خوب وقتی که میزنیم روی propetties دیتابیس
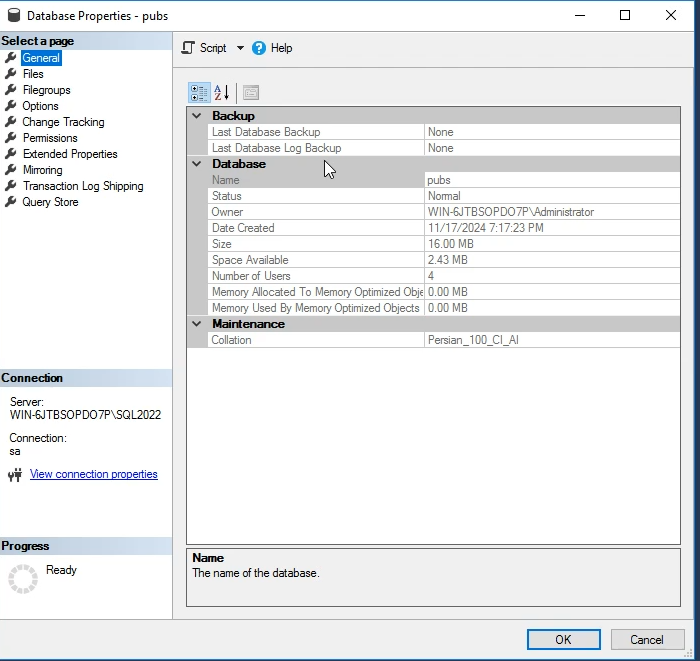
این اطلاعات رو بهمون نشون میده
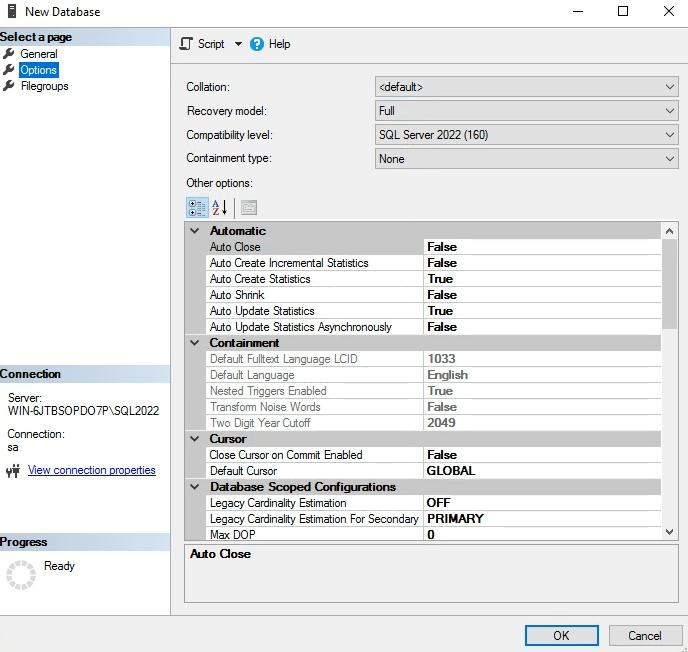
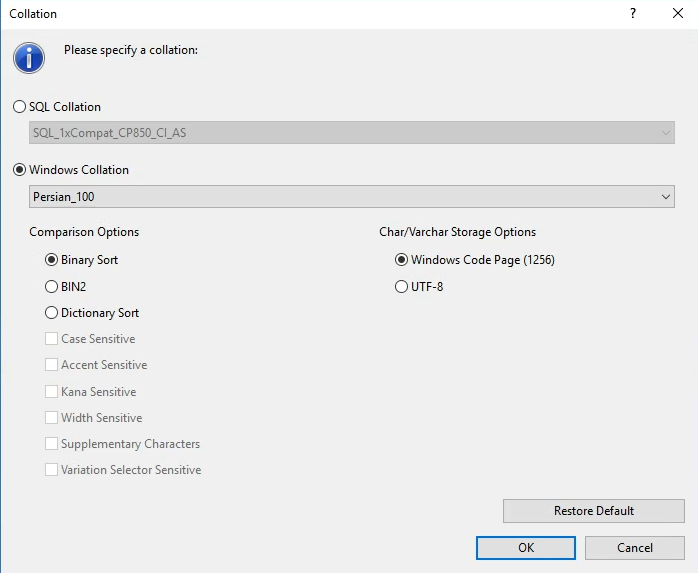
حالا وقتل که میخوایم یه دیتابیس جدید بسازیم ، اینجا collation رو زده default ولی ما ممکنه ندونیم که default این دیتابیس چیه برای همین قبل از این که بخوایم کاری کنیم توی دیتاببس اولش بریم از توی همخون صفحه اول properties ببینیم که collation اش چیه ، چون که این default ای که اینجا هست میاد از اون ارث بری میکنه
اگر بخوایم چیزی غیر از اون دیفالته باشه میزنیم روش و تغییرش میدیم به طور مثال اگر خواستیم که این دیتابیس جدید اطلاغات هندی ذخیره کنیم
اگر موقع ساخت collation رو اشتباه انتخاب کنیم بعدش دیگه خیلی سخت میشه درستش کرد
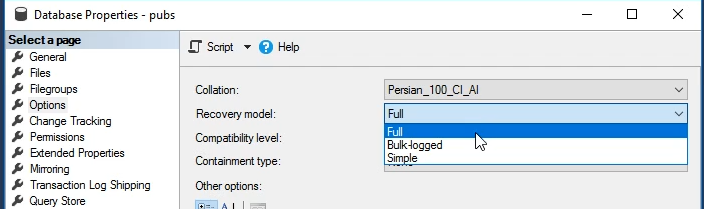
 https://sqlconjuror.com/tag/recovery-models/
https://sqlconjuror.com/tag/recovery-models/
https://www.sqlmvp.org/explore-recovery-models-in-sql-server-with-examples/
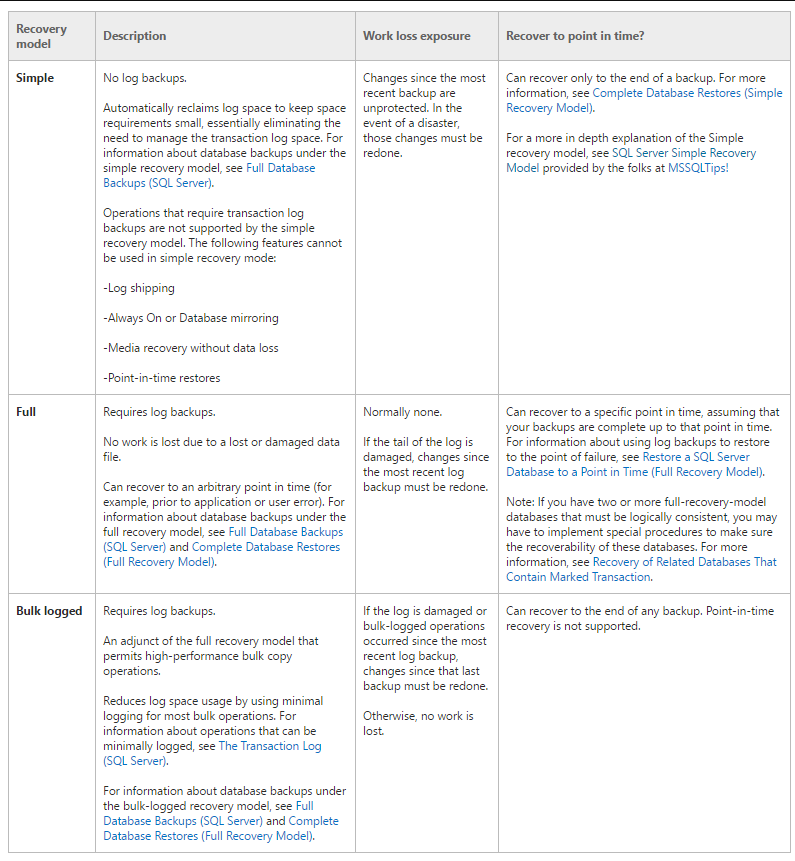
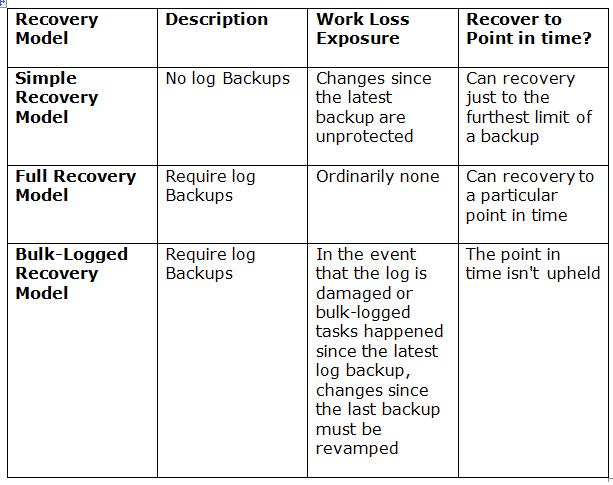
توی حالت full میاد از اول هر اتفاقی که توی دیتا بیس افتاده رو در خودش ذخیره میکنه و اگر فایل ldf حجمش تموم بشه با مکانیزم auto grow میاد حجمش رو زیاد میکنه
اگر simple باشه هیچوقت log file بزرگ نمیشه همیشه به همون اندازه که همون اول بهش اختصاص دادیم باقی میمونه، هر وقت که تموم بشه فضا میاد از اول روش re write میکنه اطلاعات بعدی رو
در سیستم های خیلی بزرگ به علت این که حتی زمان برای ریکاوری نداریم و فرصتش رو نداریم از full استفاده نمیشه به جاش از یه مکگانیزیمی به نام mirroring استفاده میشه
نکته : ما در زمان ساخت دیتابیس وقتی میایم COALLATION رو تعیین میکنیم به این معنیه که همیشه زبون اول انگلیسی هستش و ما در حقیقت با انتاخاب COALLTAION زبان دوم رو داریم انتخاب میکنیم برای ذخیره سازی در دیتابیس
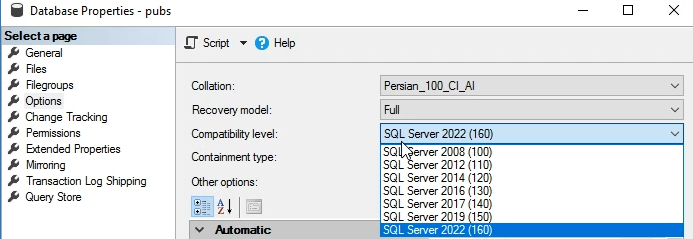
ما میتونیم دیتابیس هایی که ورژن های پایین تر دارن رو ازشون بک آپ بگیریم و ببریم در ورژهای بالاتر ولی برعکسش امکان پذیر نیست
وقتی که بک آپ ورژن هایی پایین تر رو اوردیم داخل ورژن های بالاتر اینجا میایم و compability اش رو تتغییر میدیم به همون ورژن بالاتر و اینطوری خودش میاید تبدیل دیتابیس قدیمی رو به جدید انجام میده
بعضی از مواقع که مثلا برنامه نوشته شده که با ورژن های قدیمی تر compatible هستش دیگه نمیاریم روی ورژن های جدید تر و فقط انتقالش دادیم به engine جدید ولی دیگه ورژنش رو تغییر نمیدیم
برای پاک کردن دیتابیس از این روش استفاده میکنیم :
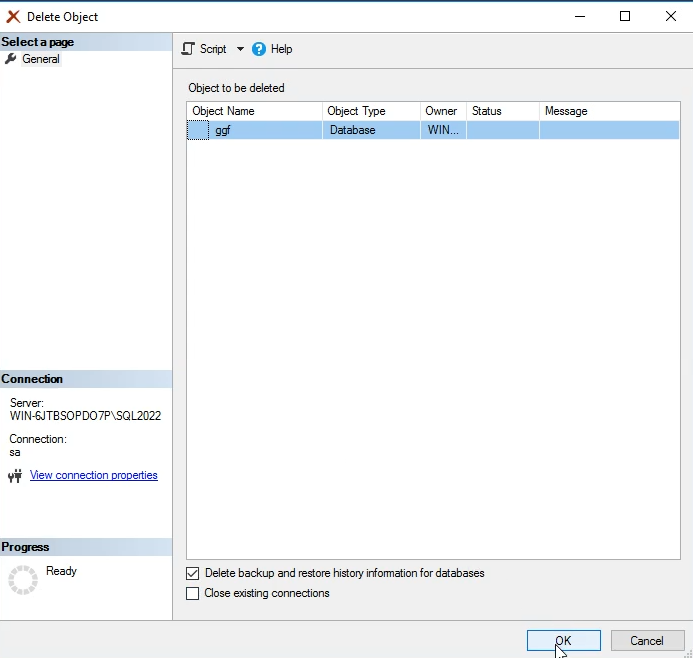
دیتابیس رو با فایل ها mdf و ldf و همه چی رو پاک میکنه
اون تیک connection رو هم بزنیم اول میاد connection رو قطع میکنه و بعد پاکش میکنه

معادل کاری که در قسمت بالا انجام میدیم
اگر بخوایم هم به صورت تستی بیایم Drop رو انجام بدیم بهتره که اول یه محیط transaction درست کنیم و بعد بیایم drop رو انجام بدیم که بعدش اگر خواستیم بتونیم roll back اش کنیم
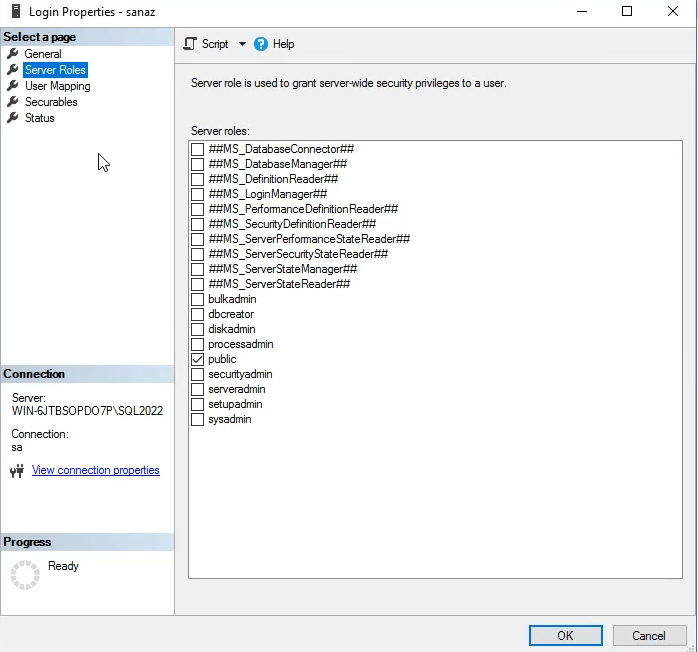
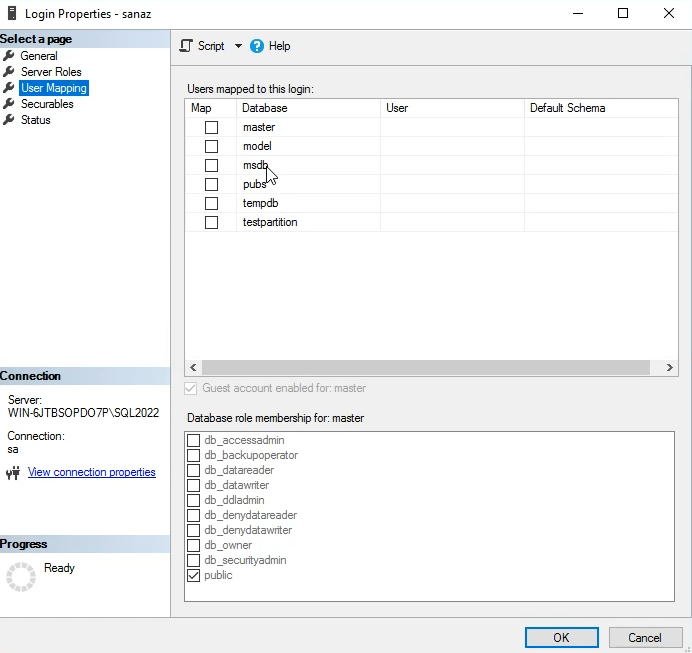
در این دو قسمت بالا میان برای یوزهایی که به دیتابیس ها دسترسی دارن سطوح مجاز دسترسی براشون تعیین میشه
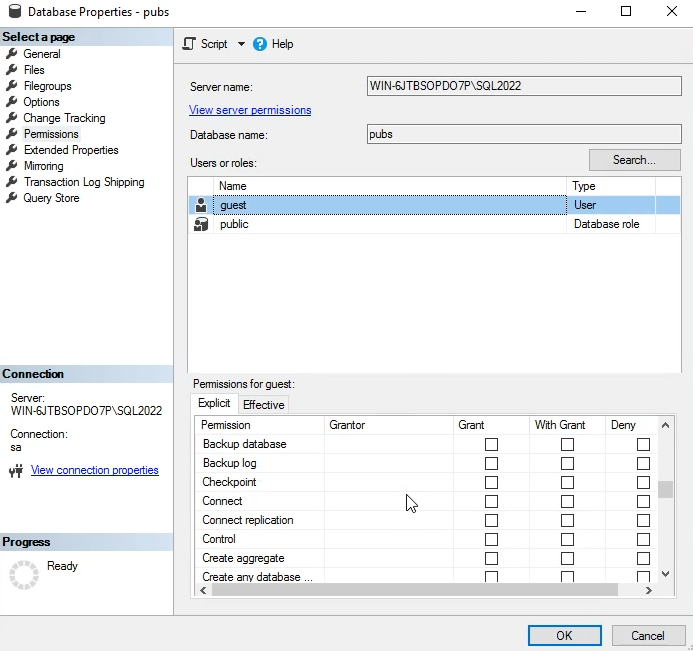
بعد از این قسمت نوع permission های مجاز هم براشون تعیین میشه
جدول ها یک سری اطلاعات مرتبط با هم رو در یک جدول کنار هم قرار میدن و این که خوده جدوال هم میتونن با هم ارتباط داشته باشند
اینطوری میایم یه جدول درست میکنیم در دیتابیسمون
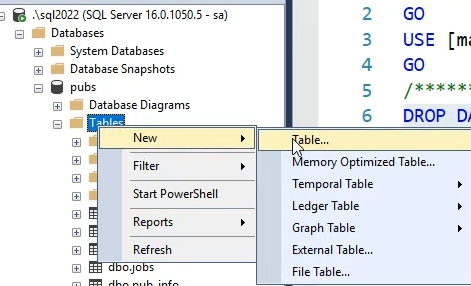
نام گذاری در جدول ها فارسی نباشه و از space به هیچ عنوان استفاده نشه به جاش از __ استفاده کنیم
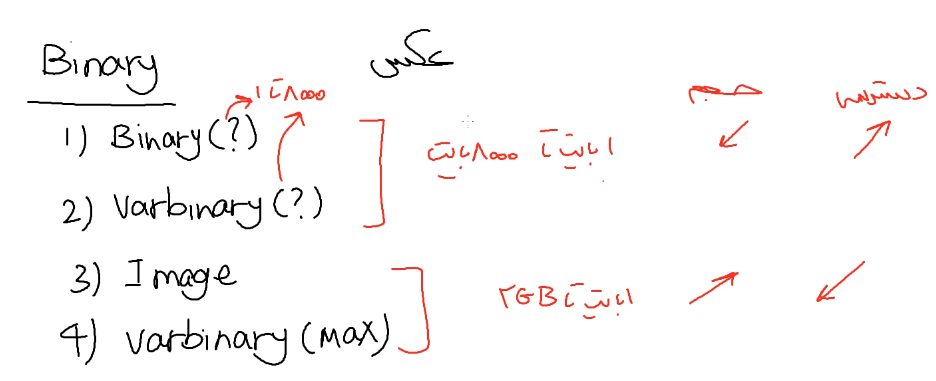
اون علامت سوال به این معنیه که خودمون اونجا تعیین میکنیم که چقدر رو نگه دارن که این مقدار از 1 بایت تا 8000 بایت متغییر هستش و میتونیم از این بین اون مقداری که لازم داریم رو تعیین کنیم
در دسته بندی اولیه به طور مثال نام و نام خانوادگی و عکس همه در کنار هم در دیتابیش ذخیره میشه ولی در دسته بندی دوم دیگه عکس در کنار اطلاعات دیگه نیستش و عکس به صورت جداگانه در یک قسمت دیگه هارد ذخیره سازی میشه و آدرسش میاد در کنار این اطلاعات قرار میگیره و به همین دلیل در نوع دوم سرعت دسترسی پایین تر هستش
اگر فایلمون از 2 گیگابایت بیشتر باشه میشه file stream کلا دیگه توی دیتا بیس ذخیره نمیکنه
و به همین دلیل وفتی که از دیتابیس میایم بک آپ میگیریم دیگه عکس ها با اون فایل های بک آپ گیری در یک جا نیستند و باید بریم از جای دیگه بیاریمشون
و این که image هم depricate شده به دلیل پیچیدگی که در ذخیره سازی این مدل از دیتاها در سخت افزار داره
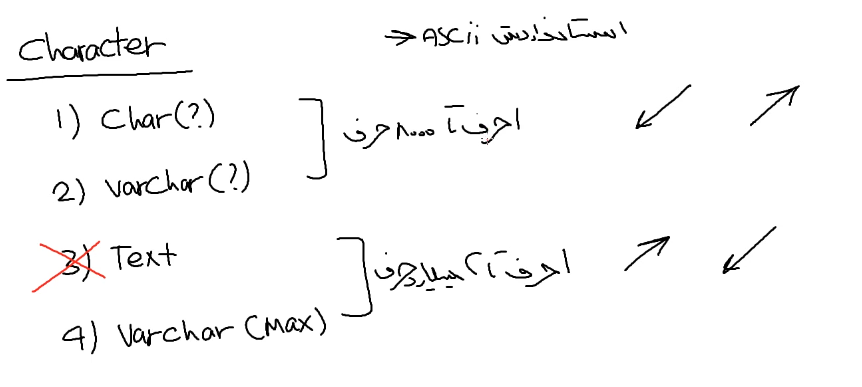
اینجا این دیتاتایپ ها از Ascii استفاده میکنن و این یعنی این که از زبان انگلیسی و زبان colattion این دیتا تایپ ها ساپورت میشن
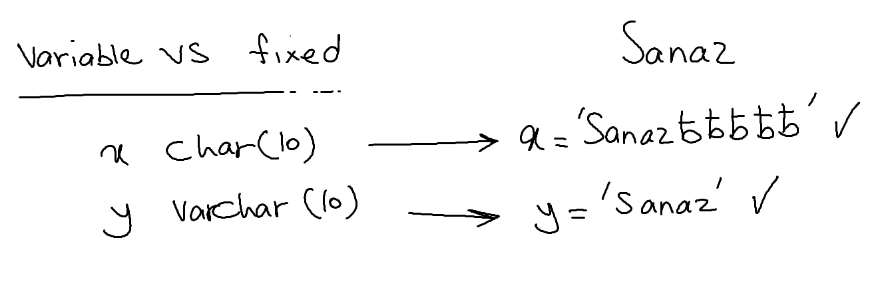
حالا فرق fixed با variable چیه توی اولی که fixed هستش میاد هر چقدر از مثلا 10 که تعیین کردیم فضا مونده باشه اون رو میاد با white space پرش میکنه ولی دومی نه اینطوری نیست
سرعت دسترسی در بالایی بیشتر هستش چون هر تیکه از داده معلومه که در چه قسمتی قرار داره بعنی این که اولین داده از 0 تا 9 و بعدی از 10 تا 19 و دیتاهای بعدی ولی در نوع دوم چون ممکنه که متغییر باشه باید بره و دیتا رو پیدا کنه و بعد برگردونه

خوب یه روش استفاده از این دیتاتایپ ها اینه که بیایم به طور مثال شماره ملی رو توش سیو کنیم چون شماره ملی رو در دیتا تیاپ های عددی نمیتونیم سیو کنیم چون صفر قبل از عدد در اون مدل معنی نداره و حذف میشه
جایی که مطمئن هستیم که عدد همیشه پر میشه مثل شماره کارت ملی یا تلفن

توی uni code هر زبانی رو میتونیم ذخیره کنیم ولی حجم بیشتری رو اشغال میکنه و بک آپ گیری طبیعتا حجم بیشتری رو میخواد و انتقال دیتا روی شبکه هم حجم بیشتری رو میبره

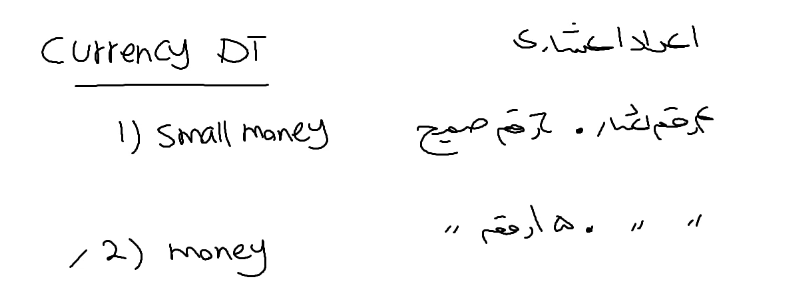
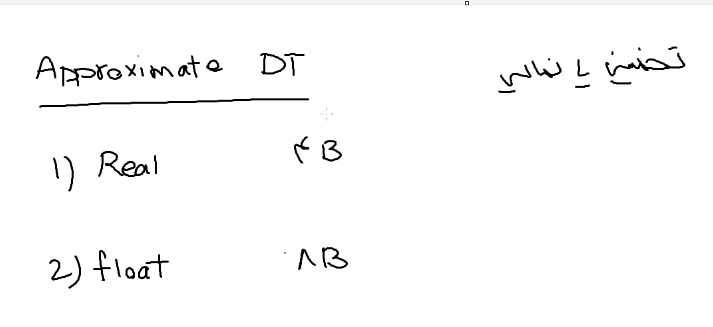
برای محاسبات خوب نیستن چون میاد اعداد رو روند میکنه
 از بالا به پایین سرعت دسترسی کمتر میشه
از بالا به پایین سرعت دسترسی کمتر میشه
اگر اعداد نسبتا کوچک هستن از currency استفاده بشه خوبه
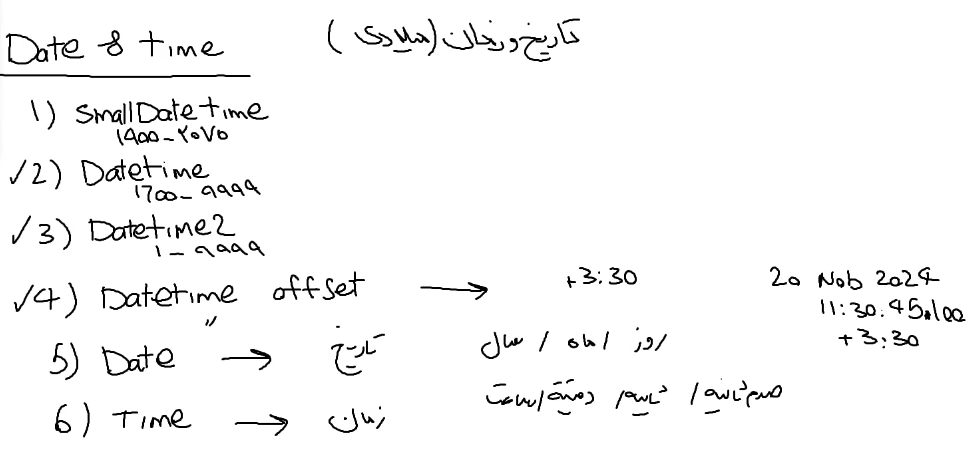
خوب sql server تاریخ شمسی رو ساپورت نمیکنه ولی oracle ساپورت میکنه
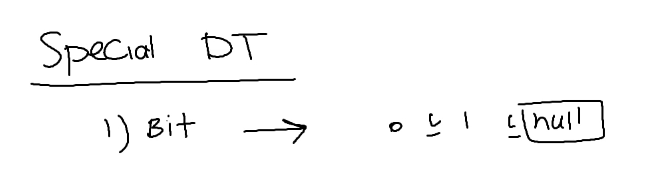
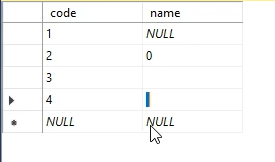 خوب null با صفر و فیلیدی که هیچی توش نیست و یا یه space توشه متفاوت هستش ، null یعنی هنوز هیچ اطلاعاتی به این فیلد اختصاص داده نشده و یا مقدار دهی نشده
خوب null با صفر و فیلیدی که هیچی توش نیست و یا یه space توشه متفاوت هستش ، null یعنی هنوز هیچ اطلاعاتی به این فیلد اختصاص داده نشده و یا مقدار دهی نشده
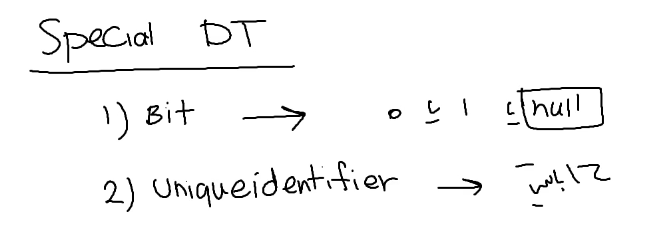
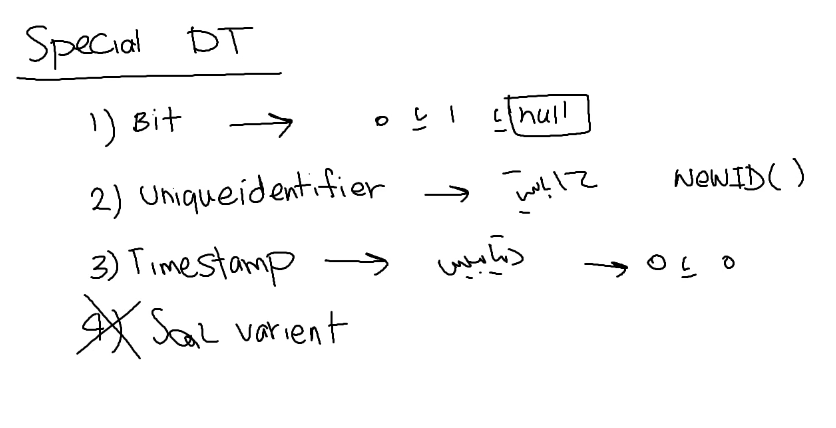
خوب uniqueidentifer برای زمانی استفاده میشه که بخوایم مقادیر تصادفی ایجاد کنیم ، نیوتن با الگوریتم new id برای تولید این اعداد تصادفی استفاده میشه
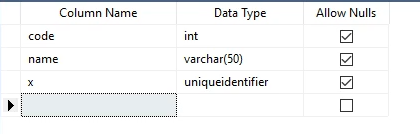
بعد میخوایم این اطلاعات رو پر کنیم
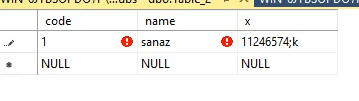
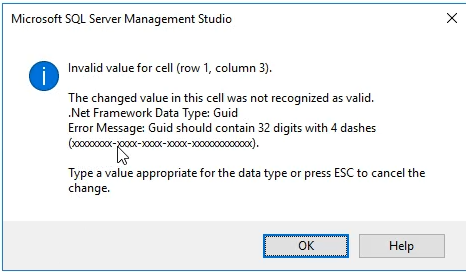
قسمت x خودش به صورت اتوماتیک پر میشه
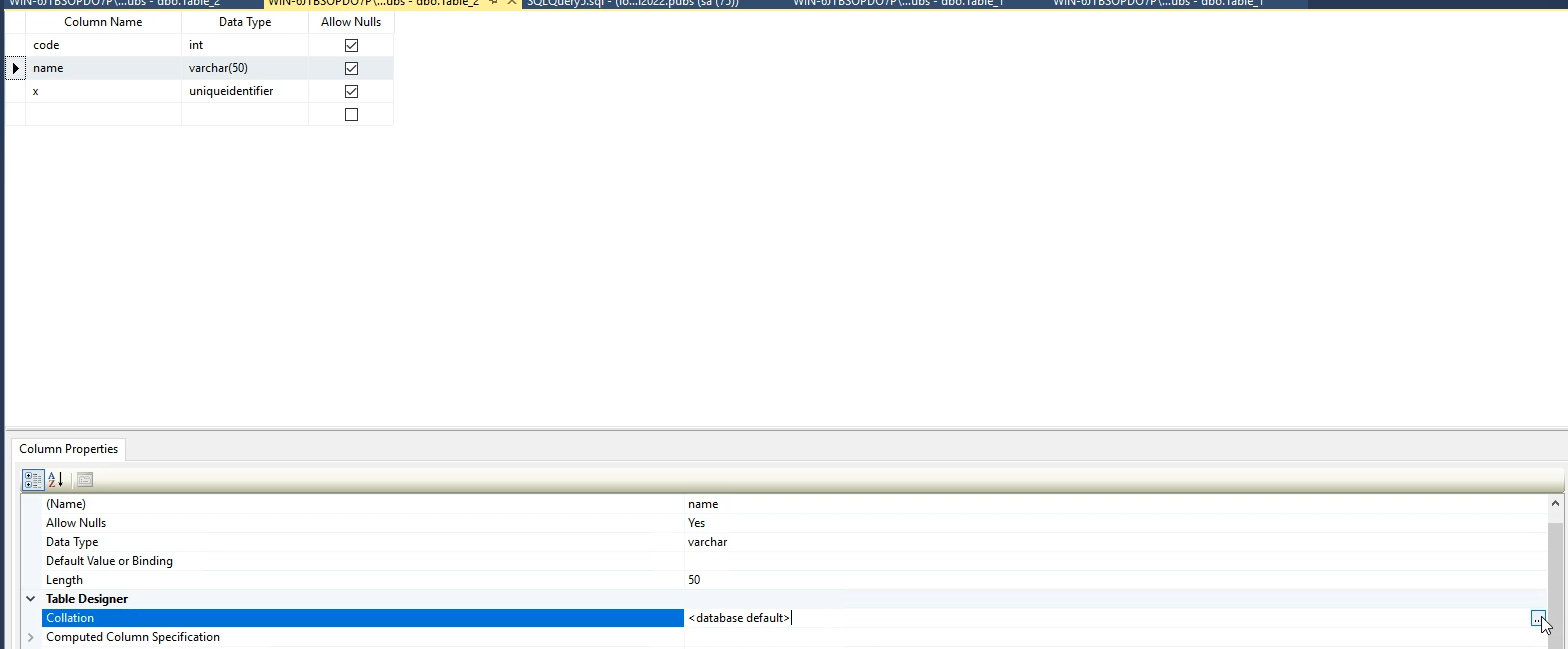
خوب اینجا میتونیم حتی برای هر کدوم از فیلد های توی جدول بیایم به صورت جداگانه coallation تعیین کنیم
خوب یه قسمتی توی proprties هستش که میگه به صورت دیفالت برای مقدار اون فیلد چی بزارم

اینجا یعنی اگر هیچ مقداری براش تعیین شنده بیاد و ali توش بنویسه
خوب اینجا به طور مثال برای پر کردن x میایم و از الگوریتم new id استفاده میکنیم


خوب timestamp وقتی که ما یه دیتابیس رو میسازیم ساخته میشه و مقدارش صفر یا صفر هگزادسیمال هستش
هر جا هم ازش استفاده بشه به صورت incrimental عددش یه دونه یه دونه میره بالا
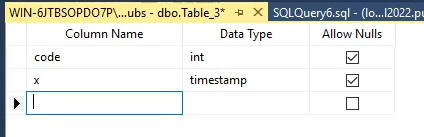
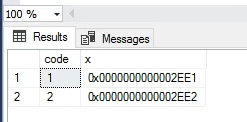
حالا یه جدول دیگه توی همین دیتابیس درست میکنیم بعد فیلدی که توش بهش مقدار میدیم میاد آخرین time stamp که توی این دیتابیس هستش رو پیدا میکنه و بهش 1 اضافه میکنه و مینویستش
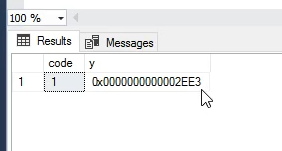
نکته اینه که time stamp در سطح دیتابیس کنترل میشه و استفاده میشه
حالا میریم توی table قبلی و آپدیت و تغییر روش انجام میدیم و کد 2 رو به 3 تغییر میدیم
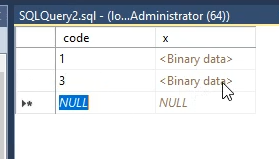
حالا دوباره TIMESTAMP اش رو نگاه کنیم میبنیم که تغییر کرده
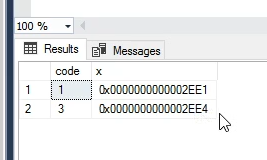
موتونیم ازش به عنوان change detector استفاده کنیم
2:11
سناریو فرض کنید که میخوایم حقوق یک شخص رو بالا ببریم ، حالا این بالا بردن حقوق در یک لحظه توسط دو نفر میخواد انجام بشه یعنی این که به طور مثال مدیر مالی و حسابدار میان و هر دو اطلاعات حقوقی شخص رو میگیرن بعد به طور مثال حسابدار میاد حقوق رو 2 برابر افزایش میده و مدیر مالی هم میاد 3 برابر افزایش میده اینجا اتفاقی که میوفته اینه که خطای همزمانی اتفاق میوفته که برای رفع کردنش یه سری راه حل داریم
راه حلش اینه که برای هر فیلد بیایم timestamp در نظر بگیریم و همیشه همراه با اون دیتای فیلد اون timestamp رو باهاش بگیریم
اینطوری مثلا یه حسابدار میاد اطلاعات حقوقی رو میگیره با timesmap و حقوق رو افزایش میده ، حالا وقتی که مدیر مالی میخواد افزایش حقوق رو انجام بده نمیتونه ، چرا؟ چون مدیر مالی اومده دیتا رو با time stamp قبل از تغییر حسابدار گرفته و وقتی که میخواد اطلاعات جدید رو ثبت کنه به دلیل این که time stamp جدید با timestamp قدیم برابر نیست نمیتونه آپدیت رو انجام بده و مجبوره اول اطلاعات جدید رو با timestamp جدید بگیره و بعد آپدیت رو انجام بده
معمولا این روش با استفاده از time و تاریخ به صورت معمول انجام میشه و از timestamp استفاده نمیشه
در دیتابیس ها همیشه یه تاریخ ثبت در نظر میگیرند و تاریخ آخرین تغییرات
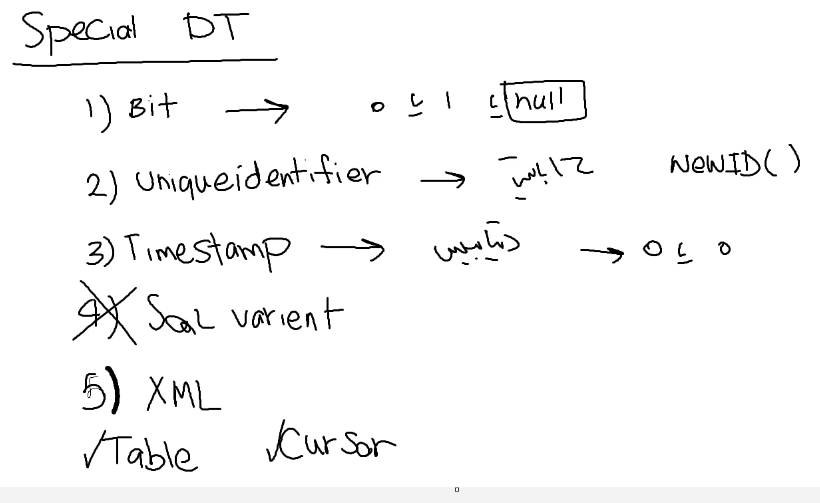
خوب Sql varient میتونه هر دیتایی از هر تایپی داخلش ذخیره بشه و این اصلا خوب نیست
حالا میخوایم این اطلاعات رو به صورت xml خرچی بگیریم
این شکلی میشه :

نکته ای در خصوص xml ها هستش اینه که دیتاهایی که nuil هستش رو اصلا نمیاره :
 به طور مثال رکورد 7 قیمتش null هستش
به طور مثال رکورد 7 قیمتش null هستش
 این ها برای زمانی استفاده میشه که برنامه نویس ها میخوان دیتا ها رو نمایش بدن یا باید xml بگیرن یا json برای نمایش و انتفال دیتا
این ها برای زمانی استفاده میشه که برنامه نویس ها میخوان دیتا ها رو نمایش بدن یا باید xml بگیرن یا json برای نمایش و انتفال دیتا
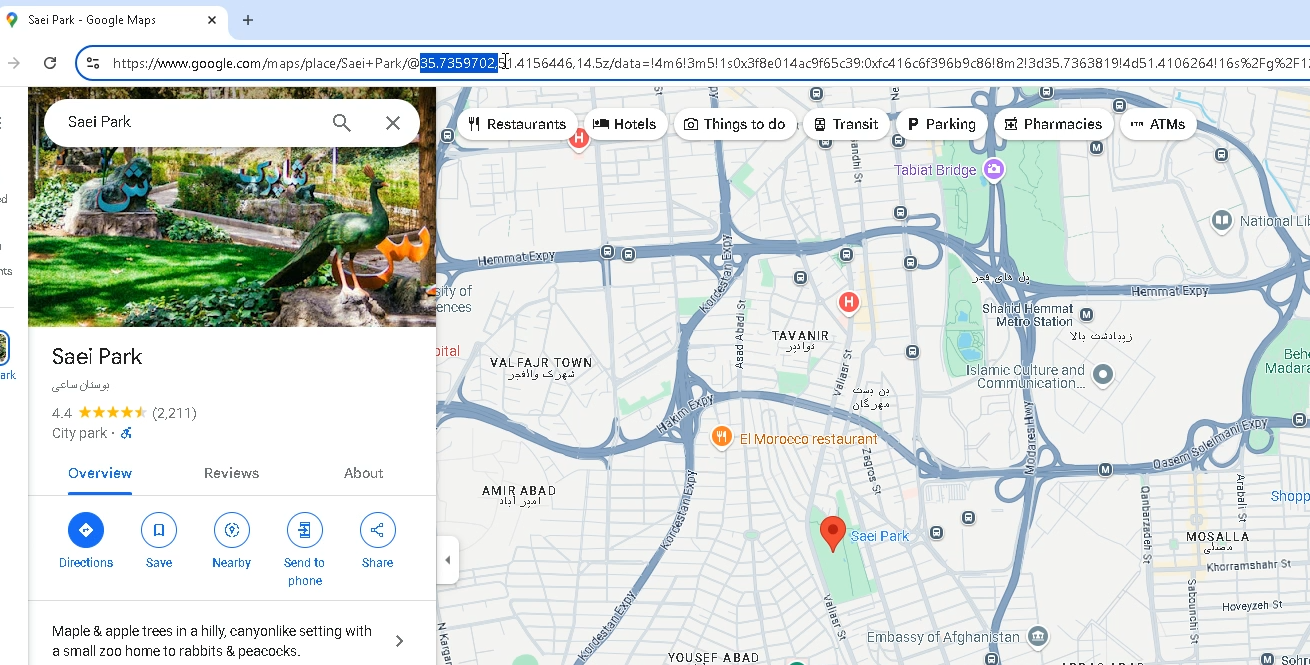
اولی میشه طول و عرض جغرافیایی
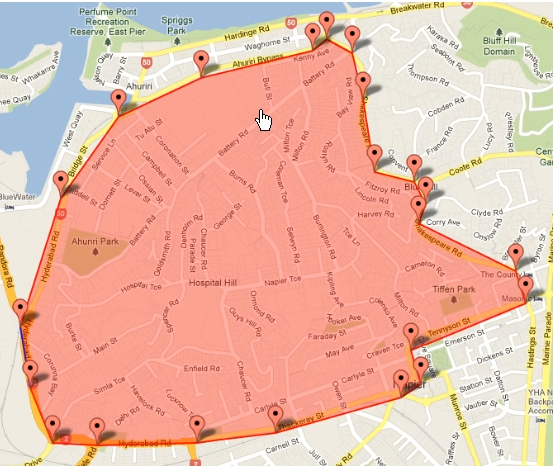
دومی یه zone جغرافیای رو ذخیره میکنه :
خوب حالا برای بدست آوردن تایم و تاریخ میایم اینطوری عمل میکنیم :
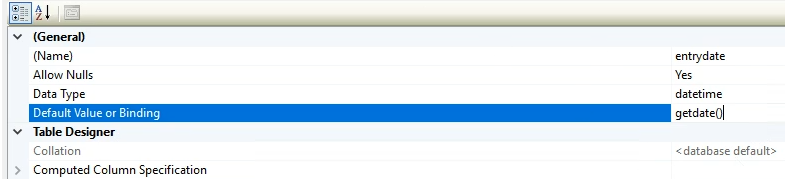
از تابع getdate استفاده میکنیم به صورت اتومات این کار در زمان پر شدن یا تغییر دیتا ها انجام بشه
خوب حالا میرسیم به فیچر identity که نکته ای که هست اینه که ما فقط میتونیم یک فیلد رو در هر جدول براش این فیچر رو در نظر بگیریم و اون column باید حتما از جنس int باشه و باید غیر null باشه و اینجا defualt binding هم دیگه معنایی نداره

برای فعال کردنش هم کافیه که identitty specification رو yes بزنیم ، خوب identity seed یعنی از چه عددی شروع بشه و identity incriment هم یعنی گامش چند تا چند تا باشه برای افزایش
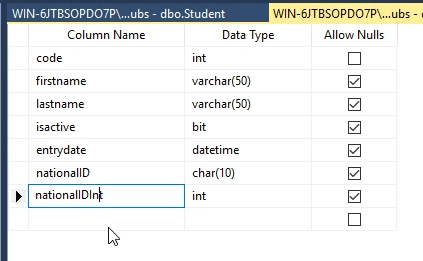
خوب معمولا میایم natinal id و natinal id int رو در نظر میگیریم تو حالتی که int هستش باید بیایم و عدد رو بشمریم و هر تعدادی که کم بود صفر رو بزاریم پشتش ولی این یه Cost زمانی داره ولی از اون سمت موقع سرچ کردن ، سرچ روی اعداد بهتره تا character
روش میکسش اینطوری میشه که موقع سرچ کردن از int استفاده میکنیم و موقع های دیگه از character

بدون اعشار و ممیز و چیزای دیگه توش نمینویسیم
خوب حالا یه نکته ای که هست وقتی که داریم جدول ها رو در دیتابیسمون میسازیم یه پیشوند میگیره
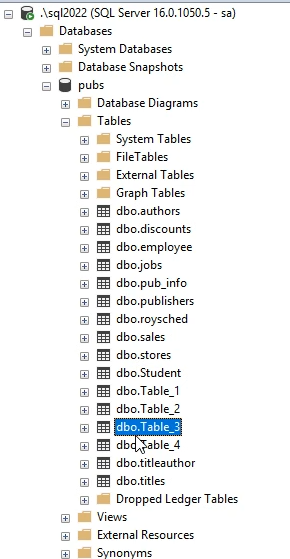
به طور مثال اینجا پیشوندش dbo هستش که بهش میگن schima که بعدا در مورد access ها و permission ها استفاده میشه
DBO = Data base owner
اگر بخوایم select انجام بدیم روی جدول ها schima ای که میخوایم فراخوانی کنیم اسمش چیزی به غیر از dbo باشه اون اسم رو هم باید بنویسیم ولی برای اون هایی که dbo دارند لازم نیست
خوب حالا میخوایم یه جدول رو با استفاده از کد درستش کنیم :

برای درست کردن جدول میزنیم create table بعد اسم جدول رو میزنیم , بعدش توی پرانتز میایم اسم فیلد رو میزنیم و بعد نوع و تایپ اون داده رو تعیین میکنیم و بعد میایم اگر خصوصیتی داره یا میخوایم براش خصوصیتی تعیین کنیم یا تابعی یا فانکشنی که میخوایم استفاده کنیم رو مینویسیم و بعد , میایم فیلد بعدی رو مینویسیم و تا آخر همینطوری
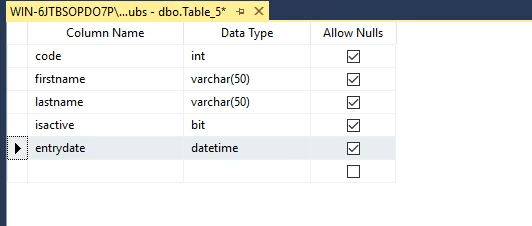
به طور مثال اومدیم identity رو نوشتیم و توی پرانتز عددی که ازش شروع بشه رو نوشتیم و بعد نوشیتم که چند گام چند گام باید افزایش پیدا کنه، برای first name امکان null بودن رو گذاشتیم , و برای entry date هم اومدیم گفتیم که default دیتایی که قراره توش قرار بگیره بیاد از تابع get date استفاده کنه
خوب برای قسمت اول ما اومدیم و code رو نوشتیم و بعد int
خوب حالا میایم و یه جدول میسازیم :

و میگیم که a , b رو داریم و c میشه a+b +1 خوب این اینطوری در جدول به ما نمایش داده میشه ، همونطوری که میبینید دیتا تایپی براش نذاشتیم
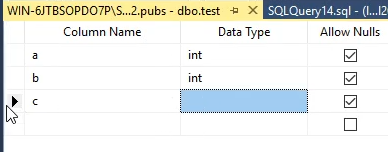
هیچ دیتا تایپی نداره و نکته ای که
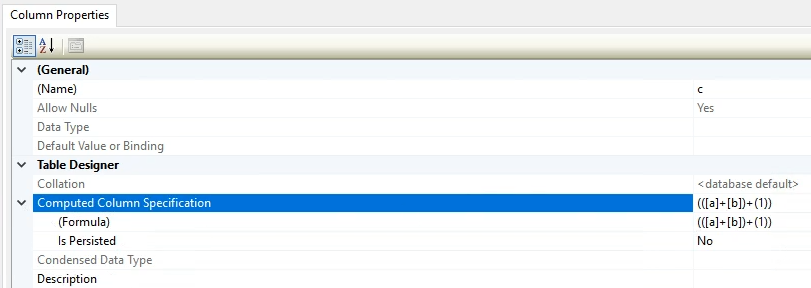
حالا is persist اگر no باشه این column هیچ فضایی رو در هارد هیچوقت اشغال نمیکنه هیچ فضایی در هارد رو نمیگیره و هر زمان که بخوان فراخونیش کنیم میاد با استفاده از a و b میاد میسازتش و بهمون میده
اگر yes باشه هم میره توی هارد ذخیره اش میکنه
اگر فرمول خیلی پیچیده نیست no بزنیم اگر فرمولش سنگینه و پیچیده است yes باشه
حالا فرض کنید که میخوایم first name و last name رو به هم بچسبونیم
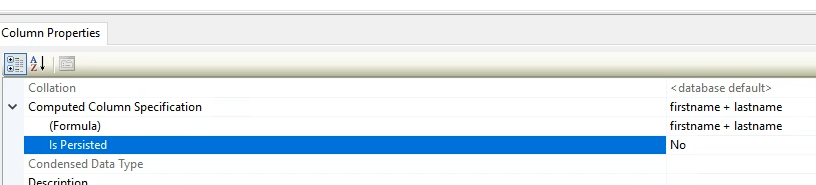
معمولا اینطوری ، از اینجا تغییرات رو اعمال نمیکنیم
تمام دستورات رو اینجا نوشته