خوب در جلسه قبلی با in , not داشتیم استفاده میکردیم ولی به جاش میتونیم از exist استفاده کنیم چون که سرعت بیشتری دارد و همون کار رو هم داره انجام میده
در موارد خاصی هم اصلا از in , not in نمیتونیم استفاده کنیم
نکته in , not سرعتش کمه چون operator هستن و exist ولی فانکشن هستش و سرعتش زیاده
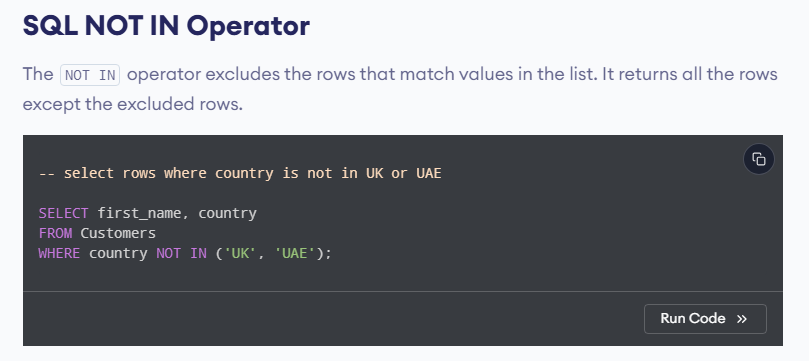
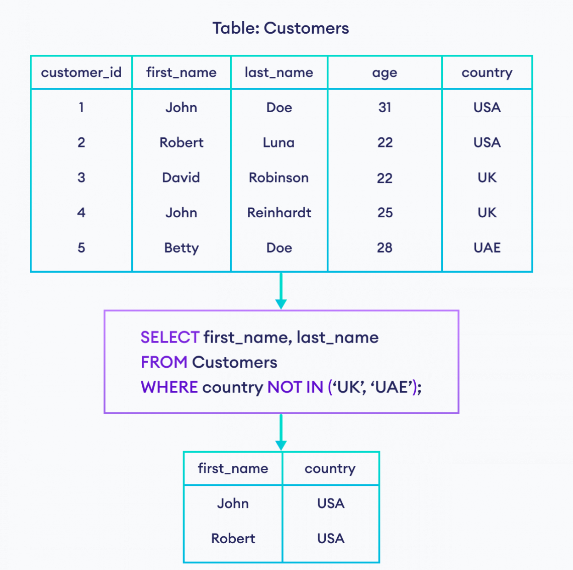
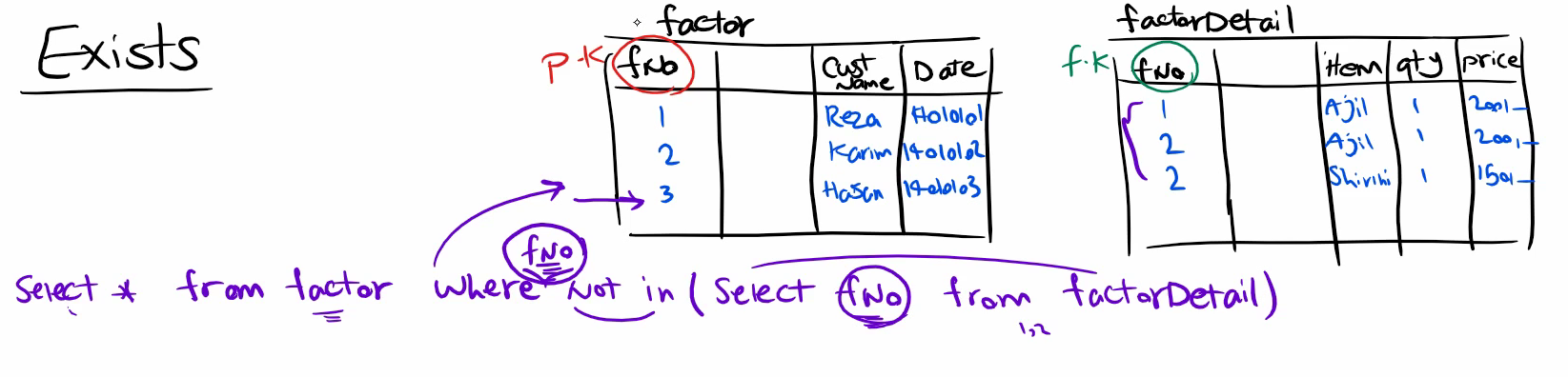
اینجا اومدیم برای این که رکورد شماره 3 رو بدست بیاریم اومدیم به صورت متناظر فیلد fno رو در دو تا select مقایسش رو انجام دادیم
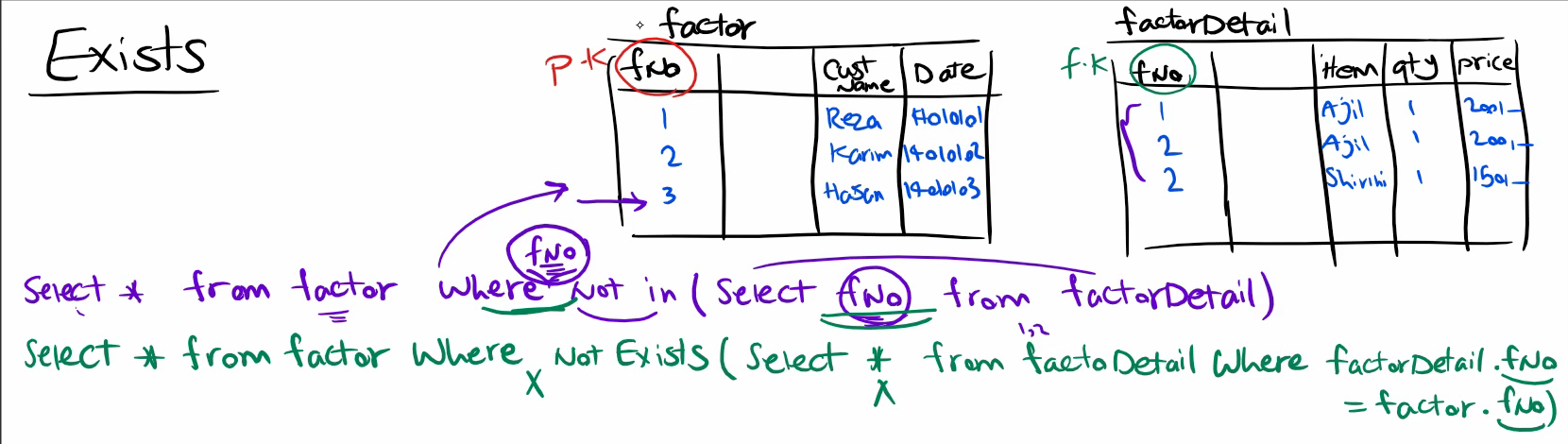
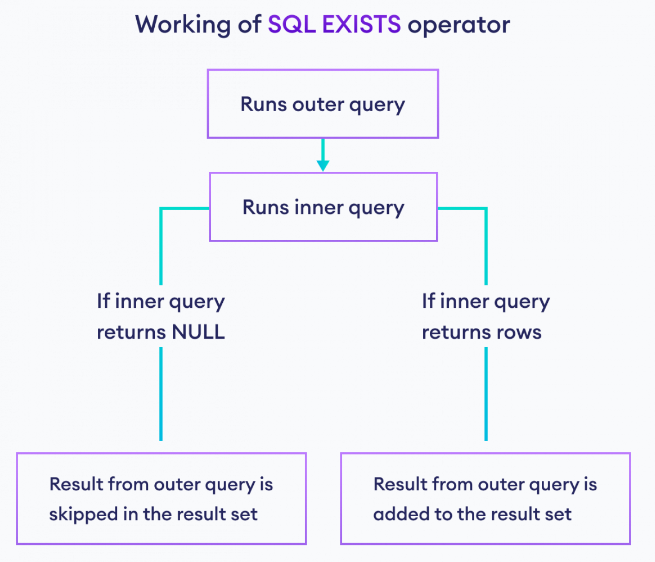
خوب برای exist وقتی که میخوایم به صورت متناظر ارتباط برقرار کنیم میایم در داخل select دومی با where این کار رو انجام میدیم و اونجا هم داریم میگیم که select کن اون رکورد هایی که هم در داخل factor detail هستند و هم در داخل factor و بعد در select خارجی گفتیم که به جز این هایی که بدست آوردی بقیه رو بیار
خوب حالا فرض کنید که بخوایم به طور مثال در سال جدید شماره فاکتورمون دوباره از صفر شروع بشه ولی چون pk هستش نمیشه ، برای همین باید یه تغییری در ساختار به وجود بیاریم
به همین دلیل میایم هم در factor و هم در factor detail میایم یه فیلد جدید به عنوان year درست میکنیم و میگیم که دیتاهایی که موجود هستند برای سال 1401 هستند
حالا اگر بخوایم از in , not استفاده کنیم نمیشه ، وقتی که p.k و f.k بیشتر از یک فیلد باشه ، نمیتونیم از in , not in استفاده کنیم ، اینجاست که باید از exist استفاده کنیم
نکته : اینجا وقتی که داخل پرانتز چون که where داریم و جوابش true باشه میره دیتا رو میاره و بعد exist توش چک میشه ولی اگر false باشه که هیچی
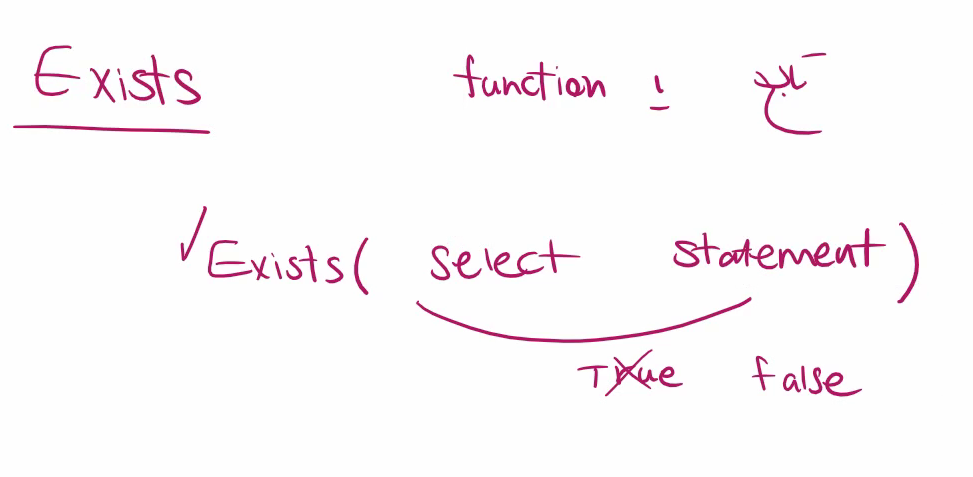

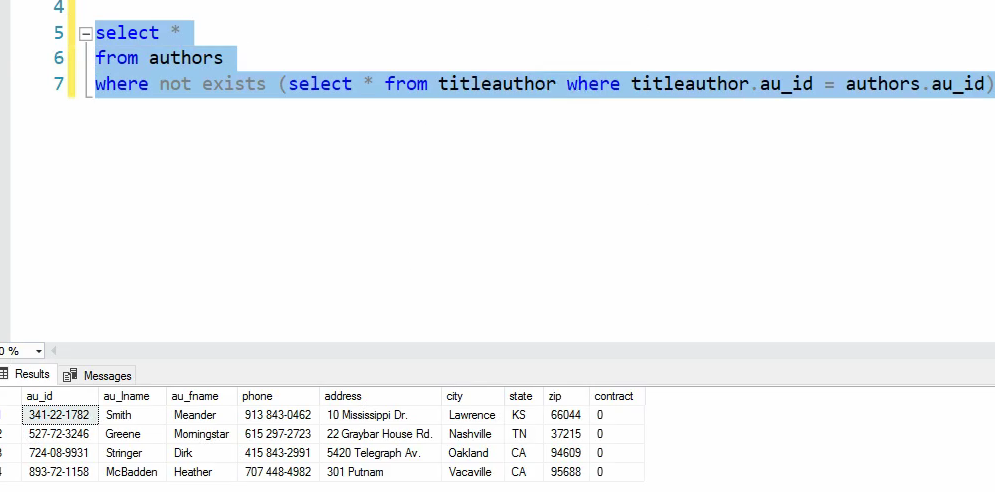
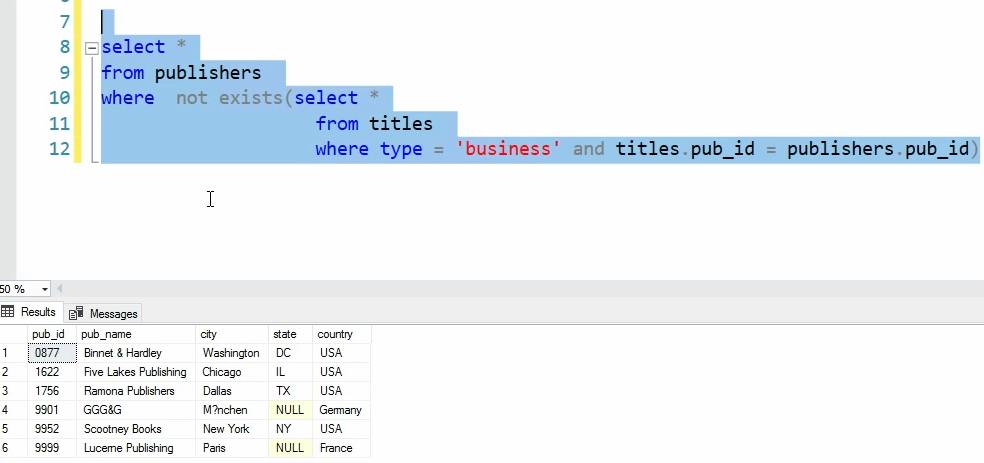
خوب حالا میخوایم همین رو تبدیل به not exist کنیم :
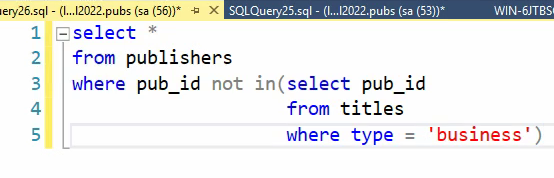
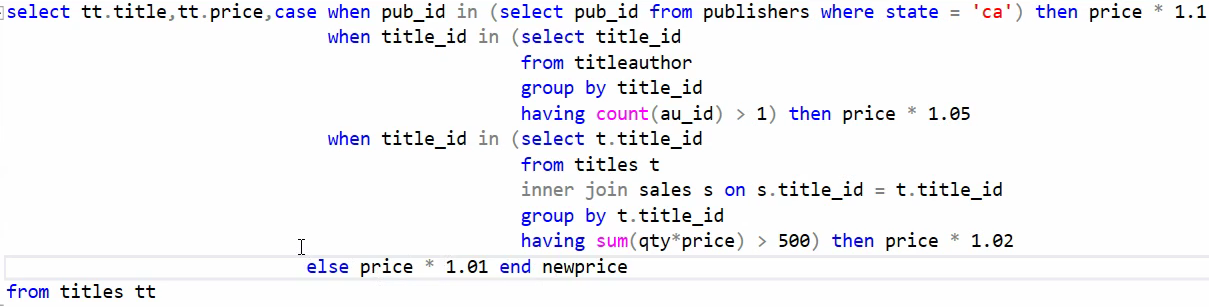
ناشرینی رو پیدا کنیم که هیچ کتاب بیزینسی ندارند
این رو میخوایم تبدیلش کنیم به not exist
تایم 43:03 از قسمت اول
تغییر دیتا بر اساس شرط با استفاده از case مثلا اون هایی که جنسیت زن هستش قبل از اسمشون نوشته شود خانم و اگر جنسیتشون آقا بود نوشته شود آقا این فیلتر نیست و تمام دیتا ها هستند و فقط یه سری تغییرات رو توش اعمال میکنیم
هر چیزی که در پرانتز هست optinal هستش
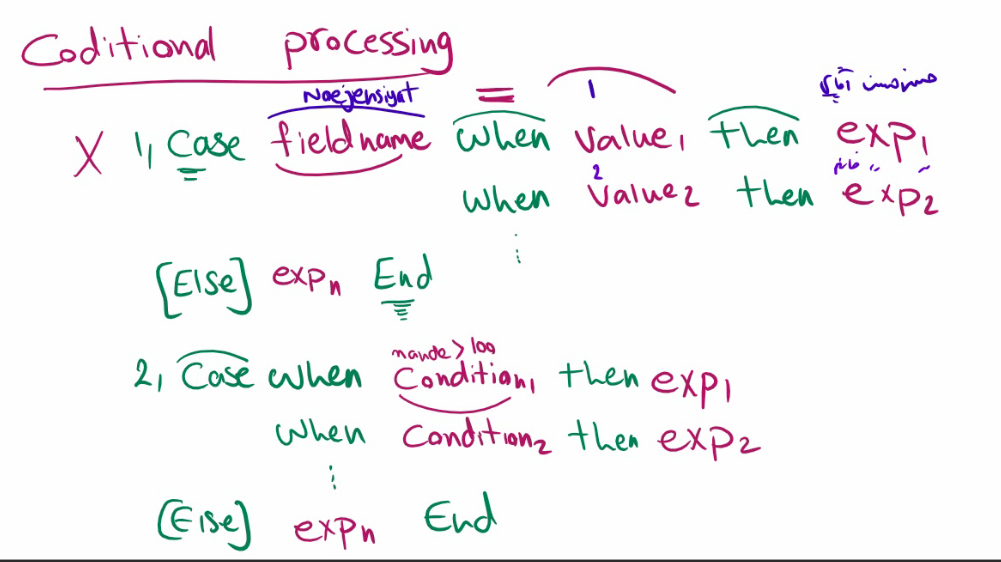
توی حالت اول فقط میتونیم از operator مساوی استفاده کنیم مثلا اگر نوع جنسیت آقا یا خانوم بود
ولی در پایینی میتونیم از operator های دیگه هم استفاده کرد مثل بزرگتر و کوچکتر و …
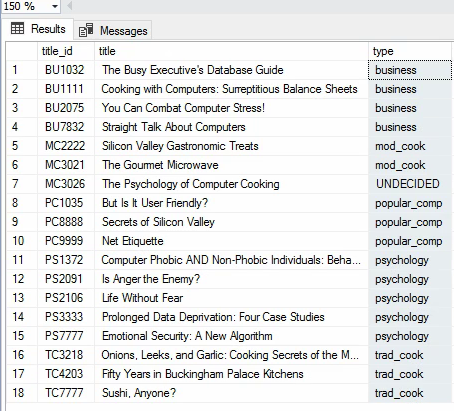
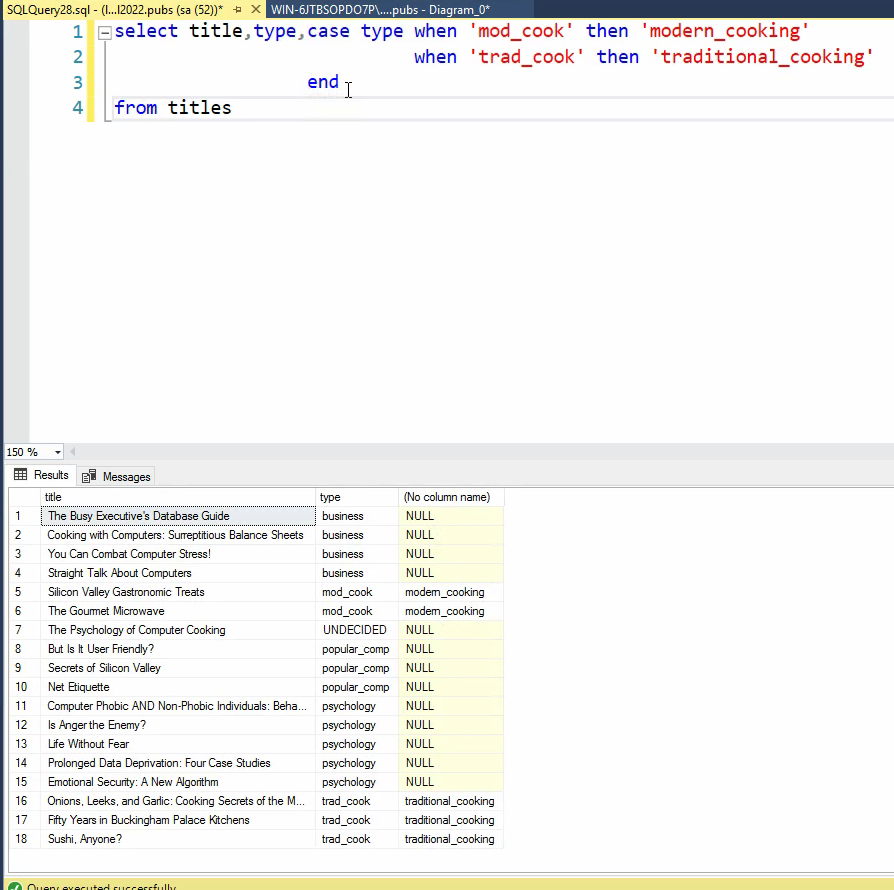 خوب اینجا برای این که اون no column name رو درست کنیم میایم از end new type استفاده میکنیم که اینطوری اون رو تبدیل میکنیم به new type و بعد داریم با Else میگیم که هر کدوم که mod cook و trad cook نبود بیا و اسم همون type رو بزار توی new type که خالی و null نباشه
خوب اینجا برای این که اون no column name رو درست کنیم میایم از end new type استفاده میکنیم که اینطوری اون رو تبدیل میکنیم به new type و بعد داریم با Else میگیم که هر کدوم که mod cook و trad cook نبود بیا و اسم همون type رو بزار توی new type که خالی و null نباشه
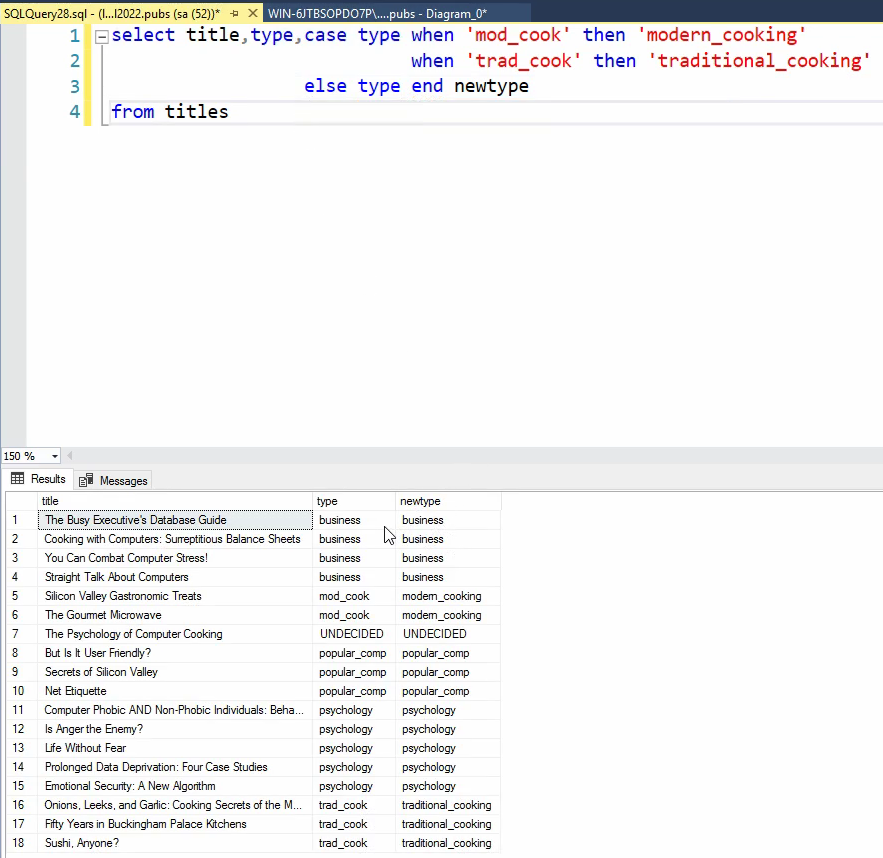
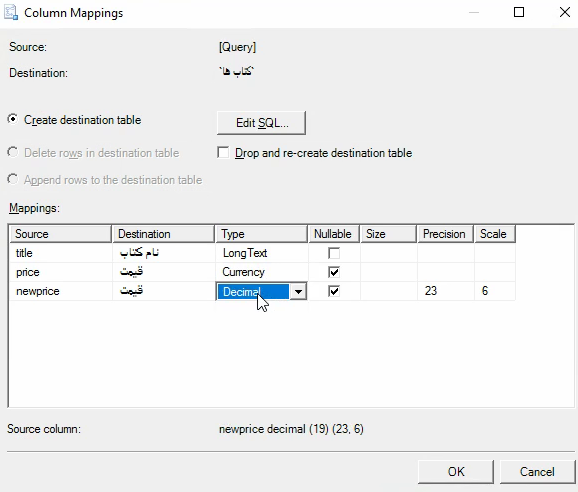
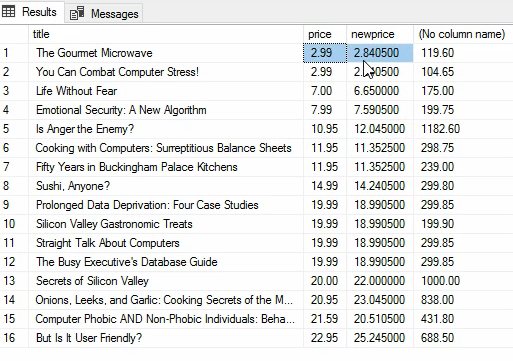
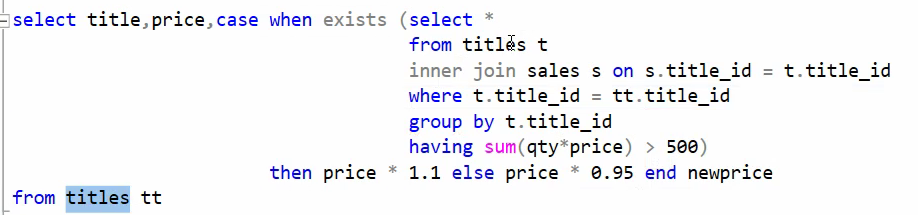
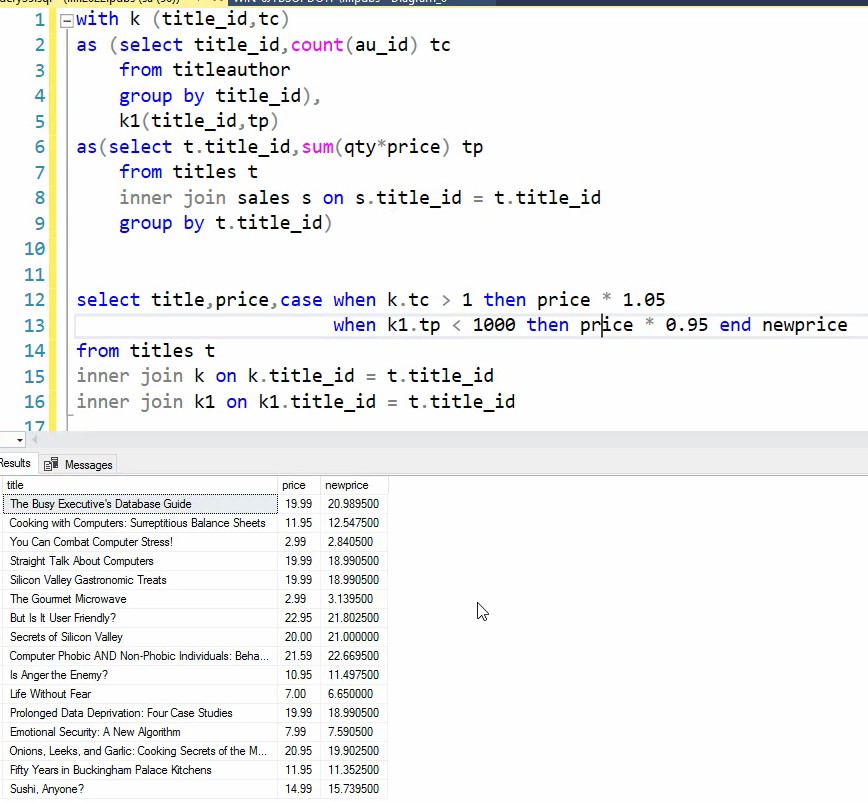
نام کتاب ، قیمت کتاب و قیمت جدید کتاب رو از فرمولی که گفته میشه بدست بیاریم : فرمول : اگر کتاب بیشتر از 20 دلار قیمت داشت 10 درصد افزایش قیمت در غیر این صورت 5 درصد کاهش قیمت
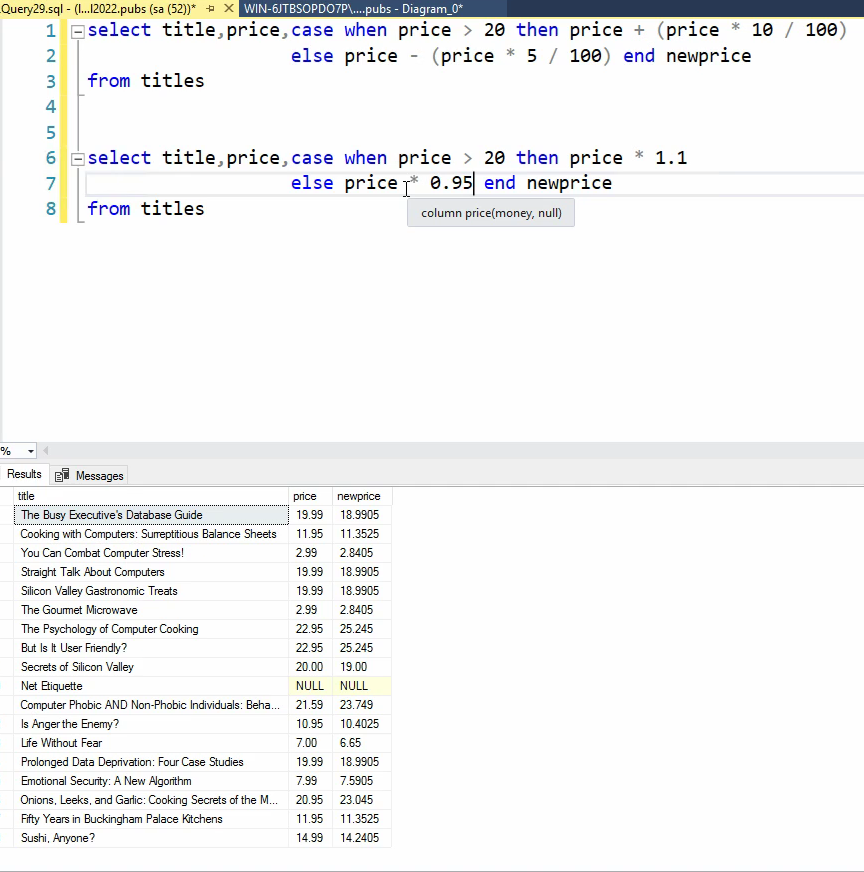
اگر قیمت رو 1 فرض کنیم و 5 درصد ازش کم کنیم میشه 0.95 برای همین در حالت دومی ضرب در 0.95 کردیم
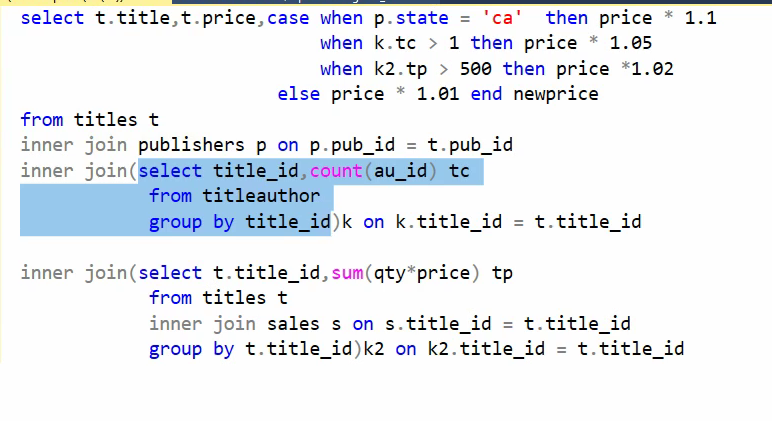
حالا میخوایم فرمول رو تغییر بدیم: اگر ناشر کتاب کایفرنیایی باشد 10 درصد افزایش قیمت ، در غیر این صورت 5 درصد کاهش قیمت :
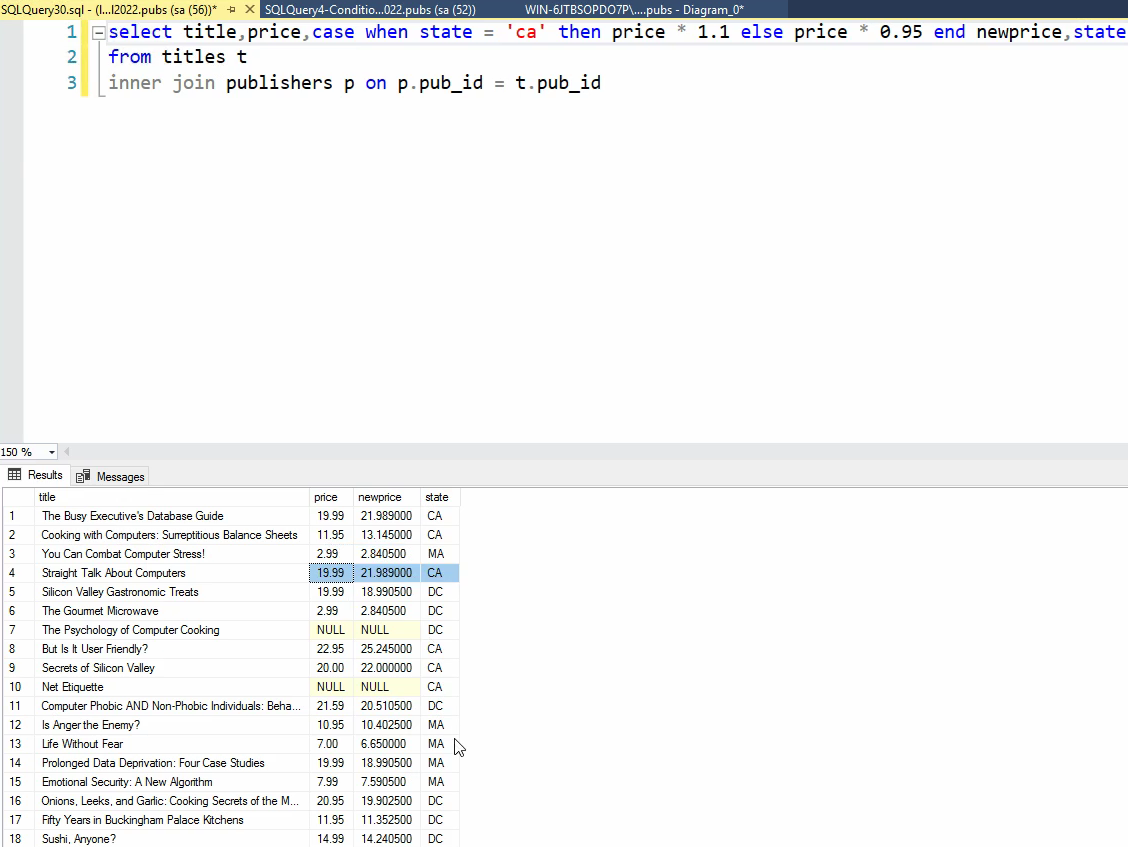
توی این مورد داریم اول برای رسیدن به state نویسنده ها بیایم و join بزنیم روی جدول publishers و بعد گفتیم که اگر state برابر باشه با CA اون فرمول رو بیا و حساب کن و بیا توی new price قرارش بده و برای چک کردن هم state هم اوردیم
در این مورد پایین میخوایم بریم اول pub id هایی که توی CA هستند رو بیاریم و ازش استفاده کنیم
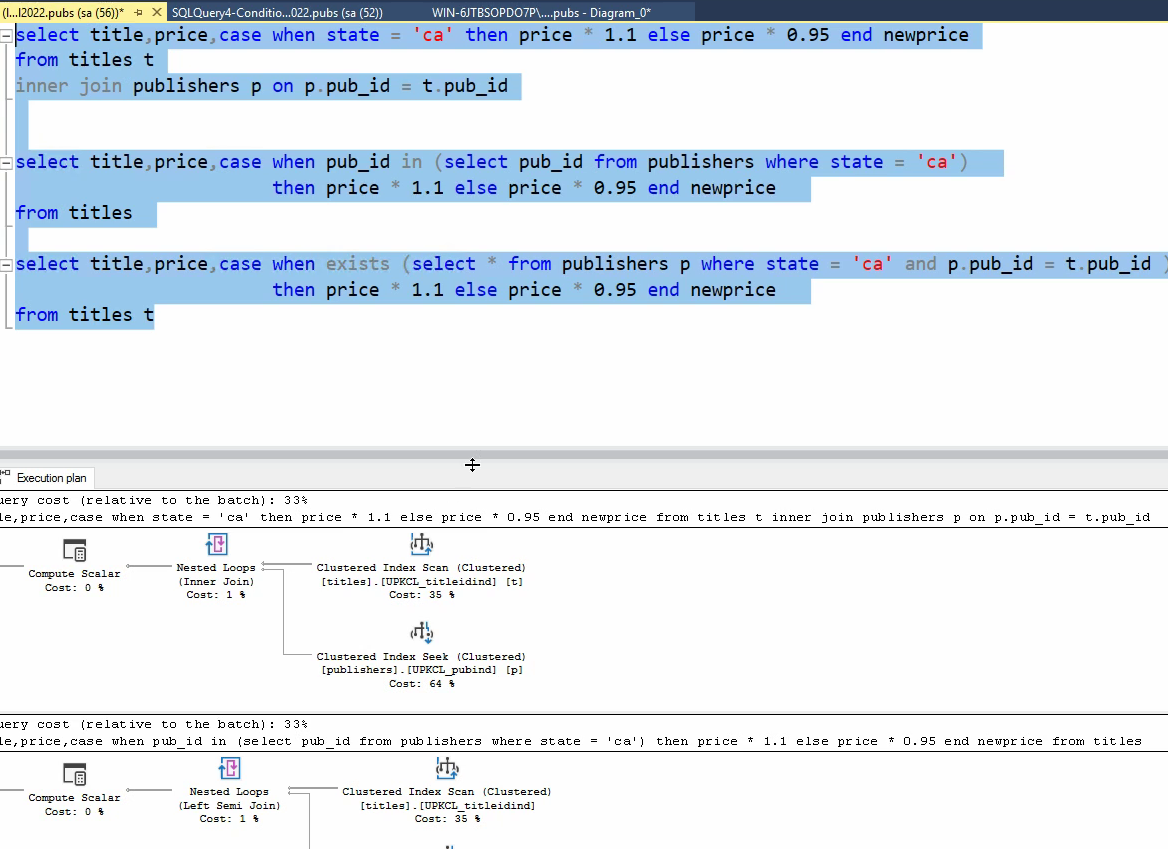
در اینجا تمامشون 33 درصد رو نشون میده ولی در دیتاهای بزرگ exist از همه بهتره
از تابع هایی که خودشون پیاده سازی کردن بیشتر استفاده کنیم
مثلا window function از 2008 به قبل وجود نداشت
یکی از قابلیت های oracle اینه که درخواست هایی که از کاربر ها میاد رو پیاده سازی میکنه مثلا تقویم شمسی داره
اتمام قسمت 1
فرمول جدید : اگر مبلغ فروش کتاب بیش از 500 دلار باشد 10 درصد افزایش قیمت در غیر این صورت 5 درصد کاهش قیمت

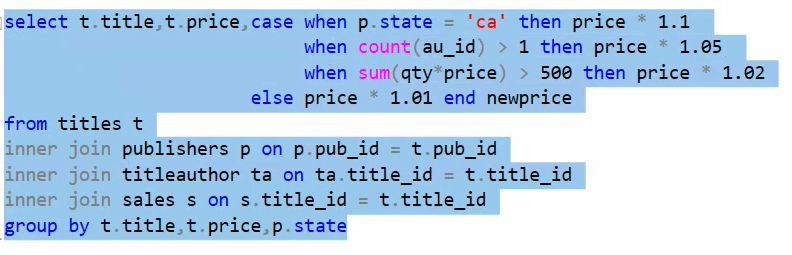
خوب حالا از یه راه دیگه میخوایم کار رو جلو ببریم :
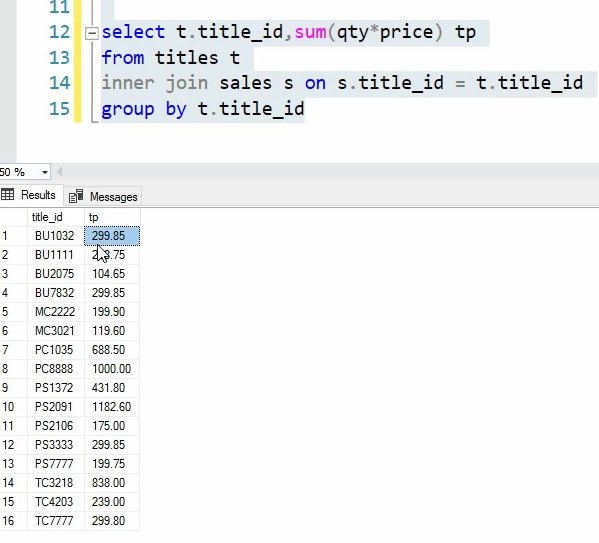 میایم titles رو با sales رو join میزنیم و بعد میایم group by اش میکنیم چون که از aggrigate function ها اومدیم استفاده کردیم
میایم titles رو با sales رو join میزنیم و بعد میایم group by اش میکنیم چون که از aggrigate function ها اومدیم استفاده کردیم
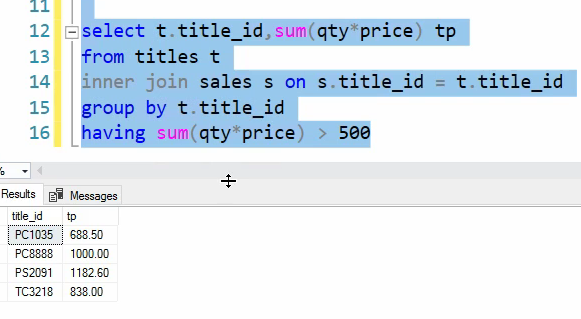
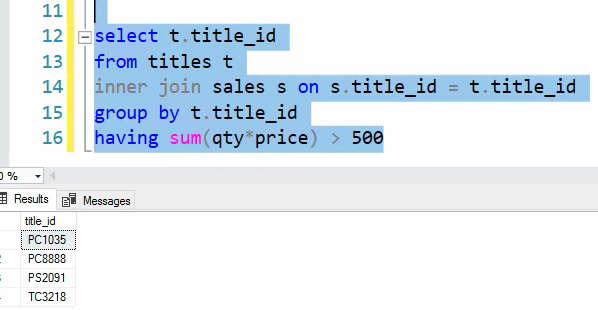
حالا میایم و اون هایی رو جدا میکنیم که مبلغ مجموع فروش شون بیشتر از 500 تا شده است :
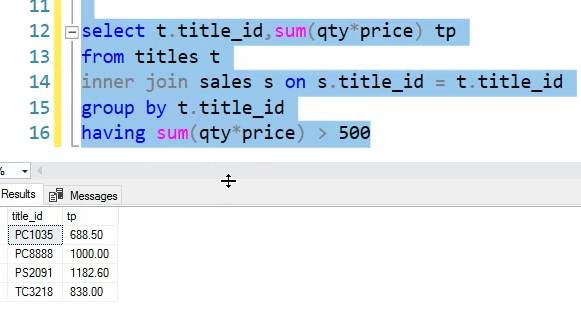
اینجا برای این که فقط همون هایی رو که میخوایم رو بیاریم دیگه اون tp رو پاک میکنیم
نکته : با shift tab پاک میکنه و با Tab میبره جلو و چند تایی هم میخواستیم با alt این کار رو میکنیم
حالا اونی که اون بالا درست کردیم رو میاریم میزاریم داخل این in که در این کوئری تعریف کردیم

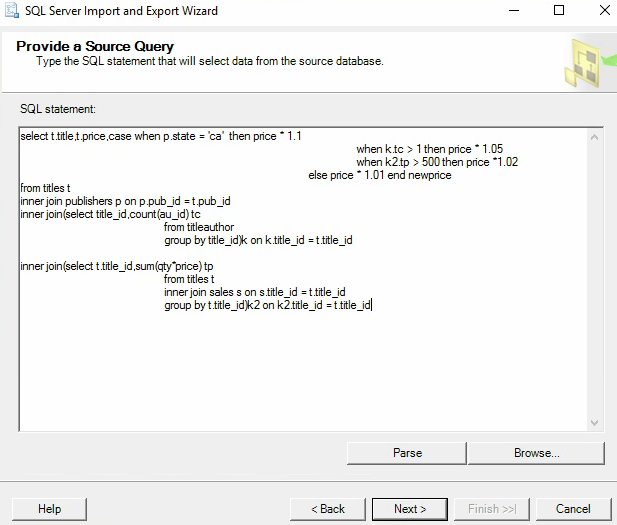
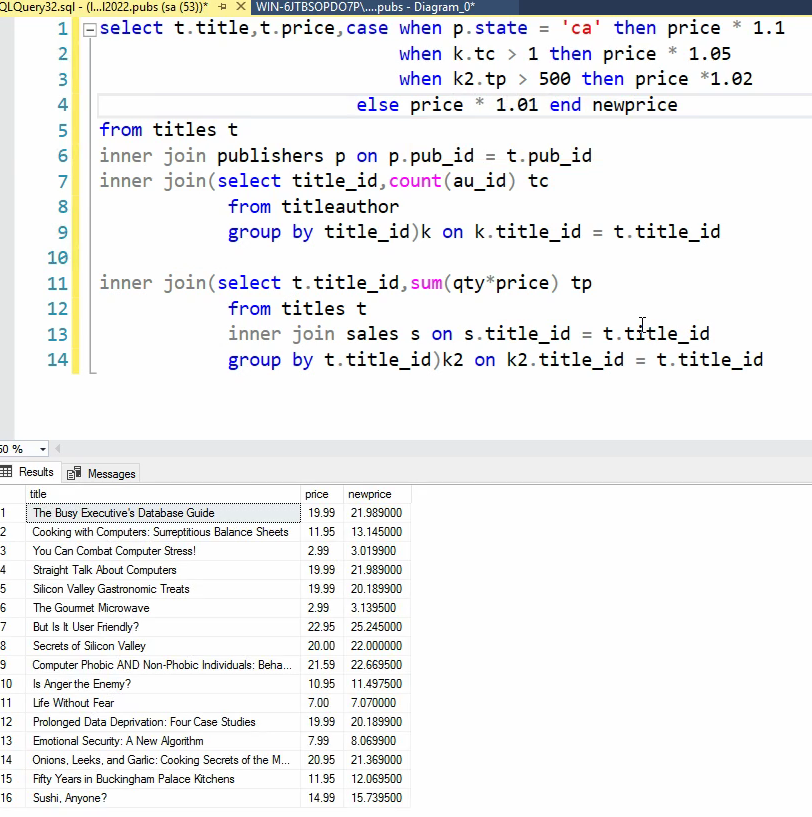
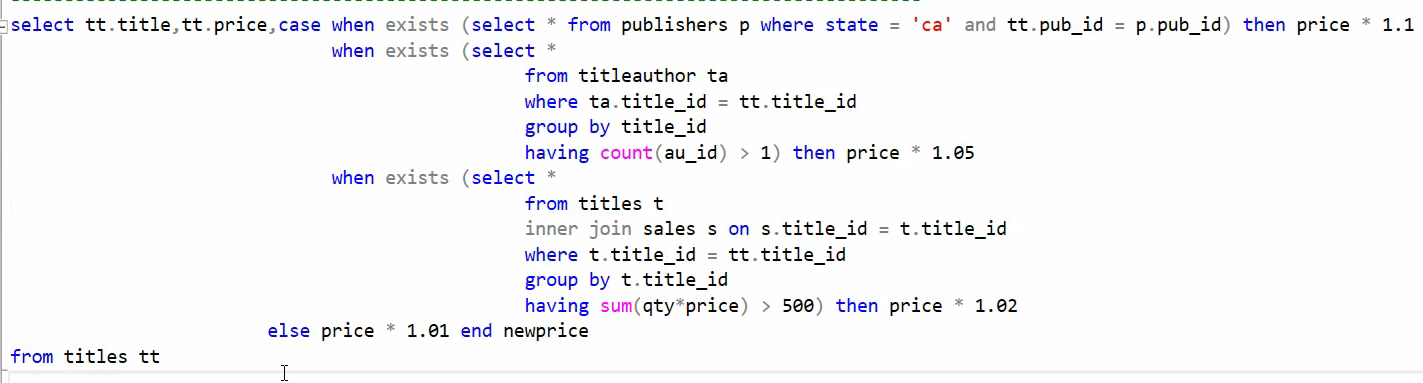
فرمول جدید : اگر ناشر کتاب CA بود 10 درصد افزایش قیمت در غیر این صورت اگر کتاب بیشتر از یک نویسنده داشت 5 درصد افزایش قیمت در غیر این صورت اگر مبلغ فروش کتاب بیشتر از 500 دلار داشت 2 درصد افزایش قیمت و در غیر این صورت ها 1 درصد افزایش قیمت
رتبه بندی به لحاظ سرعت اینطوریه که اول اونی که Exist داره و بعد اونی که in داره و بعد هم اونی که join زدیم و در آخر اونی که کمترین سرعت رو داره اونیه که اولیه و از drived table اومدیم استفاده کردیم و سرعتش از همه کمتره و به خاطر اینه که کل دیتا رو در هر مرحله اوردیم
نکته اگر موردی باشه که هر سه شرط که در فرمول بود رو داشت فقط یک بار روش اعمال میشه در case when و اونی روش اعمال میشه که بالاتر هستش و شرایطش رو داره
اگر بخوایم دو تا شرط روش اعمال بشه باید توی case when بیایم و از and استفاده کنیم یا از or استفاده کنیم
اتمام قسمت دوم

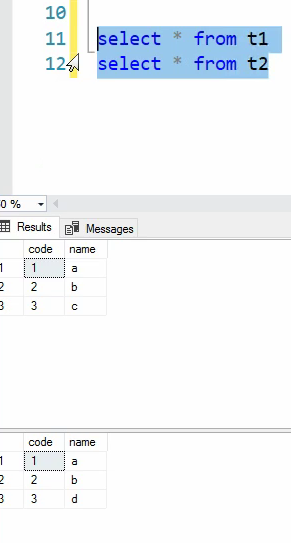
در اینجا mars اتفاق افتاده که میشه multiple active result set
اگر بخوایم دیتا ها در امتداد هم نمایش داده شوند
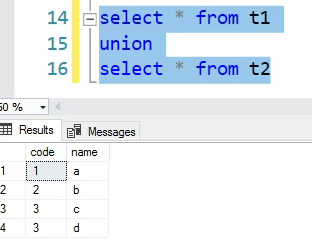
خوب union میاد اجتماع دیتا ها رو نشون میده ولی اشتراکاتات رو حذف میکنه
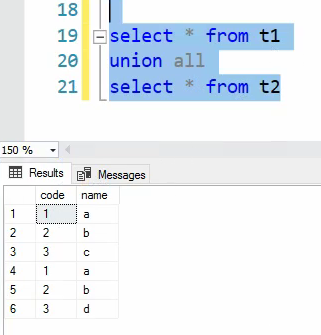
خوب union all همه رو میاره
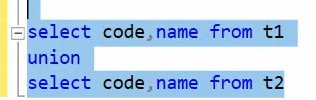
خوب باید ستون هاشون باید تعدادشون باید با هم یکی باشند :
خوب اینجا هم به این شکل نمیشه :
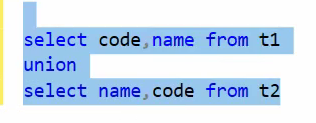
نکته : هم data type و هم تعداد ستون ها باید با هم یکسان باشند و ترتیبشون هم درست باشه
خوب یه نکته ی دیگه اینه در خروجی دیتایی که بدست میاد data type هاش رو از روی کوئری اول میگیره
منظور select اولی هستش یعنی به طور مثال code از جنس int باشه و select بعدی از نوع small int باشه کوئریمون درسته ولی اگر برعکس باشه اشتباهه
خوب intersect میاد اشتراکات رو میده
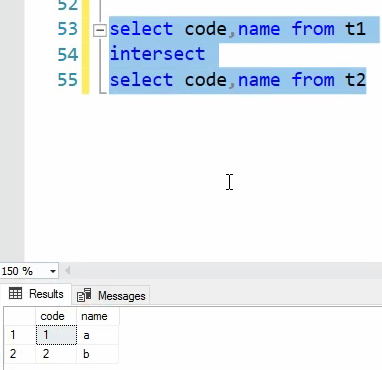
خوب مورد بعدی except که میشه تفاضل یعنی اون چیزهایی که در t1 هست ولی در t2 نیست
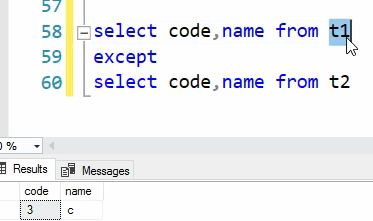
در validation check به کار میاید
نوشتن Validation check برای تست

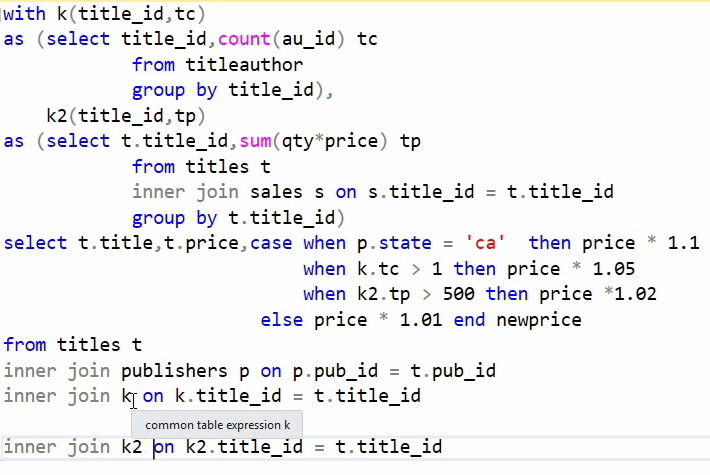
نکته with هم داره

حالا اگر بخوایم CTE استفاده کنیم :
 این قابلیت از 2012 به بعد اضافه شده است
این قابلیت از 2012 به بعد اضافه شده است
این برای فرمول جدید است که با cte نوشته شده است ، این روش با drived table ها تفاوتی نداره
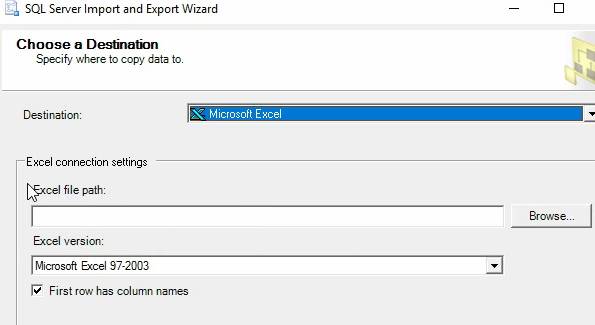
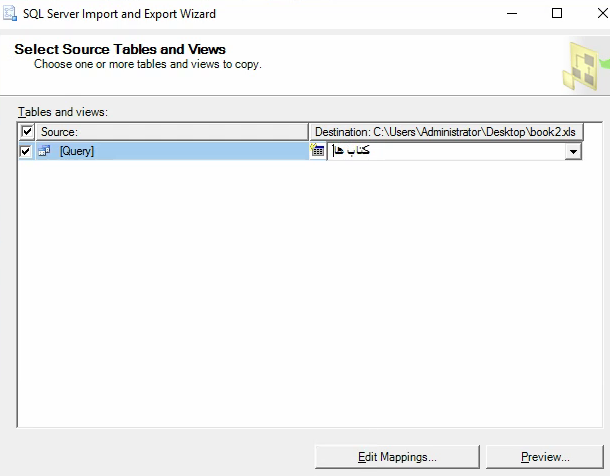
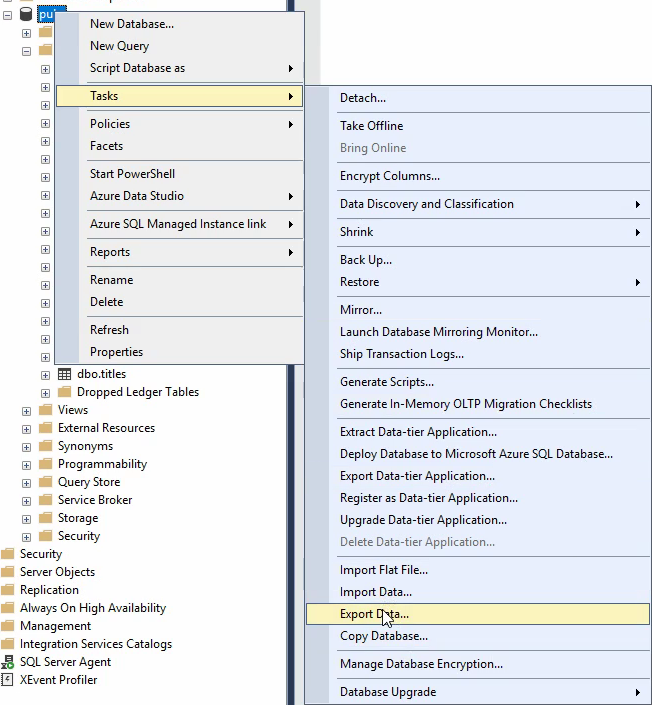
قسمت سوم 1:03:00 شروع آموزش export گرفتن از excel
اگر بخوایم دیتایی رو کپی کنیم میایم میزنیم رو copy with headers و بعد میریزیم توی excel
اگر بخوایم export کنیم دیتا رو بهتره که از طریق خوده Sql اقدام کنیم چون اون خودش میتونه بیاد و دیتا ها رو توی چند تا sheet بیاریم
خوب حالا اگر بخوایم یه دیتایی رو ببریم توی چند ورژن پایین تر از sql که الان هست میتونیم از این روش استفاده کنیم که بیایم دیتا رو از اینجا اول export بگیریم و بعد بریم در اون sql ورژن پایین تر import کنیم و دیتا ها رو انتقال بدیم چون به هیچ طریقی اون ورژن پایین تر نمیتونه بک آپ و دیتا رو بخونه
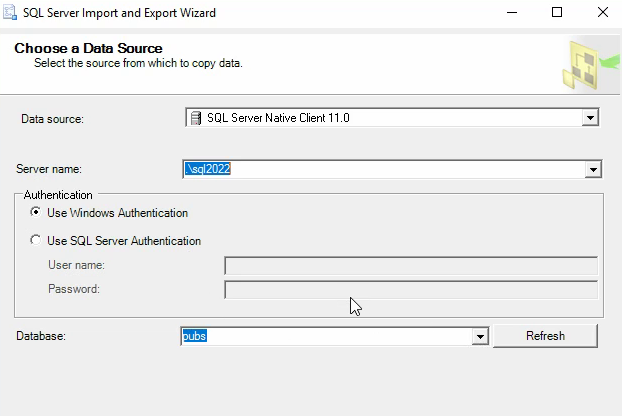
یه فرمتی داریم به اسم flat file destination که میشه همون csv