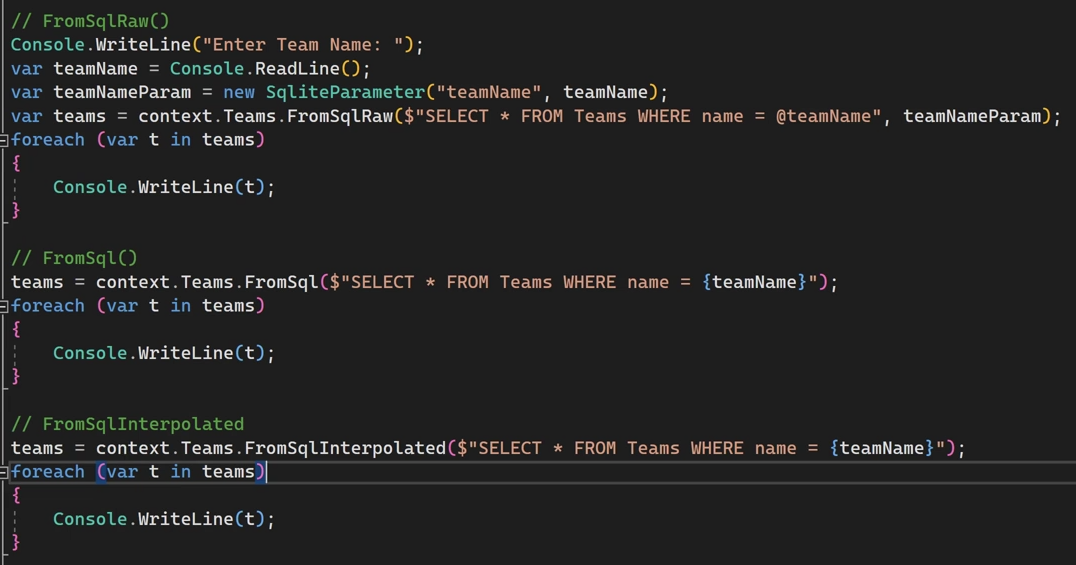
 اولی رو خودمون paramitirized کردیم و دوتای بعدی به صورت اتوماتیک انجام شده
اولی رو خودمون paramitirized کردیم و دوتای بعدی به صورت اتوماتیک انجام شده
خوب میتونیم از raw sql با linq استفاده کنیم

اینطوری اول اومدیم teams رو گرفتیم و بعد گفتیم که اونجایی که id ها برابر 1 هستش بیاد دیتاش رو جدا کنه و بر حسب id ّیاد مرتب سازی رو انجام بده و بعد به جای این که بیایم teams رو با league بیایم join بزنیم میایم از include استفاده میکنیم
به جای استفاده از from sql باید از from sql interpolated استفاده کنیم
خوب حالا میتونیم از stored Procedure ها هم استفاده کنیم با نوشتن EXEC و بعد نوشتن اون SP و بعد اون پارامتری که میخوایم داخلش بفرسیتم


خوب میرسیم به Non query statement ها که یعنی همون update , delete , ADD
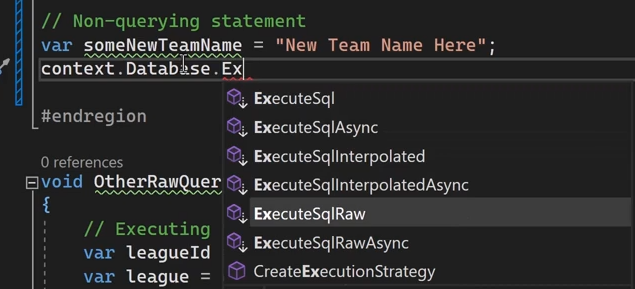

خوب اینجا اومدیم توی یه پارامتر اسم یه تیم جدید رو گذاشتیم و بعد گفتیم که بیاد در جدول Tams و فیلد name بیاد و Update رو انجام بده و sucess که نوشته شده بیانگر اینه که اگر 1 بود عملیاد به درستی انجام شده و اگر 0 بشه به خطا خورده

خوب با استفاده از این روش میتونیم بیایم دیتاها رو به صورت جزئی از جداولشون بگیریم و دیگه کل entity رو نگیریم ، برای این کار فقط لازمه که بیایم و تایپی که میخوایم رو تعیین کنیم :

خوب میرسیم به قسمت اجرای function
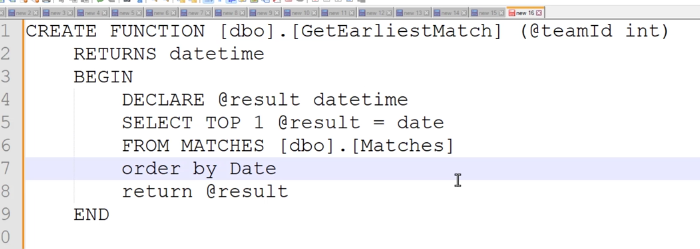
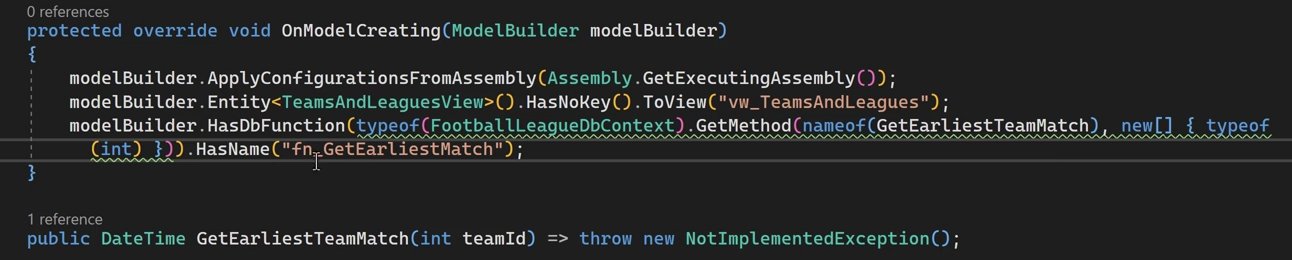
Create Functions [dbo].[getEaliestMatch] (@teamId int) returns datetime begin declare @result datetime select top 1 @result = date from Matches [dbo].[Matches] order by date return @result end خوب برای این که از function بخوایم استفاده کنیم باید بیام و اون رو توی db context تعریف کنیم و بهش map کنیم
پیگیری برای توضیحات بیشتر

92