خوب حالا برای ساختار بندی میایم یک هارد رو اختصاص میدیم به سیستم عامل و نرم افزاهای مربوطه و sql server یک هارد دیگه رو اختصاص میدیم به mdf ها و یک هارد هم اختصاص میدیم به ldf ها و یک هارد هم برای بک آپ گیری ، اینی که این هارد بک آپ هم داخل همین سرور هستش برای بک داشتن اطلاعات و تغییراتی و خرابی هایی که ممکنه برنامه نویس ها به وجود بیارن بهتر اینه که بک آپ ها در یک سرور دیگه قرار بگیرند
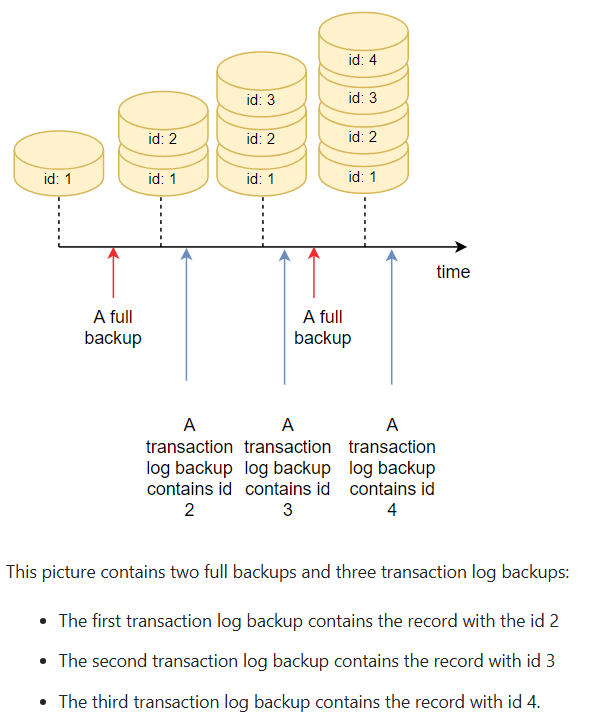
خوب Sql وقتی که عملیات create delete update میخواد انجام بشه قبلش میاد یه نسخه از اون دیتا رو از mdf برمیداره بعد انتقالش میده روی فایل LDF بعد یه transaction داخل اون فایل LDF باز میکنه و بعد عملیات مد نظر که از جنس همون 3 تای اون بالا هست رو انجام میده بعد از این که کار کامل و درست انجام شد commit میشه و بعد دیتاهایی که تغییر کردن یک کپیشون از ldf برداشته میشه و انتقال داده میشه به MDF
در LDF تمامی تاریخچه و تمامی عملیاتی که روی دیتا ها انجام میشه اونجا قرار میگیره و نتیجه ی عملیات هم دیتاش داخل LDF هستش
اگر Recovery از نوع full back up باشه اگر قسمتی از فایل mdf نابود شده باشه میتونیم با استفاده از ldf بیایم و اطلاعات رو برگردونیم ، اینطوری که میاد از اون قسمتی که اطلاعات از دست رفته میاد یکی یکی اطلاعات رو طبق LDF تغییر میده و اطلاعات رو کامل میکنه

https://www.sqlservertutorial.net/sql-server-administration/sql-server-backup-types/
حالا میرسیم به قسمت file group ها
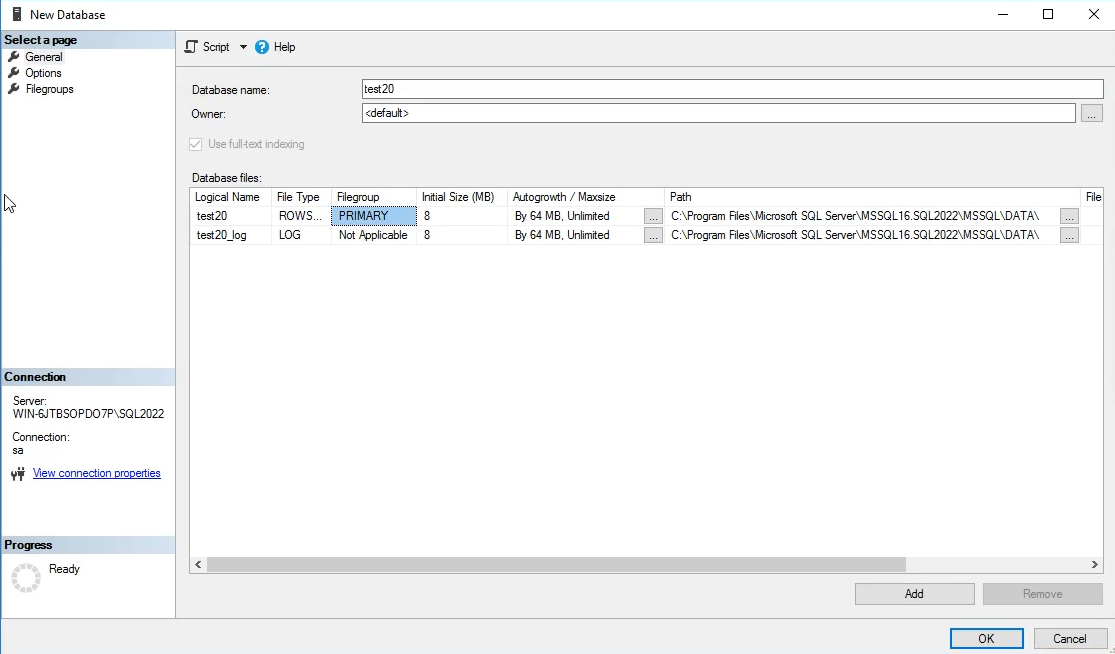
همونطوری که میبینید file group برای LDF قابل انجام نیست ولی برای MDF میشه انجام داد
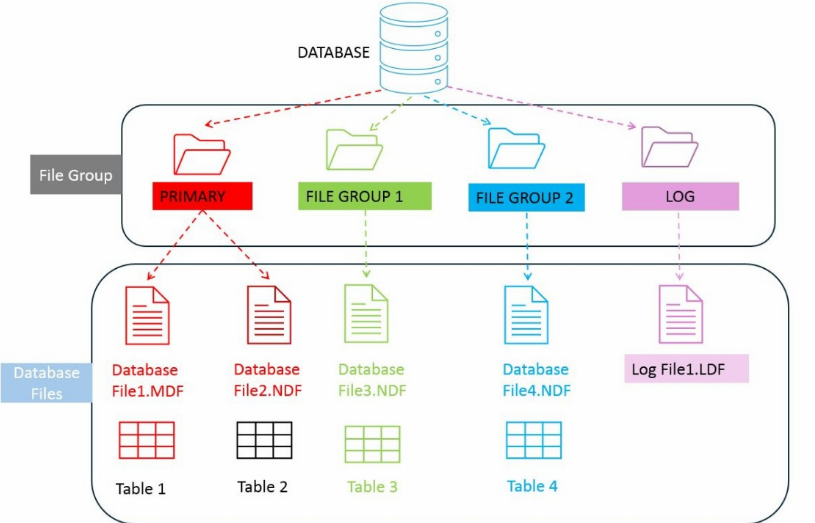 نکته هایی که در عکس بالا هستش اینه که اولین دیتابیس پسوندش mdfهستش و بعدی ها همه میشن ndf به خاطر این که میتونیم n تا MDF داشته باشیم پس میشه NDF
نکته هایی که در عکس بالا هستش اینه که اولین دیتابیس پسوندش mdfهستش و بعدی ها همه میشن ndf به خاطر این که میتونیم n تا MDF داشته باشیم پس میشه NDF
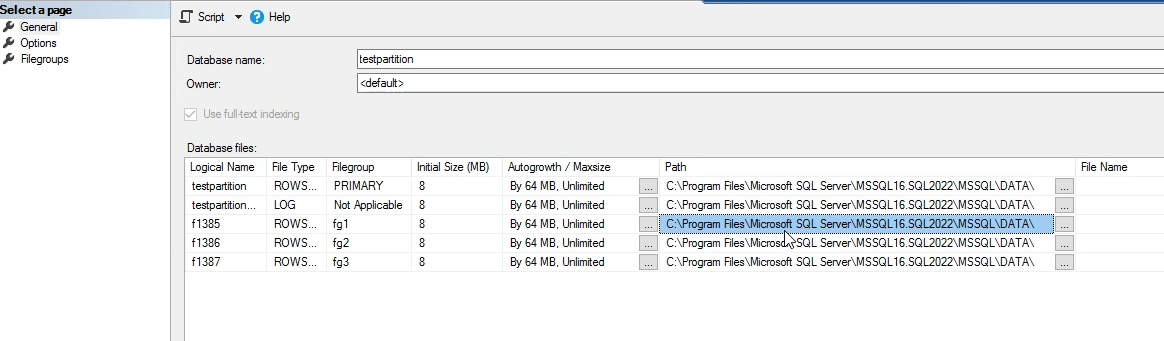
این هایی که در filegroup های متفاوت در جاهای مختلفی میتونن ذخیره بشن مثلا برای primery میشه هارد hdd اول درایو d و برای filegroup 1 میشه هارد دوم داریو E
میتونیم به هر تعدادی که میخوایم فای های mdf درست کنیم ولی LDF فقط یه دونه است.
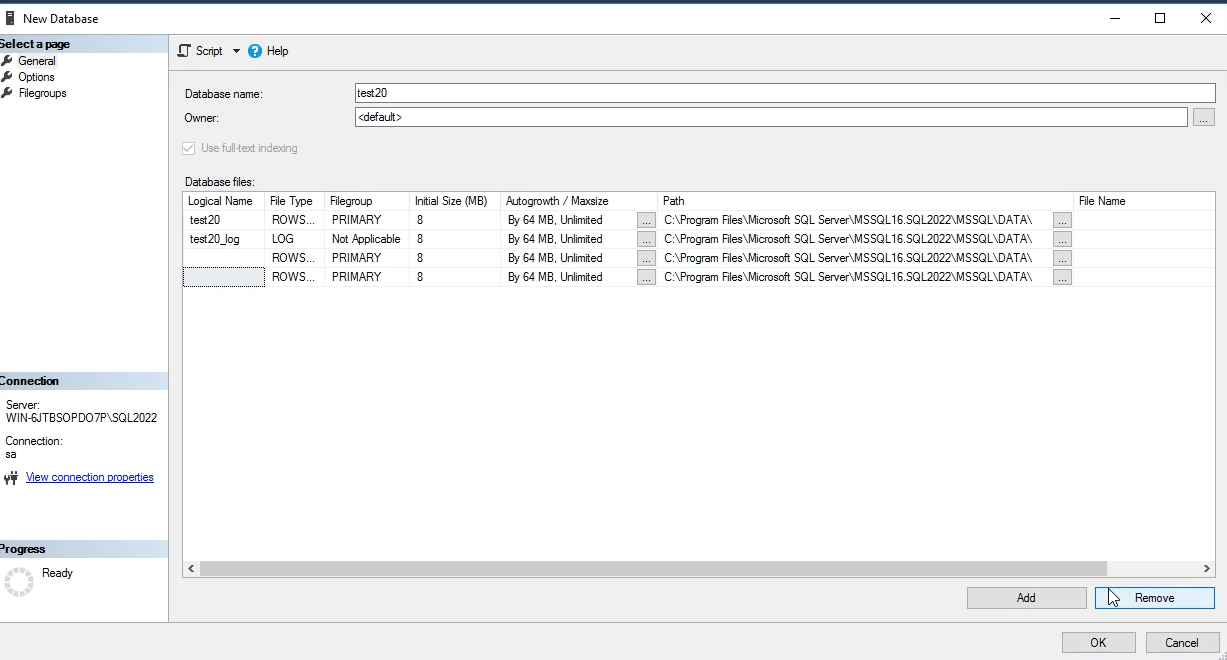
خوب file type ها از این پنججره قابل تعیین کردنه
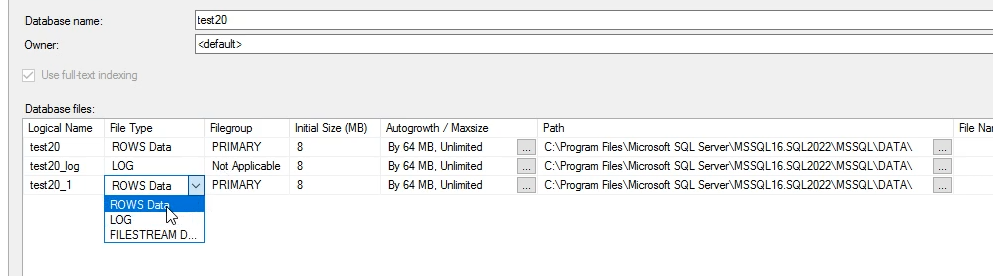
که row data میشه MDF و log میشه LDF و file stream هم اصا داستانش جداست
خوب حالا میتونیم دو تا file group تعیین کنیم
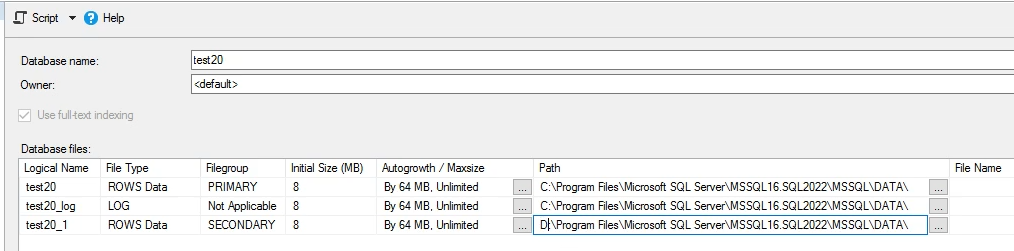
یکی primery و یکی secondry که بهتره که در دو درایو جدا ذخیره سازی بشن
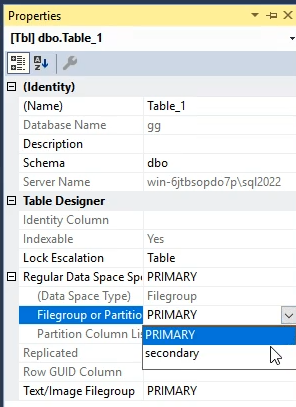
حالا وقتی که میخوایم این file group رو تغییر بدیم اینطوری عوش میکنیم :
فقط دیتاهایی که حساس هستند مثل پسور رو میایم encript میکنیم و بعد ذخیره میکنیم در دیتابیس
به صورت دیفالت هم یه فایل گروپ تعیین شده
disk managment دلیل این که میایم فایل گروپ های مختلف میسازیم و دیتاها رو در هارد های متفاوت ذخیره میکنیم اینه که ممکنه حجم یک هارد برای ذخیره سازی برای یک هارد ممکنه زود تموم میشه و بهتره که این جدوال رو در هارد های مختلف ذخیره کنیم
backup managment اینطوری در نظر بگیریم که اگر از فایل گروپ ها استفاده نکنیم یه جدول ممکنه داشته باشیم 20 تراباییت و حال ا میخوایم ازش بک آپ بگیریم حالا اتفاقی که میوفته اینه که دقیقا یه هارد دیگه 20 ترابیایتی برای ذخیره سازی بک آپمون نیاز دارم
خوب حالا برای مدیریت این که فاصله زمانی هر بک آپ چقدر باشه هم میونیم از file group استفاده کنیم مثلا فایل گروپ 1 سالی یکبار ازش بک آپ گرفته بشه و فایل گروپ 2 ماهی یکبار
optimization پردازش موازی و ذخیره سازی و لود دیتا ها به صورت همزمان در ترد های متفاوت برای همین میام فایل گروپ ها رو درست میکنیم چون برای هر هارد یک مقدار از resourse و thread در نظر گرفته میشه و بعد در صورت انجام عملیت به صورت موازی سریع تر و بهتر عمل میکنه که البته این خودش trade of هایی داره
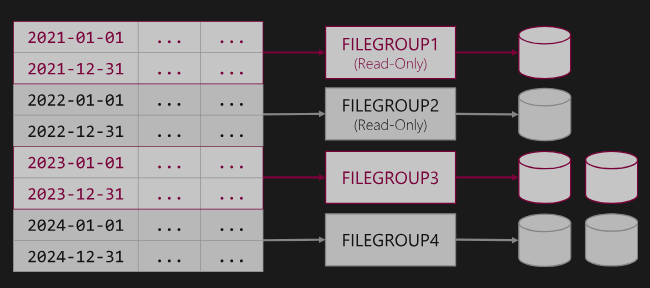
archiving میتونیم حتی دیتای داخل یک جدول رو بیایم در هارد ها و یا جاهای دیگه قرار بدیم ، مثلا بیایم بر اساس شهر ها دیتا ها رو در هارد های متفاوت قرار بدیم
انواع مدل ساختن دیتابیس نوع اول یک دیتابیس واحد جدول 1400 و جدول 1401
برای گزارش گیری باید هر سری اسم جدول هارو عوض کنیم برای هر سال دیتا یکجاست که خوب نیست
نوع دوم دیتابیس 1 - جدول سال 1400 دیتابیس 2 - جدول سال 1401 دیتابیس های جدا جدا محصول شماره 1 میشه مثلا خودکار در سال 1400 محصول شماره 1 در سال بعدی مثلا اگر بشه صندلی قابلیت این رو داره که دیتابیس های قدیمی رو آرشیو کنیم
نوع سوم دیتابیس با یک جدول و فیلد سال جامعیت دیتا دارم ولی امنیتش پایینه
پارتیشن بندی
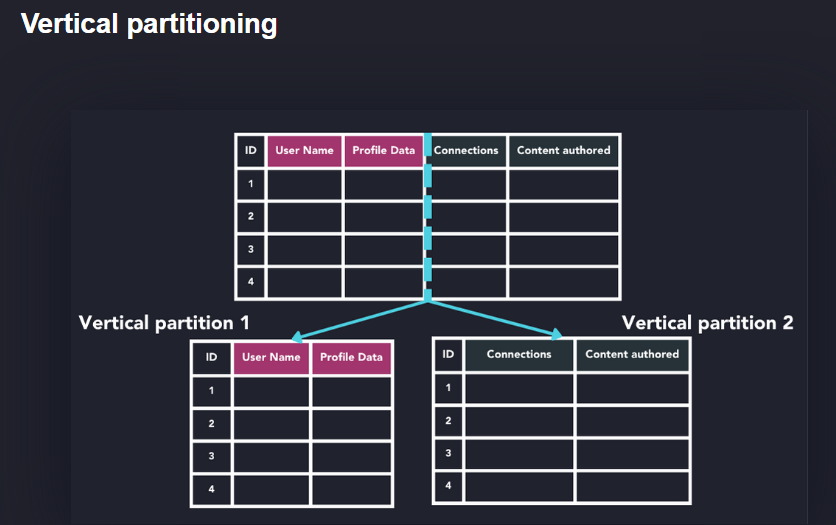
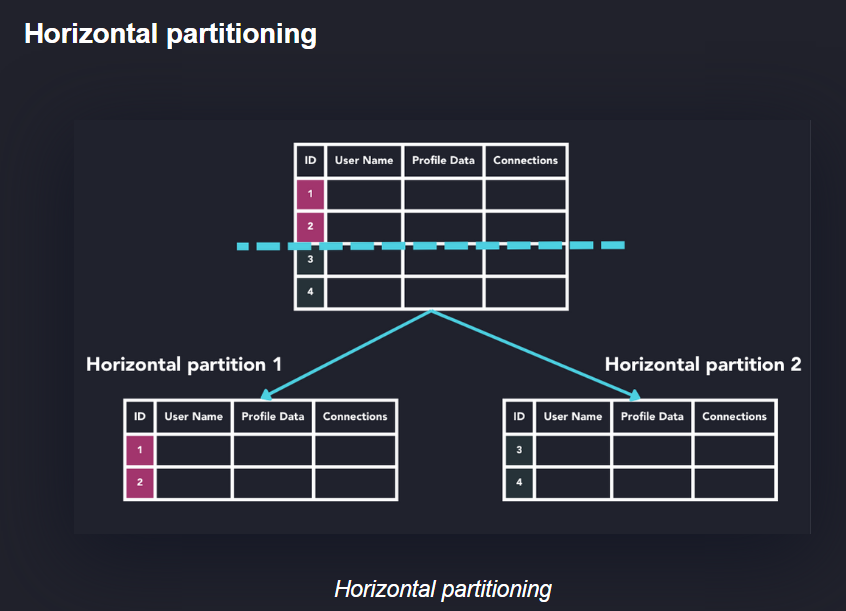
https://questdb.io/glossary/database-partitioning/
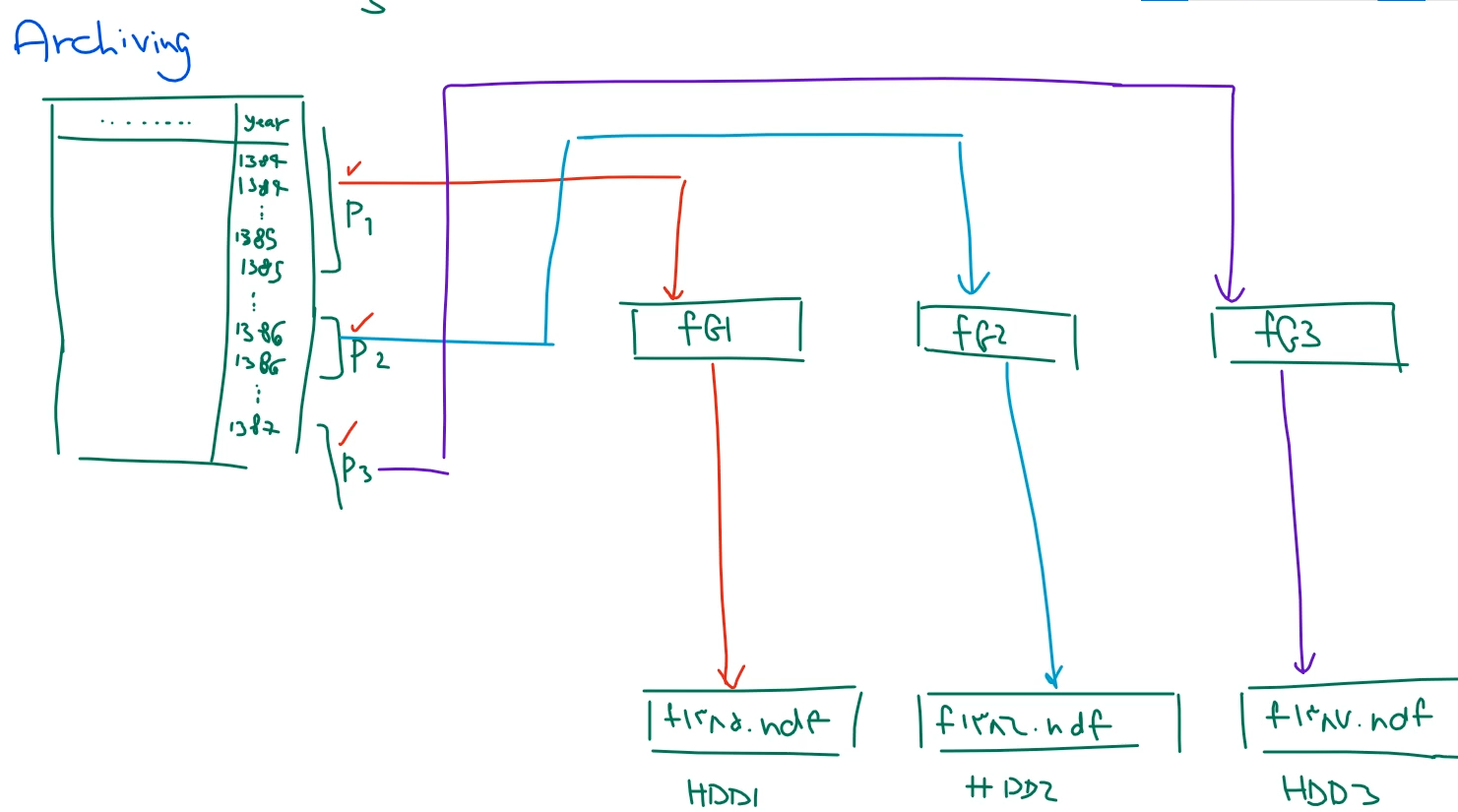
خوب برای این کار رو انجام بدیم اول باید بیایم دیتاهمون رو پارتیشن بندی کنیم :
 بعد از اون باید بیایم تعیین کنیم که هر کدوم از این پارتیشن ها به کدوم از فایل گروپ ها وصله بشه :
بعد از اون باید بیایم تعیین کنیم که هر کدوم از این پارتیشن ها به کدوم از فایل گروپ ها وصله بشه :
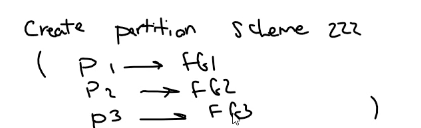
خوب اگر از اول پارتیشن بندی نکردی هم میشه این کار و کرد وقتی که میخوایم این کار رو انجام بدیم انتفال اطلاعات به صورت اتوماتیک انجام میشه به طور مثال وقتی که از اول دیتابیسمون بدون پارتیشن بوده و بعد میایم براش توی هارد های مختلف فایل گروپ درست میکنیم بعد انتقال اطلاعات و جابه جایی شون رو اتوماتیک انجام میشه
در دیتا بیس ما دستور های create ساختن و alter تغییر و ویرایش , drop پاک کردن
خوب حالا میرسیم به انجام مراحل
اول یه دیتابیس میسازیم و بعد میایم 3 تا فایل از جنس ndf درست میکنیم بعد میایم اسم فایل های ndf رو تعیین میکنیم و بعد میایم file group هاش رو تعیین میکنیم و بعد میایم جاهایی که باید ذخیره بشن رو تعیین میکنیم
ما میتونیم قبل از این جدولی داشته باشیم بیایم یه partition function رو داشته باشیم بعدا به هر جدولی این partion function رو بدیم میاد اون عملیات رو براش اجرا میکنه مثلا طوری نوشتیمش که بیاید بر اساس سال پارتیشن بندی رو انجام بده هر وقت که این partion function رو وصل کنیم به table که سال داره اون میاد این کار ها رو براش انجام میده
این پایین تمام مشخصات رو نشون میده که نوع دیتابیس جیه و با چه یوزی هستم و اسم دیتابیسمون چیه

خوب برای تنظیم پارتیشن ها از این روش استفاده میکنیم :
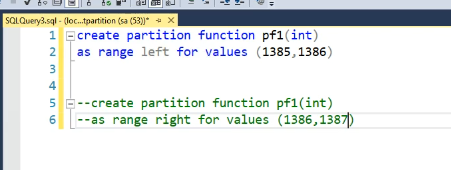
خوب اونجایی که نوشتیم int این data type که برای تقسیم بندی میخوایم استفاده کنیم از چه نوع داده ای هستش
نکته ای که هست اینه که به تعداد +1 بیشتر از تعداد تقسیم ها میشه تعداد پارتیشن ها یعنی به طور مثال 1385 و 1386 رو داریم که میشه 2 تا نقطه تقسیم پس در نتیجه ما 3 تا جای پارتیشن براش نیاز داریم
برای این که تعیین کنیم که range مون از راسته یا چپ از طریق شکل زیر عمل میکنیم
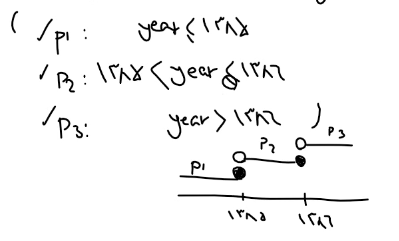
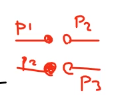 left
left
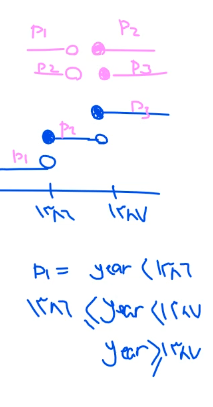 right
right
بعد از اجرای دستور
طریقه ی کامنت گزاری :
خوب برای وصل کردن پارتیشن ها به فیل گروپ ها از این کد استفاده میکنیم :
 که میایم یه schme به اسم PS1 درست میکنیم و بعد میگیم که اون پارتیشن فانشکن رو بگیر و وصلشون که به این 3 تا فایل گروپ
که میایم یه schme به اسم PS1 درست میکنیم و بعد میگیم که اون پارتیشن فانشکن رو بگیر و وصلشون که به این 3 تا فایل گروپ
بعد میایم table رو درست میکنیم
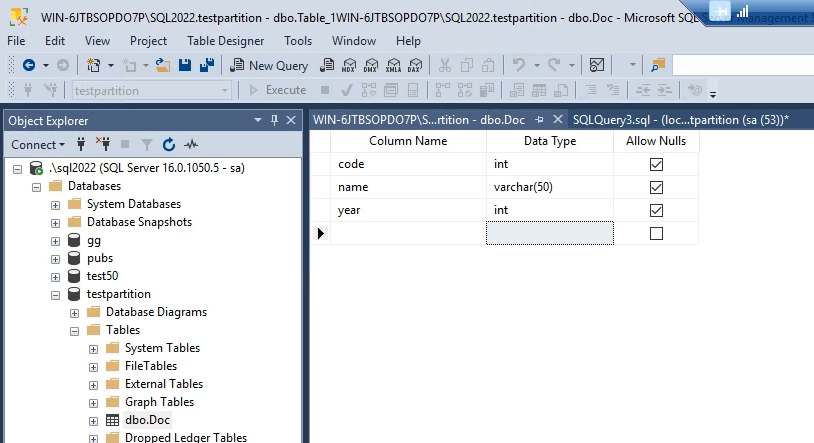
بعدش میایم روی جدولی که درست کردیم قسمت properties و اونجا regular data space specifiction رو میزاریم روی Partition scheme
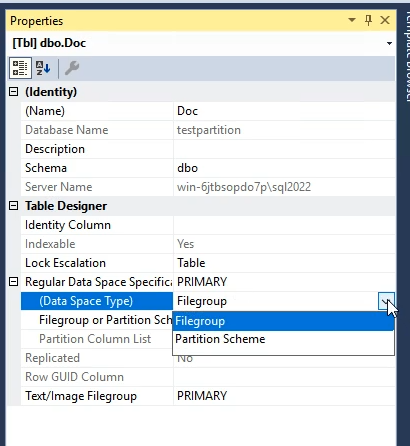
بعدش باید تعیین کنیم که اسم اون schema چیه؟ که چون یکی schema داریم همون رو به صورت اتوماتیک قرار داده
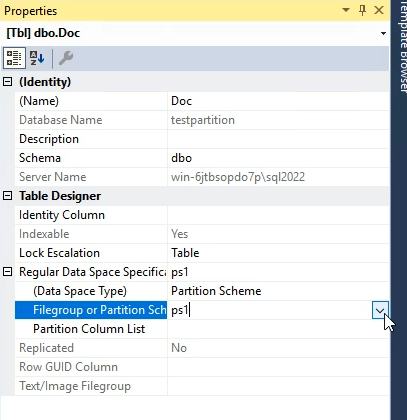
بعدش میایم تعیین میکنیم که پارتیشن بر چه اساسی انجام بشه ، میزنیم روی partition column list و از اونجا میبینیم طبق کدی که زدیم باید این قسمت از نوع int باشه و میاد دیتا تایپ هایی که از نوع int هستن در اون جدول رو بهمون نشون میده
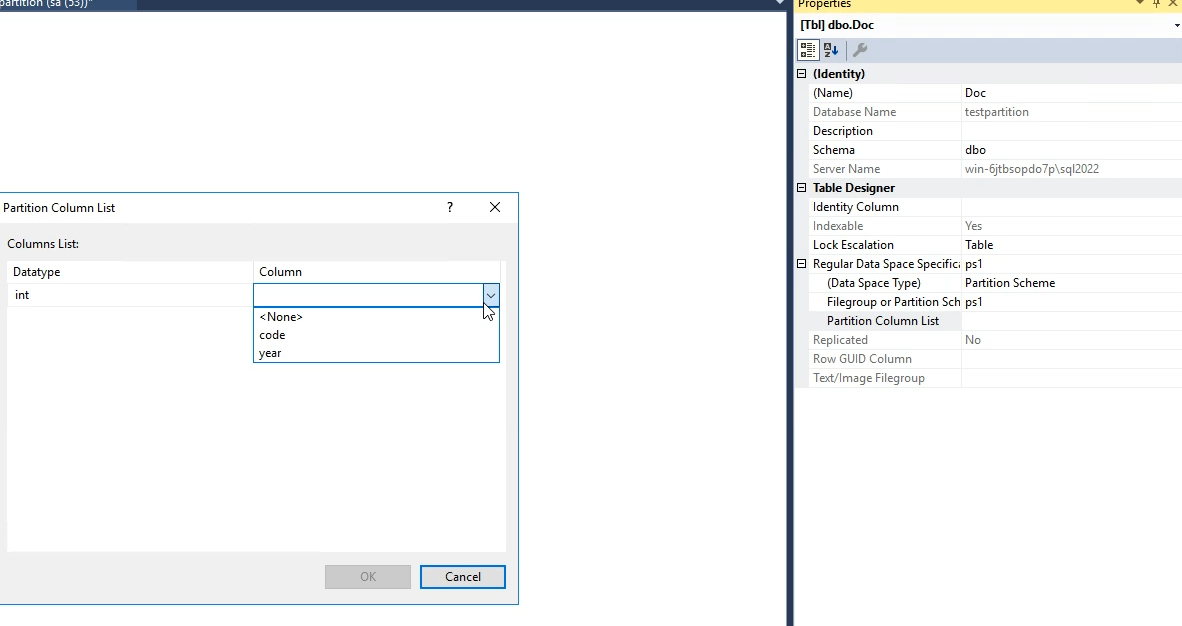
و از اونجا میایم و year رو انتخاب میکنیم
بعد میایم به صورت دستی توی جدول دیتا وارد میکنیم
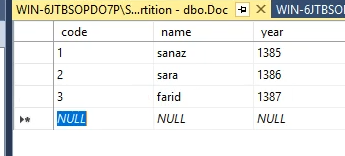
الان اینجا 3 تا دیتا داریم که قراره بره توی 3 تا پارتیشن مختلف
برای گرفتن ریپورت هم اینطوری عمل میکنیم :
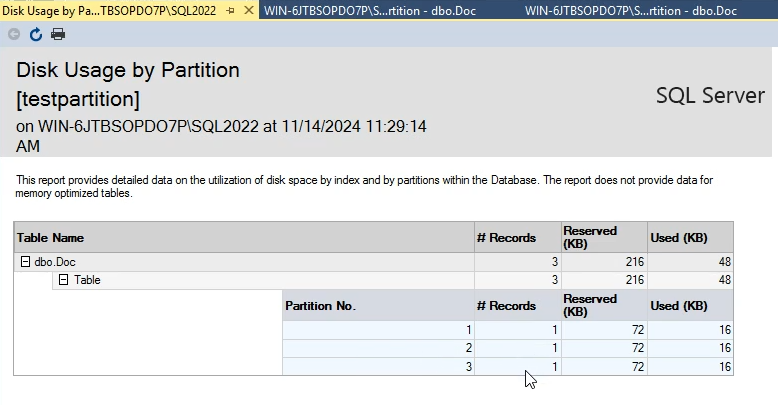
اینطوری ریپورتش رو نشون میده :
رفع باگ :
باگ
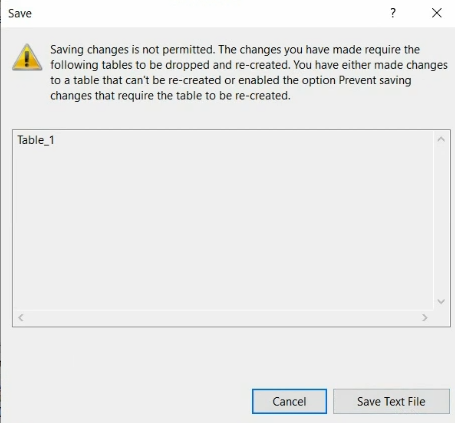
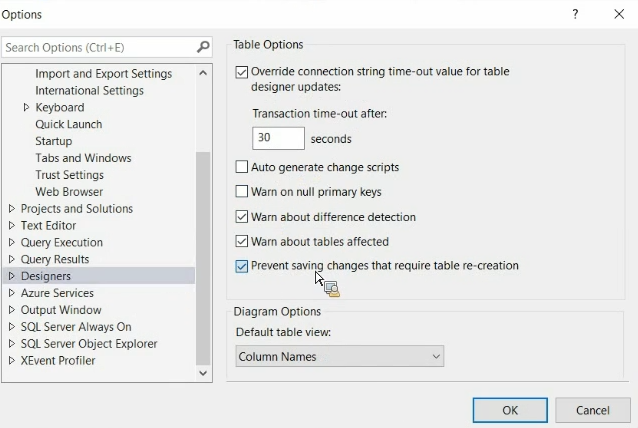 تیک perevent saving رو غیر فعال کنیم و بعد سیوش کنیم باگ برطرف میشه
تیک perevent saving رو غیر فعال کنیم و بعد سیوش کنیم باگ برطرف میشه
اگر بخوایم جای فایل ها رو عوض کنیم باید دیتابیس رو از engine جدا کنیم و بعد فایل هاش رو دستی به جایی که میخوایم جابه جاش کنیم ببریم و بعد وقتی که میخوایم دوباره بچسبونیمش باید یه سری کار ها رو انجام بدیم

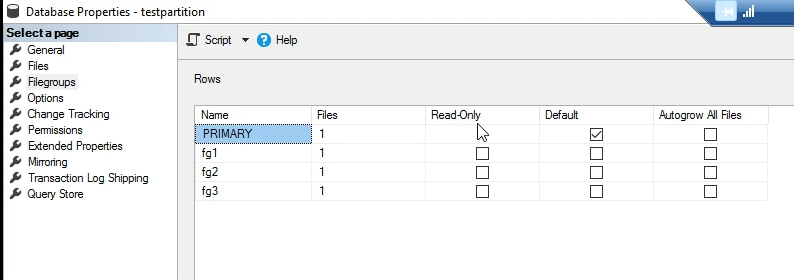
خوب اینجا همونطوری که میبینید فایلی که به فایل گروپ primery وصل باشه نمیتونه read only بشه
حالا به طور مثال میایم fg1 رو read only میکنیم
ارور :
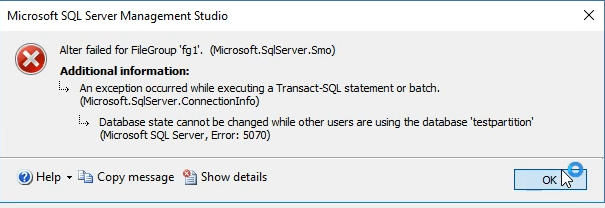
راه حل راحتش اینه که یه بار کل برنامه رو ببندیم و بعد بازش کنیم
خوب حالا وقتی که fg2 رو Read only کردیم وقتی که میخوایم توی table اش دیتا وارد کنیم با این ارور مواجه میشیم
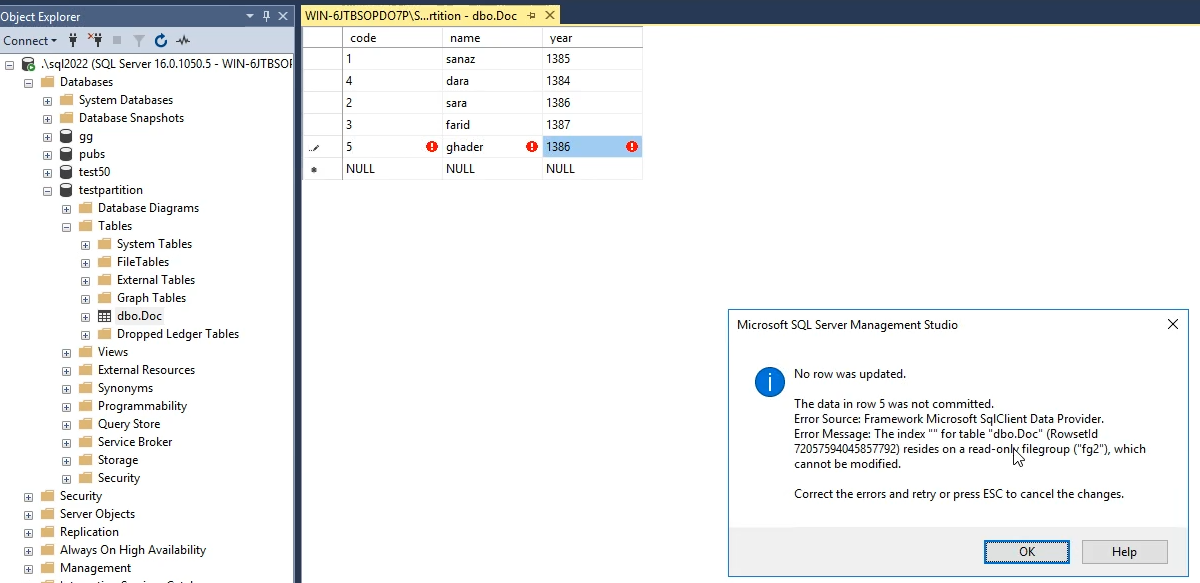
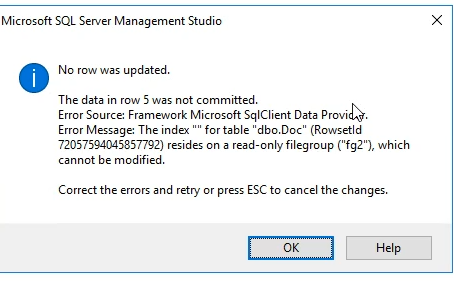
ویرایش و حذف و هر کار دیگه رو دیگه رو نمیشه روشون انجام داد و این که فایل هایی که read only میشن سرعت دسترسی شون میره بالا
خوب حالا برای این که فایل گروپ رو از حالت دیفالت از روی primery بخوایم تغییر بدیم
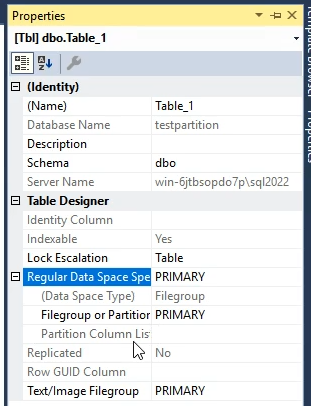
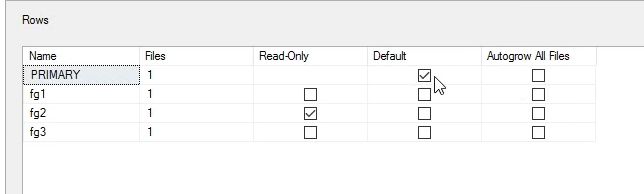
اینجا دیفالت روش هستش و از اینجا تغییرش میدیم
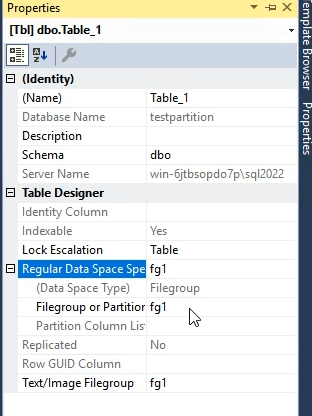
خوب حالا وقتی که میخوایم یه فایل گروپ جدید بسازیم بهمون میگه دیفالت کدومه
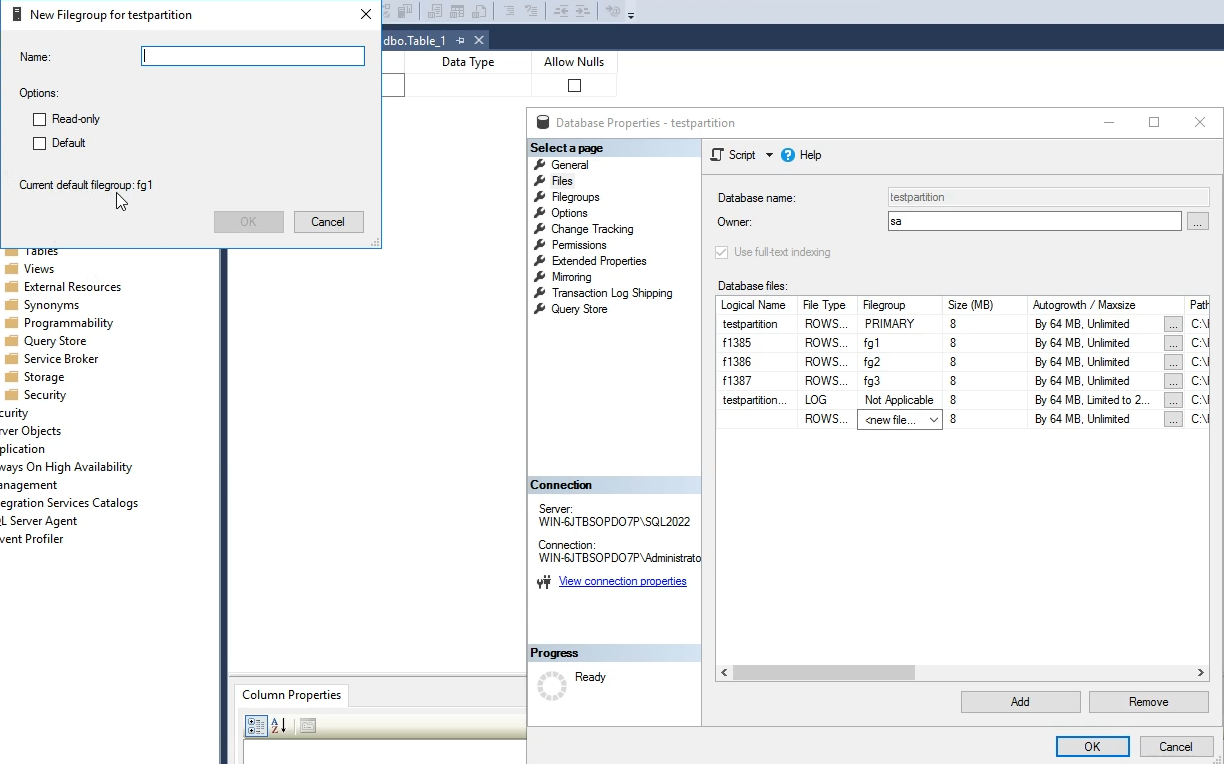
اول ما عملیات پارتیشن بندی برای دیتاهامون در جدول انجام میدیم و بعد میایم با partition scheme تعیین میکنیم که هر کدوم از اون partisition هایی که در مرحله قبل درست کردیم به کدوم file group وصل بشه
در نظر بگیریم که اگر در ابتدا فقط windows authentication رو انتخاب کردیم ولی بعدش میخوایم عوضش کنیم ، حالا میخوایم عوضش کنیم (در حالتی که mix mode رو انتخاب نکرده بودیم )
بعد میریم توی قسمت security اونجا sql server and windows auth رو انتخاب میکنیم
بعد میریم توی Services


بعدش میریم توی این قسمت و میزنیم روی sa :
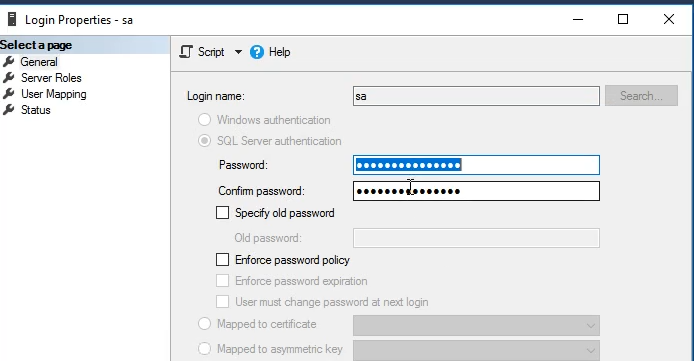
 براش پسورد رو هم تعیین میکنیم
براش پسورد رو هم تعیین میکنیم
برای درست کردن user جدید
بعدش میزنیم روی advance و اونجا میزنیم روی find now و از اونجا یوزرمون رو انتخاب میکنیم
برای ساختن user sql ای هم اینطوری عمل میکنیم :
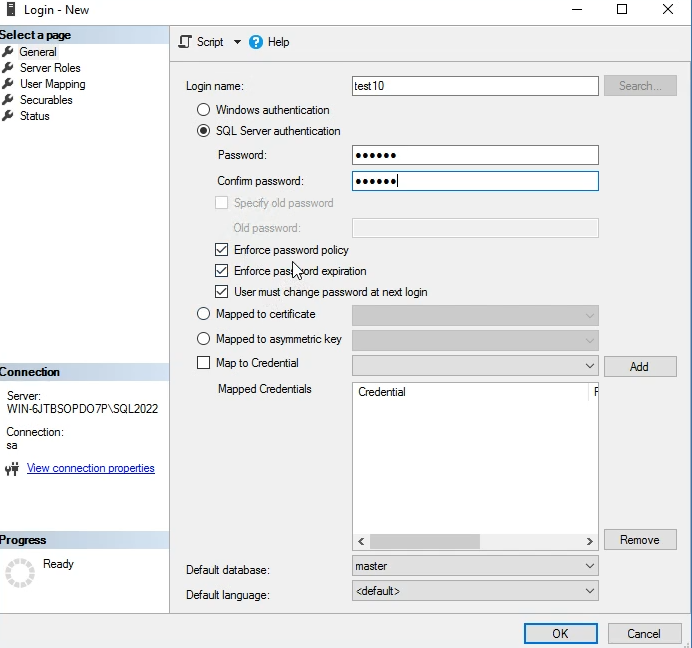
خوب pasword policy چک میکنه میزان امن بودن پسورد انتخابی رو
بعدیش expiration بعد از یک ماه پسوردش باطل میشه
بعدیش هم change password هستش که بعد از اولین لاگین نفری که باهاش وارد شده پسوردش رو خودش تعیین میکنه