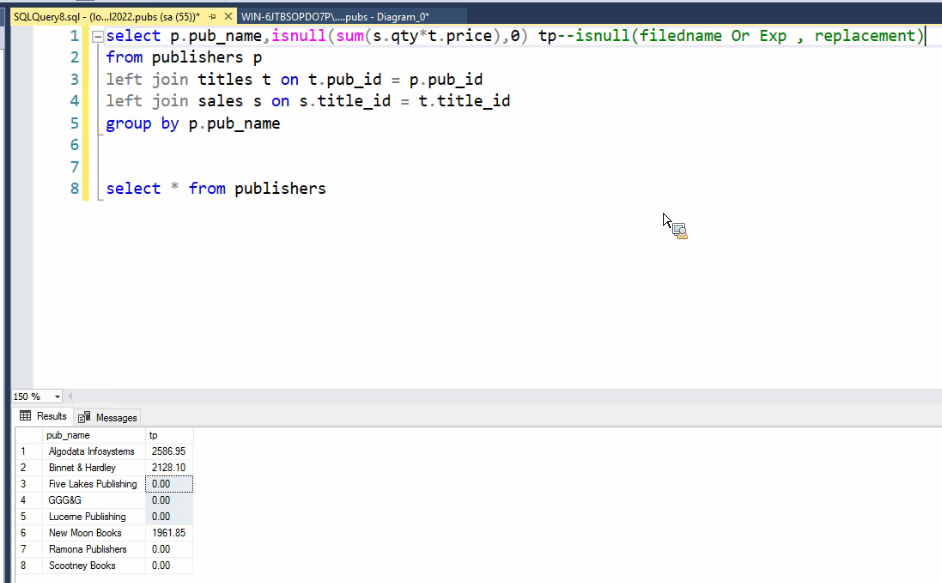
بک آپ گیری رو معمولا ادمین انجام میده ولی دونستنش خوبه :
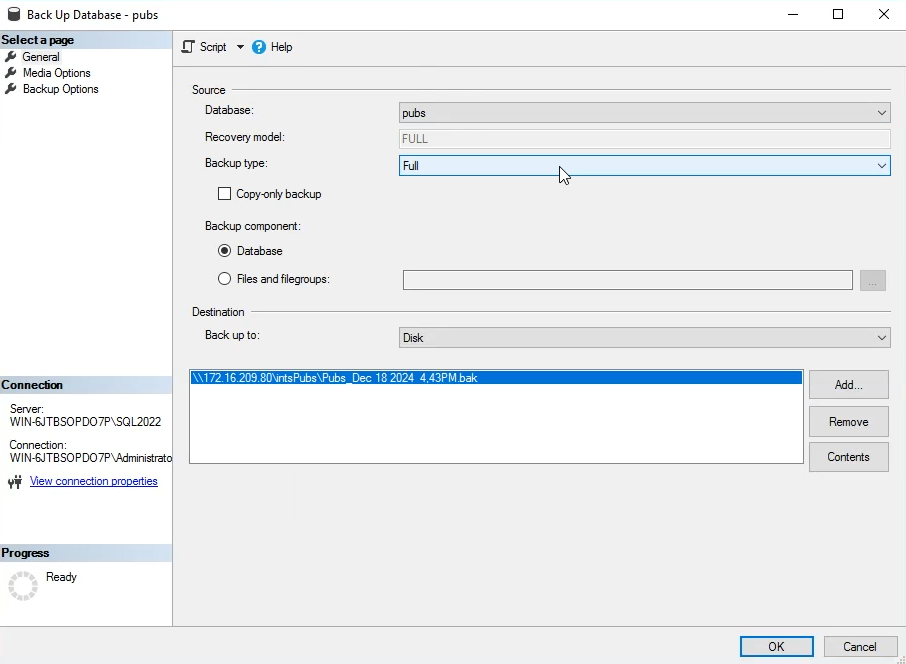
اون فیلد اول میایم و اسم دیتابیس رو انتخاب میکنیم از توی این انجین
فیلد بعدی داره میگه که نوع و جنس ریکاوریش از نوع full هستش
نوع full میاد از تمامی فایل های mdf و ndf به صورت یکپارچه بک آپ میگیره این یعنی این که اگر این بک آپ جای دیگه ببریم و اجرا کنیم دقیقا میشه همون دیتا بیس با همون ساختار و اطلاعات و همه چی
نوع diffrential میاد نسبت به بک آپ قبلی چیزهایی که اضافه شده رو میاد بک آپ میگیره
اول میایم یه فول بک اپ میگیریم و بعدش اگر diffrential بگیریم میاد نسبت به full اون چیزهایی که اضافه شده رو بک آپ میگیره و بعدی رو هم اگر diffrential بگیریم نسبت به بک آپ diffrential قبلی میاد اطلاعات و چیزهایی که اضافه شده رو بک آپ میگیره
حجم diffrential ها کمتره ولی نکته ای که وجود داره اینه که باید این مدل بک ها پشت سر هم وجود داشته باشن.
اگر قسمتی از این مدل بک آپ ها حذف بشه اطلاعات اون قسمت هم حذف میشه و از بین میره
اگر مدل recovery mode از نوع full نباشه گزینه ی transactinal log رو نمیبینیم .
چون اگر recovery model از نوع full باشه تمامی اطلاعات در LDF موجوده اگر simple باشه فقط اون قسمت آخرش رو داریم
نوع transactianl log فقط بک آپ فایل های LDF هستش
مورد بعدی این رو داره میگه که آیا بیایم از کل دیتابیس بک آپ بگیریم و مورد بعدی به صورت کاستوم از اون قسمتی که میخوایم میتونیم بک آپ بگیریم :
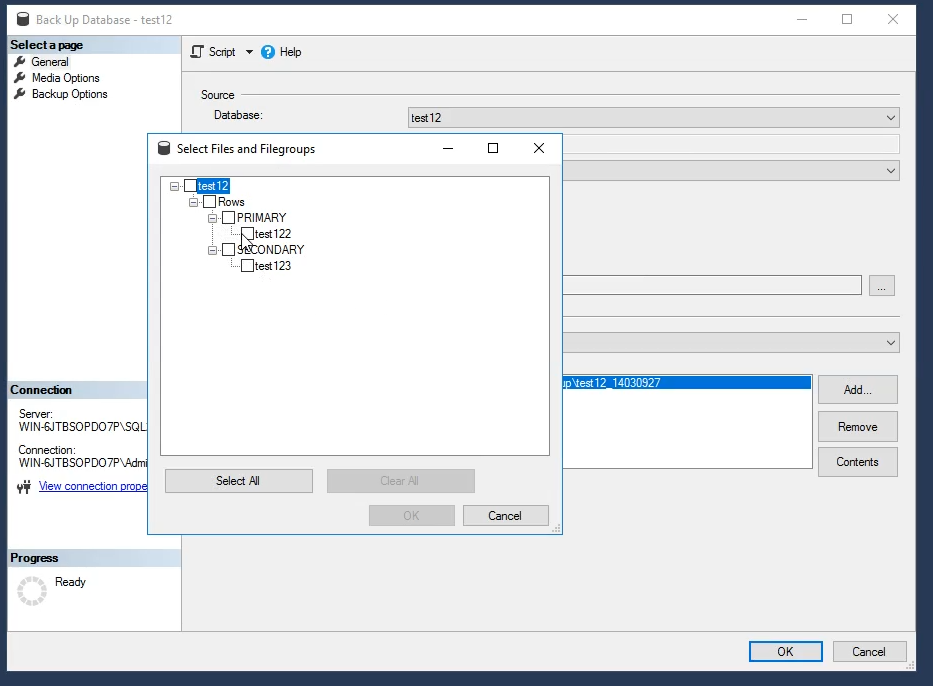
مورد بعدی داره میگه که از که دیتابیس رو توی سیستم خودمون بک آپ بگیریم یا ببریم در Share و یه سیستم دیگه
خوب برای اسم هم این رو در نظر بگیرید که تاریخ هم بزاریم :
اگر اسم بک آپ ها یکسان باشه میره دوتا فایل رو توی هم میریزه و تمامی دیتا هم با هم قاطی میشه و دیگه نمیشه ازشون استفاده کرد
جلوتر با tsql میایم بهش ساعت و دقیقه هم میدیم چون در طول روز ممکنه که چند بار بخوایم بک آپ بگیریم
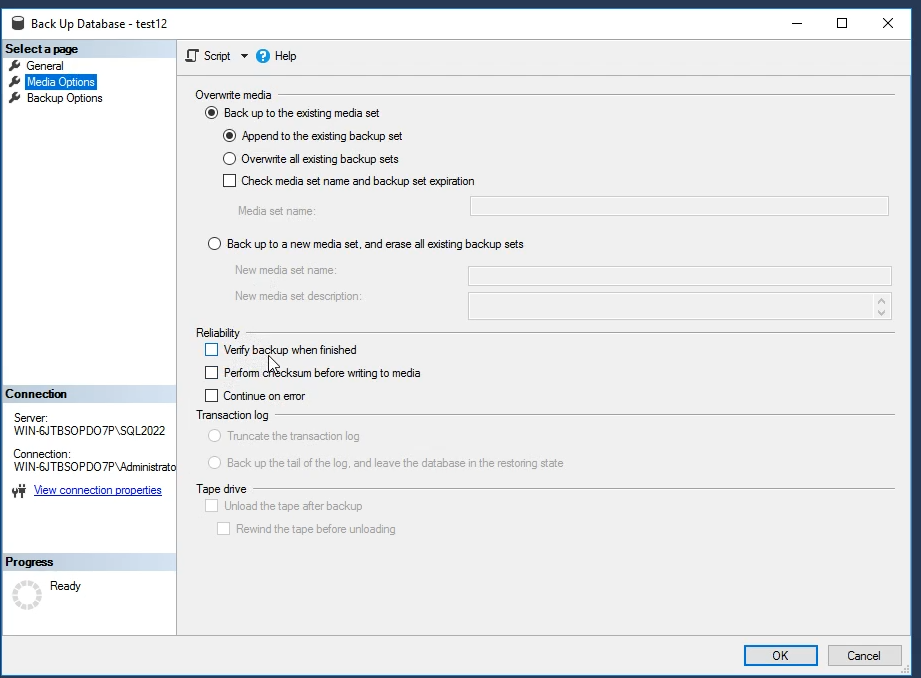
خوب اگر verfiy backup when finished خوب با زدن این تیک بعد از این که بک آپ تموم شد میره دوباره میارتش به صورت background task و چکش میکنه و بعد اگر اوکی بود پیام میده که همه چی اوکیه ، این روش یکم شاید زمان بیشتری ببره ولی مطمئن تره
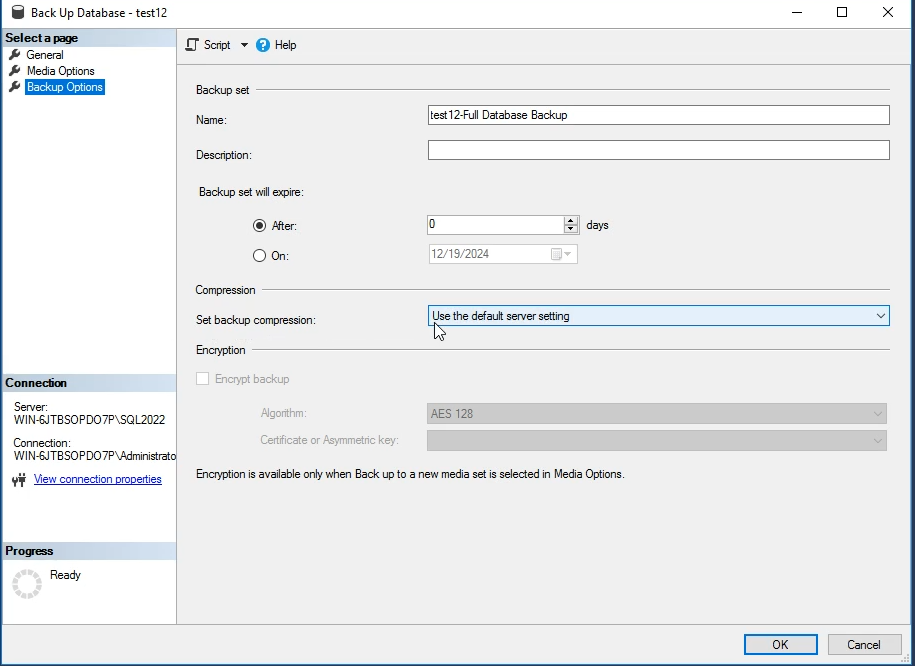
خوب اینجا نکته ای که وجود داره اینه که اگر زدیم که بک آپ رو به صورت فشرده در بیاره

حتما اون تیک مرحله قبل رو بزنیم که حتما چکش کنه
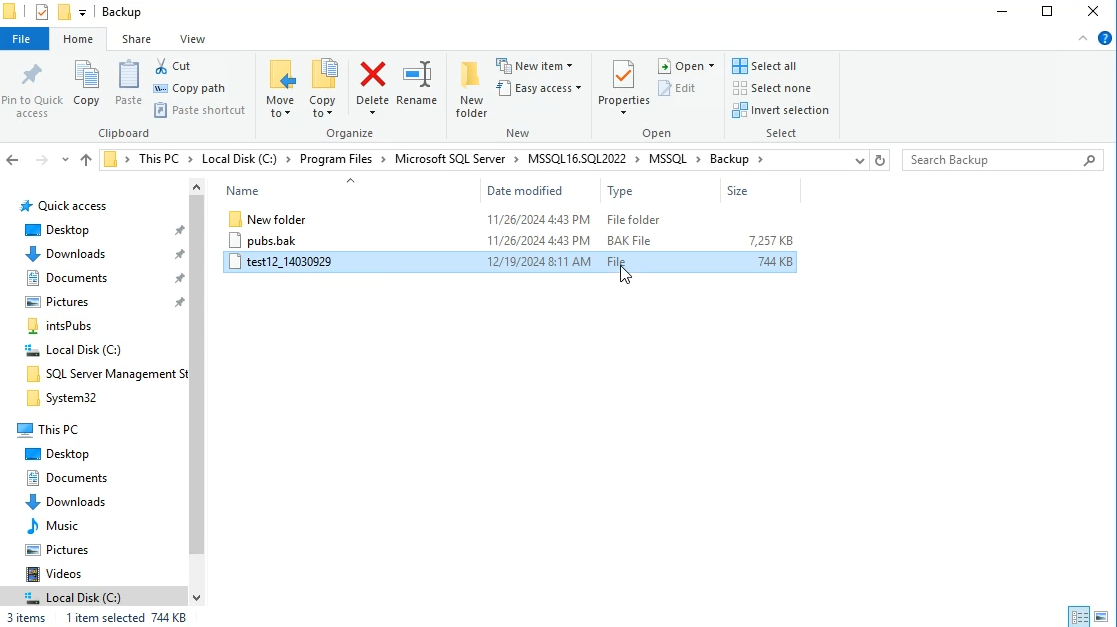
این جا ما یه چیزی داریم که هیچ پسوندی نداره ولی داستانش اینه که اونجایی که داریم براش اسم میزاریم بیایم و پسوند .bak رو بهش اضافه کنیم
نکته ی که وجود داره اینه که باج افزارها اولین فایلی که دنبالش میگردن همین .bak هستش
خوب حالا اگر بخوایم یه بک آپی رو برگردونیم اگر بخوایم این کار و کنیم اول بهتره که اسم اون دیتا بیس که الان توی دیتا بیس هستش رو عوض کنیم و مسیرش رو هم با اون مسیری که بک آپ هستش متفاوت بزاریم و بعد بک آپ رو بیاریم بالا
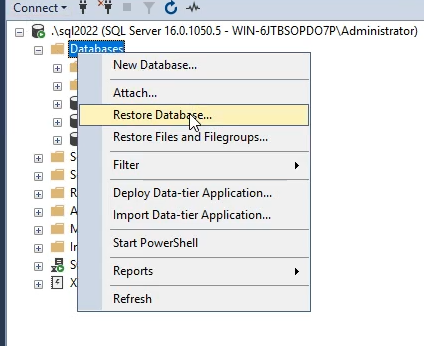
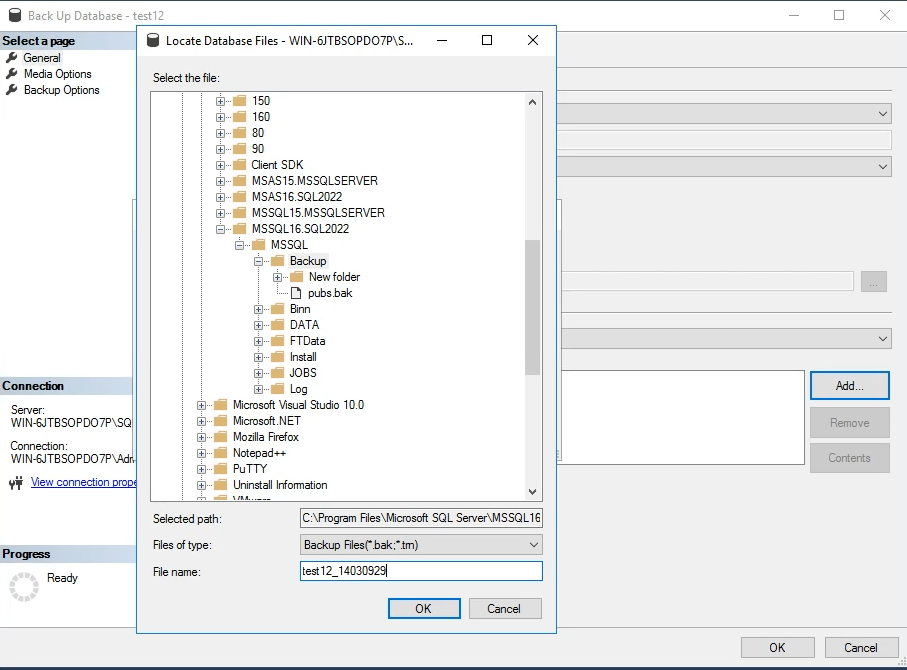
الان میخوایم دیتابیس test 12 رو بیایم restor کنیم
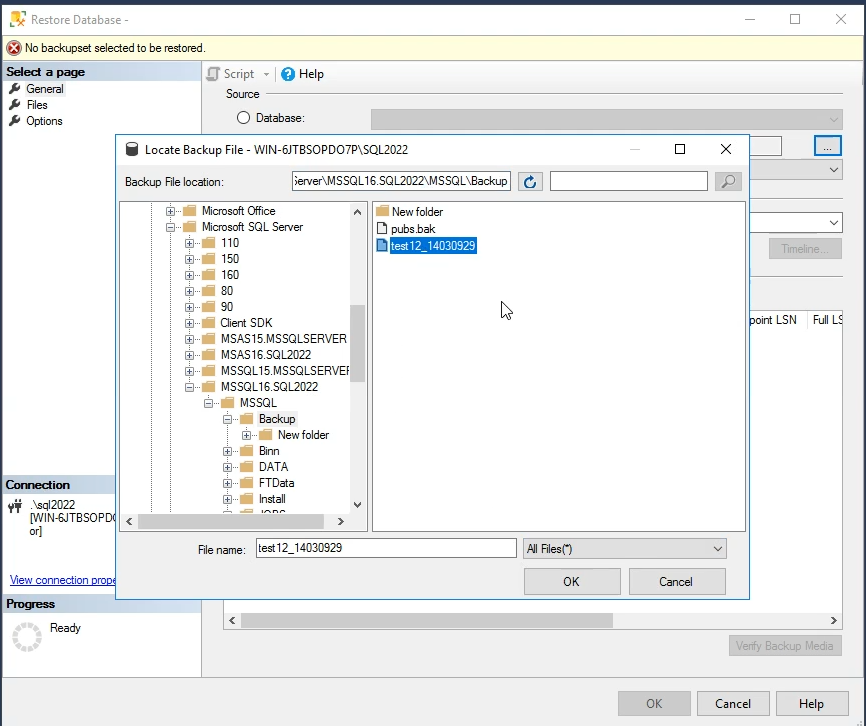
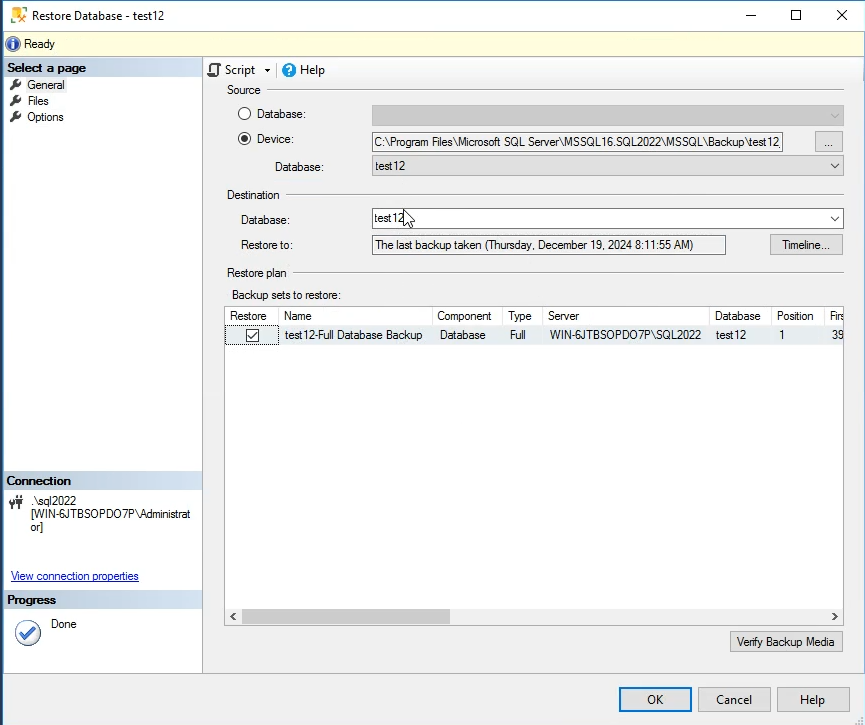
خوب توی حالت بالا همه چه اوکی restor میشه
حالا میخوایم یه دیتابیسی رو که در حال حاضر توی engine هستش رو بریم بک آپش رو جداگانه بیاریم
به طور مثال ما الان pubs رو داریم و میریم از روی بک آپ pubs اون رو resor میکنیم
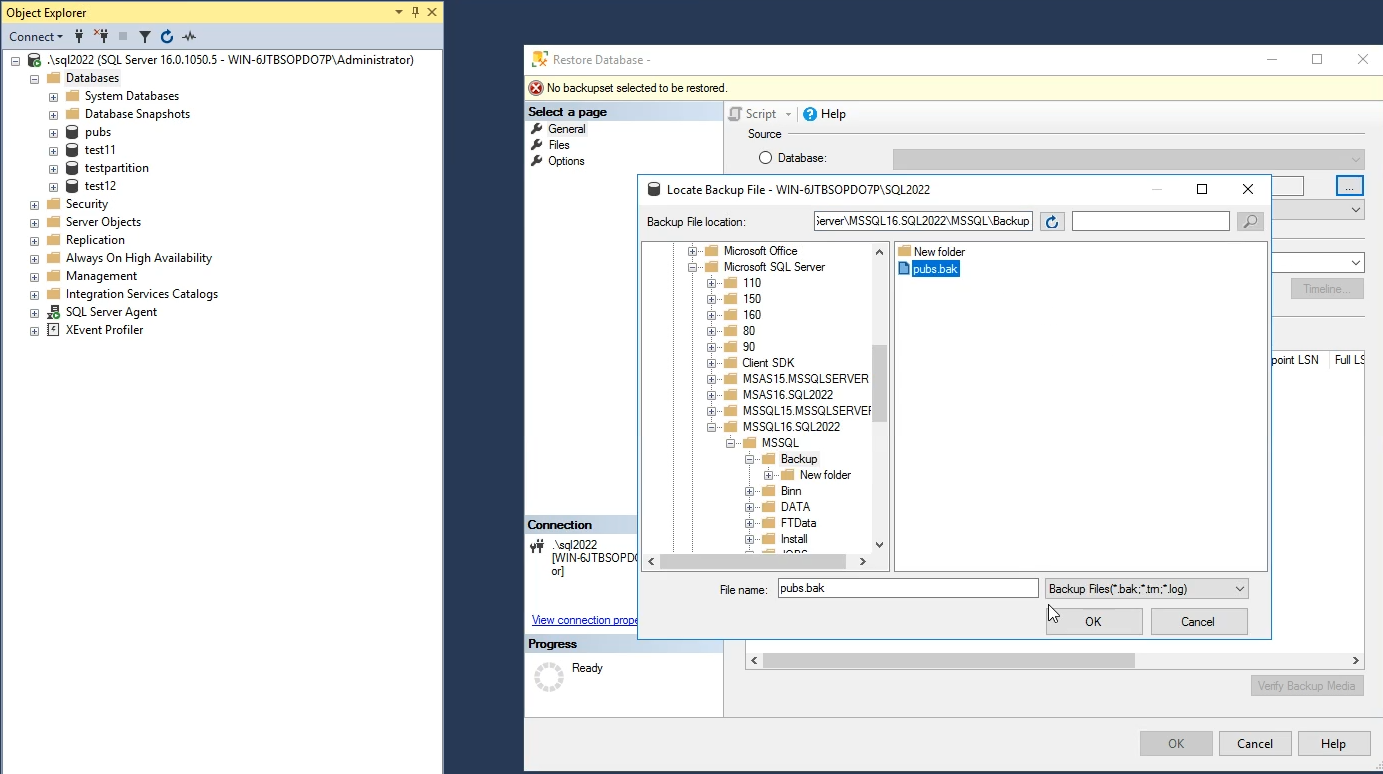
اینجا اسمش رو تغییر میدیم و وقتی که اسمش رو تغییر میدیم خودش به صورت اتوماتیک اسم فایل mdf و ldf رو تغییر میده
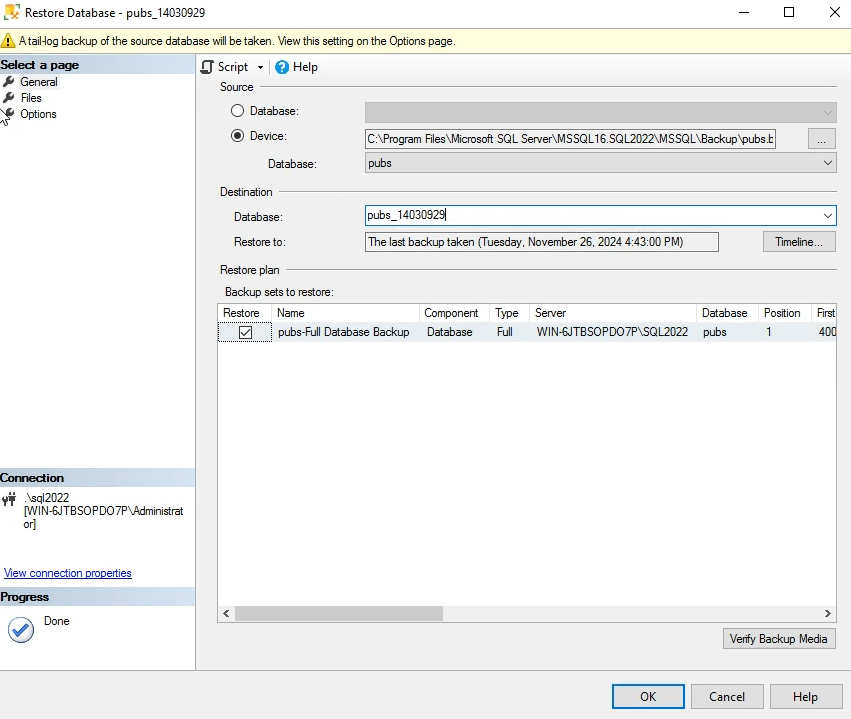
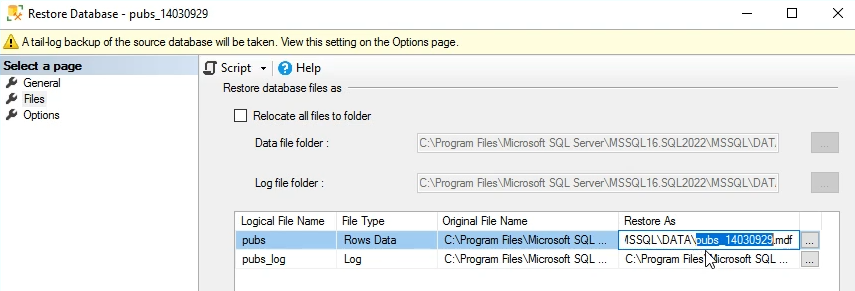
حالا ما برای این که همه چی اوکی باشه باید فایل ذخیره سازیشون رو هم باید جدا کنیم یعنی یه جایی به جز فولدی DATA که دیتابیس قبلی pubs داخلش هست انتخاب کنم ولی انجا این کارو نمیکنم
و نتیجه اش میشه این :
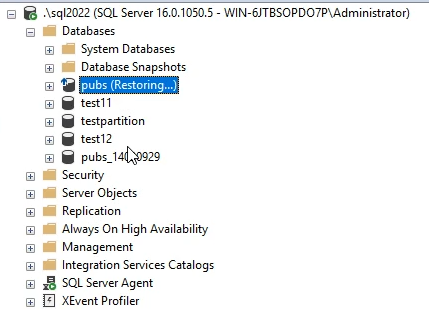
و دیگه از اون pubs (restoring) نمیشه استفاده کرد و کلا میپوکه
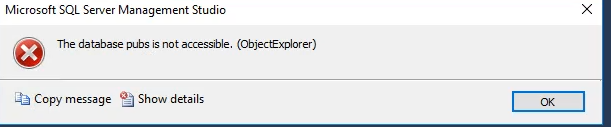
اینجا به دلیل این که این دوتا دیتابیس هر دو یه فایل مشترک دارند به مشکل میخورن و خوده engine هم فکر میکنه این دوتا یکی هستن و یکی رو میبره روی mode restoring و دسترسی بهش قطع میشه
اینجا دیتابیس pubs یه file stram که فایل های بیشتر از 2 gb رو توش ذخیره میکنن داره که وقتی که میخواد چیزی توشون ذخیره بشه میره توی یه قسمت دیگه از هارد و فقط آدرسش میاد داخل دیتا بیس قرار میگیره و بعد چون file stream هاشون هم نام هستند این مشکل ایجاد میکنه ، اینجا ما به دستورات admin نیاز داریم
خوب حالا برای این که یه script رو باز کنیم این کار و میکنیم :

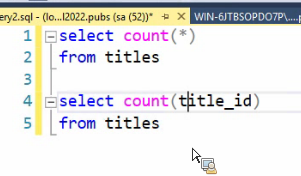
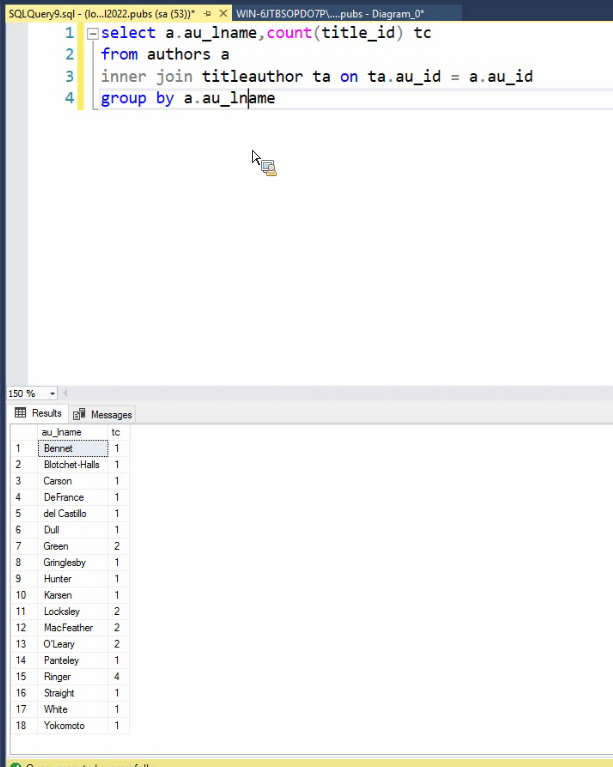
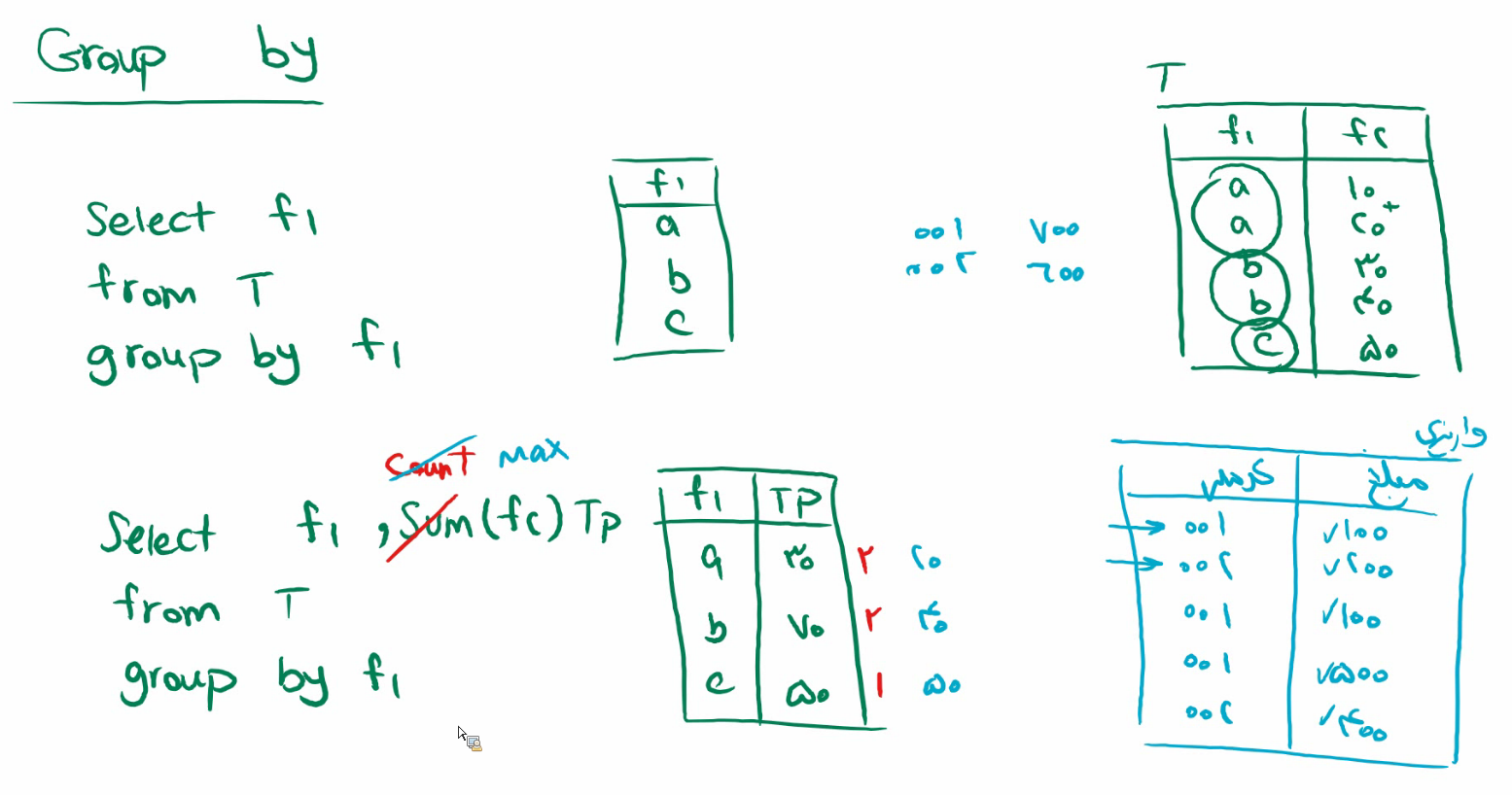
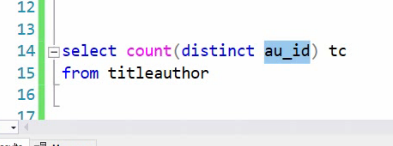
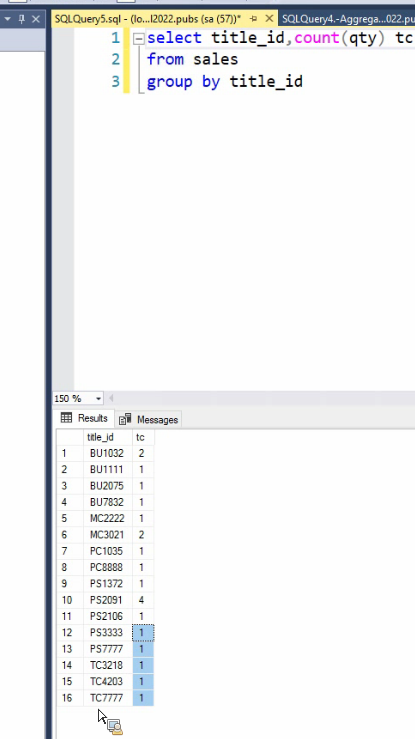
اولی : وقتی که میخواد بشمره کل رکورد رو میاره توی رم و بعد میشماره
دومی : فقط میره title id رو میاره و میشمره
دومی سرعتش خیلی بیشتره
نکته :null در توابع aggrigate تاثیر داده نمیشود بهترین حالت برای شمارش اعضای جدول اینه که روی primery key ها بزنیم چون هیچوقت null نمیشن
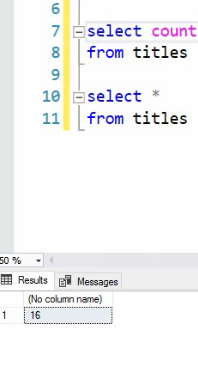
چون وقتی که میخوایم ازش به صورت Nested استفاده کنیم وقتی که no cloumn name باشه نمیتونیم توی حالت nested ازش استفاده کنیم
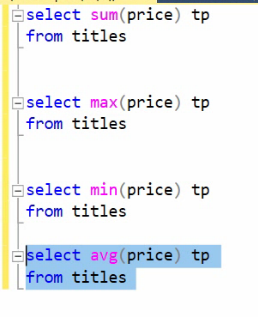
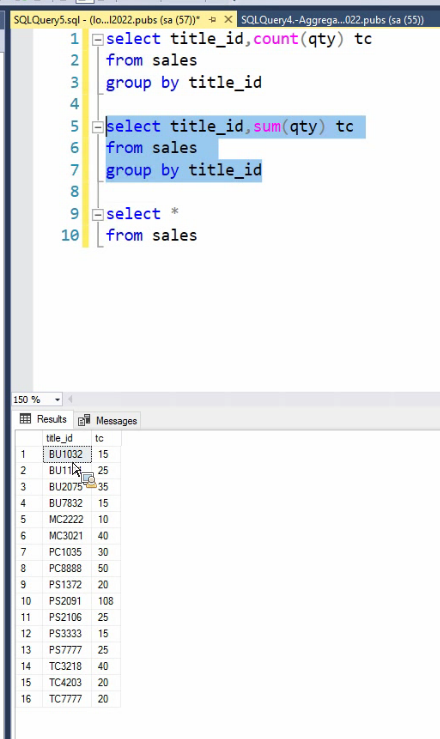
وقتی که SUM داره میگیره NULL ها رو تاثیر نمیده
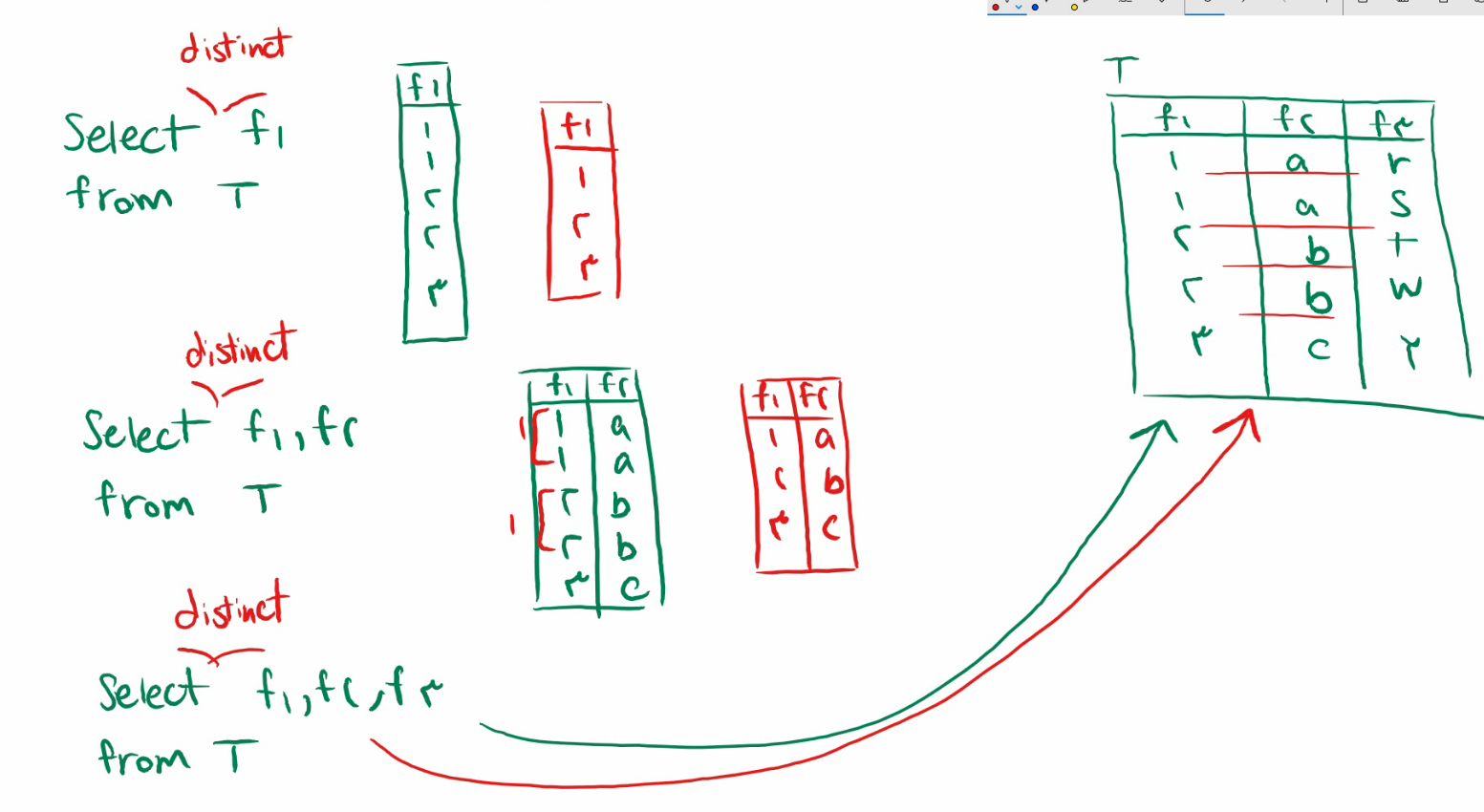
ترتیب بر اساس استاندارد Sql
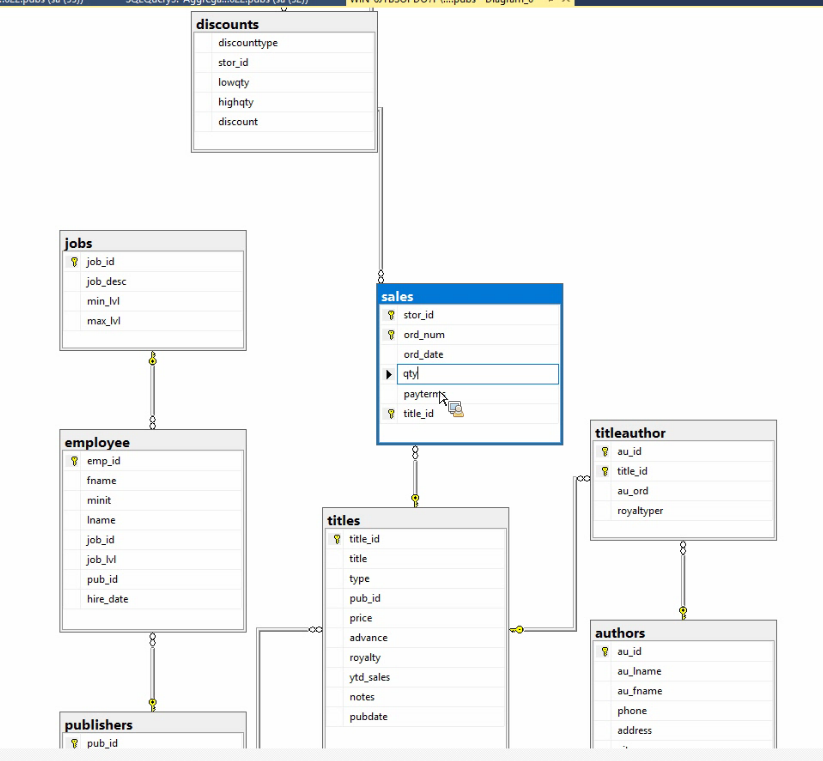
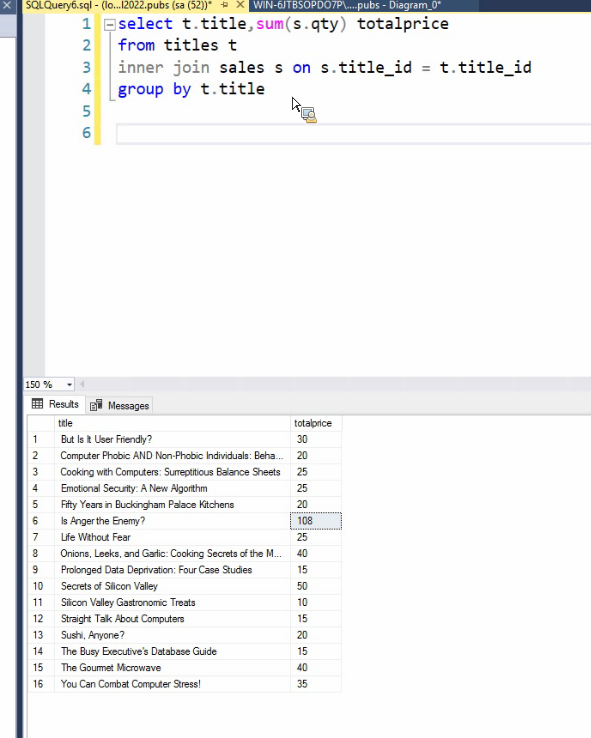
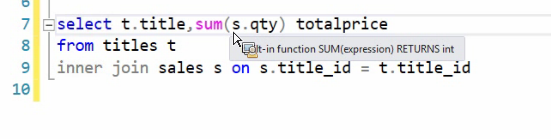
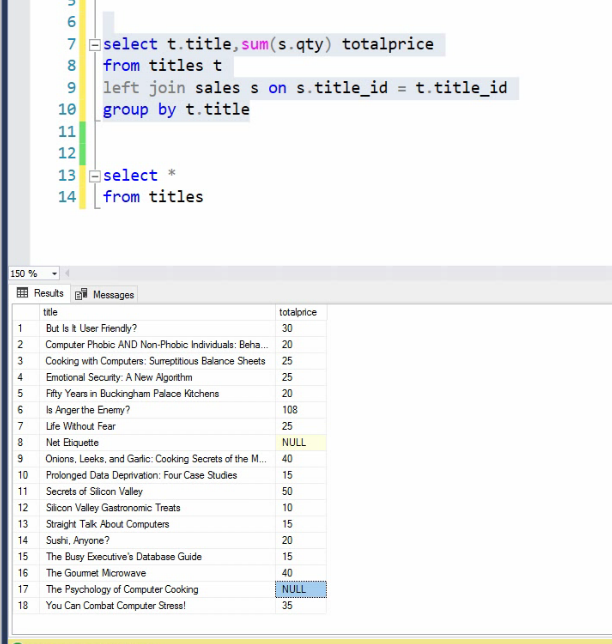
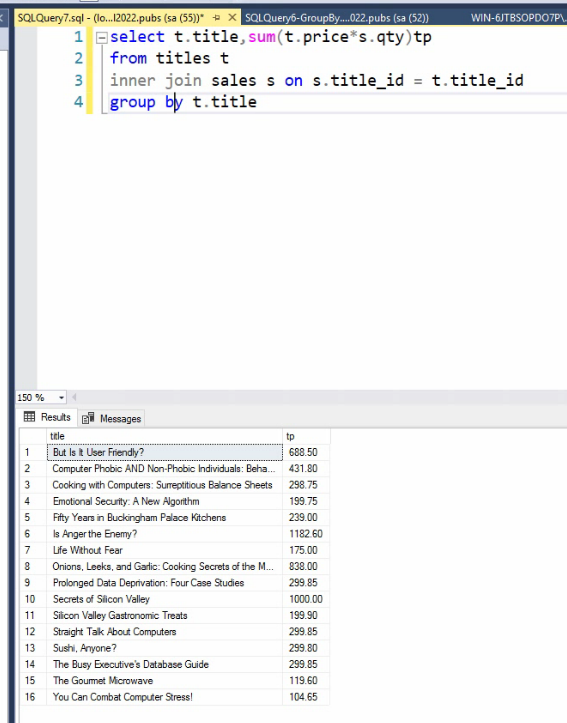
سرعت left , Right بیشتر است چون inner هر دو طرفه چک میکنه ولی left , right یک
طرف رو چک میکنن